【三分钟搞懂CPU, GPU, FPGA计算能力】
背景
现在AI火热,带动了异构计算的发展,让GPU, FPGA这类加速芯片从辅助设备逐步进入了主流计算设备的行列,开始挑战传统CPU的绝对统治地位,那么我们为什么经常听说GPU, FPGA相对于CPU计算能力要强的多,原因是为什么呢?
芯片设计
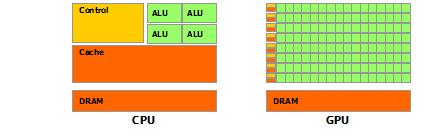
CPU在芯片设计上,绝大部分空间其实并不属于ALU(算数逻辑单元)。CPU作为通用处理器,除了满足计算要求,为了更好的响应人机交互的应用,它要能处理复杂的条件和分支,以及任务之间的同步协调,所以芯片上需要很多空间来实现分支预测与优化(control), 保存各种状态(cache)以降低任务切换时的延时。
GPU则走了一个极端,它在芯片设计上突出计算输出最大化,几乎将所有的空间都给了ALU,所以对于AI,HPC,图形渲染这样简单粗暴的浮点矩阵运算,GPU的优势肯定就非常明显了。
峰值浮点
CPU
一颗E5 2680 V4, 14核心,3G左右频率,那么其峰值浮点能力为3X14x32(32是V4处理器支持SIMD的速算因子,即一个时钟周期内能做32次浮点计算)= 1.34Tflops.
Intel V3 Haswell架构处理器,支持AVX256, 即每个时钟周期能做(256/32)x2=16次单精度浮点,x2是因为每个时钟CPU能同时发出一次加法和一次乘法指令。
Intel V4 Broadwell支持FMA(融合乘加)指令,即a*b+c, 所以再x2=32。
Intel V5 Skylake支持AVX512, 所以再x2=64。
GPU
比如是Tesla P100, 3584个cuda core, 核心频率大概是1.5G左右,那么其峰值浮点能力为3584×1.5×2(2是GPU的FMA速算因子)= 10Tflops左右,即使是便宜多的Tesla P4, 峰值浮点也能到5Tflops。
FPGA
比如xilinx的ultrascale, 我查了下,它有1,440 个DSP based加法器,频率为 0.5G,还有6,743个Logic based的加法器,频率为0.6G,1440×0.5+6743×0.6=4.5Tflops。
价格上看, 大概可以认为,E5 2680 V4 = Tesla P4 = xilinx ultrascale,所以很清楚了。。
转载请注明:徐自远的乱七八糟小站 » 【三分钟搞懂CPU, GPU, FPGA计算能力】



