有人说,树莓派 + Intel Movidius NCS神经计算棒的组合将是2018年最佳的AI学习平台,你怎么看?
笔者先来说说自己的看法吧,前段时间玩了Up Squared Board + Movidius NCS神经计算棒的组合(其实私下我比较习惯叫它神经棒或者棒子,简洁、顺口),说实话,体验下来还不错,但也是因为没有太深入的缘故,所以部分不足之处当时未发现或者直接忽略了,这次趁着体验树莓派3B与神经计算棒组合的机会,来更深入的分享下这玩意,顺便也补充下之前未提到的NCS存在的一些缺点。当然,本文也将在结束的时候重点对比下树莓派3B与神经计算棒的组合以及Up Squared Board与神经计算棒的组合各自的优缺点,是不是对结果很感兴趣?
为便于大伙更深入的了解Movidius神经计算棒,在开始本文之前,笔者先强调两件重要的事。
首先就是为何我要使用Movidius NCS神经计算棒?
用于推理加速?那各大巨头的云服务岂不是更靠谱?这里就要扯出一个数据,1ms,这是一个关键的参数,这是人的反应时间,这是今后AI、5G通信允许的标准延迟时间。有人说,通过云端的推理不更好?首先你要明白一个道理,云端传输靠联网,在保证网络顺畅的时候你还要考虑到其它问题,比如距离,一辆自动驾驶的汽车在上海,而如果云端服务器在北京甚至更远,大概可以算一下,以光速传播的讯号从终端到云端再返回终端一个来回至少也需要20ms,假设你的汽车以120公里每小时的速度前行,从检测到判断通过云端的结果使你比本地处理需要更久的时间才能停下(例子是以理想状态,同志们不用过分解读),NCS就是将这种推理工作带到了本地终端处理,而不需要通过云端,降低延迟,这也是即便云端推理再强悍,边缘计算也有其独特的优势。
第二个事,NCS不适合训练,因为在性能上还是无法跟目前强大的GPU/ASIC等相比,只适用于现有的、或者你已经开发好、训练好、并且编译完成的模型,进行推理加速的功能。NCS内部的主要器件即为视觉处理单元VPU,特点可以参考GPU,其实强调的也就是它并行处理图像的能力,也因此,你也可以以两根棒子,三根棒子,甚至更多的棒子组合做加速推理,这跟堆GPU还是挺像的,所以其实它的应用范围已经限定的非常明确,就是那些需要处理器大量视频或者图像数据的如无人机上的拍摄/智能避障、智能监控设备、机器视觉等产品,而它的优势在于处理这些东西的时候能保证较低的功耗,非常适合移动设备,这也是那些性能虽强悍,但功耗也极大的GPU、ASIC等芯片无法触及的领域。
明白这两点后,我们就可以愉快的往下走了。
树莓派3B+Movidius NCS组合
先谈下目前树莓派最新版3B与NCS的组合,如果只看表面,大家会觉得很“般配”,一个小巧、用的人多、生态圈广的Linux计算机平台,一个目前人工智能领域中非常火的便携式深度学习推理加速棒,组合到一起很完美?
但真正搭配在一起使用时你会发现有不少问题,甚至有些问题目前还无解。
首先从物理层面来说,连接上神经棒后的树莓派的其它USB接口被“占用”,这个指空间占用(见下图)。了解树莓派的都知道,树莓派3B的4个USB HOST接口由于是通过USB HUB芯片扩展出来的,而且为了迎合小巧的机身,所以很自然都集中在一起分布,原本没什么,但是在你插上Movidius NCS后你会发现一件很糟糕的事情,其它几个USB接口基本被挡着了。

所以如果使用树莓派3B+Movidius NCS的组合,你首先要学会插上神经棒的正确姿势,如下图所示,将神经棒插在上层的USB接口的话,你还能勉强使用下边两个没有太多扩展外型的USB线缆,但也仅此而已,最好的方式还是要配一个USB HUB集线器,为什么?因为后面实际学习的时候你会发现不少案例会需要两根、甚至更多神经棒的组合(为什么需要两根?将在下文实际运行demo测试时解释)。

当然,这以上不算什么麻烦事,喜欢玩树莓派的这种小事都能克服,下面使用过程中出现的问题才是重点。
这次测试主要的硬件平台以及软件开发包如下:
当你一切准备就绪,将神经计算棒连接上树莓派3B准备大干一场的时候,问题来了。官方提供了的例程主要基于Caffe以及TensorFlow深度学习框架,然而,目前树莓派是无法支持最新版的TensorFlow,所以现在只能使用基于Caffe的神经网络模型。其实笔者也试过爱板网之前提到过的香蕉派Zero上安装基于ARMv7l的低版本TensorFlow,安装虽然成功了,但是在神经棒的例程中还是无法支持,可能还是因为需要最新版的TensorFlow支持。所以,目前来说,只使用用树莓派的话需要暂时放下TensorFlow,比较遗憾。
好在还有不少基于其它深度学习框架如caffe的应用案例可以参考,不至于一无是处,而且作为入门学习的话,首先搞懂一个就非常不错了,等你学习完Caffe,说不定到时树莓派能完美支持TensorFlow了,毕竟其超广泛的生态圈有着无与伦比的号召力及优势。

还有一点需要特别注意,如果搭载Movidius NCS神经棒后,树莓派最好使用额外的适配器供电,任性使用电脑上的USB口供电可能导致供电不足而出现问题。
连接上神经棒后可以通过ncappzoo文件夹下的hello_ncs_py程序查看神经计算棒与树莓派是否已经成功连接。
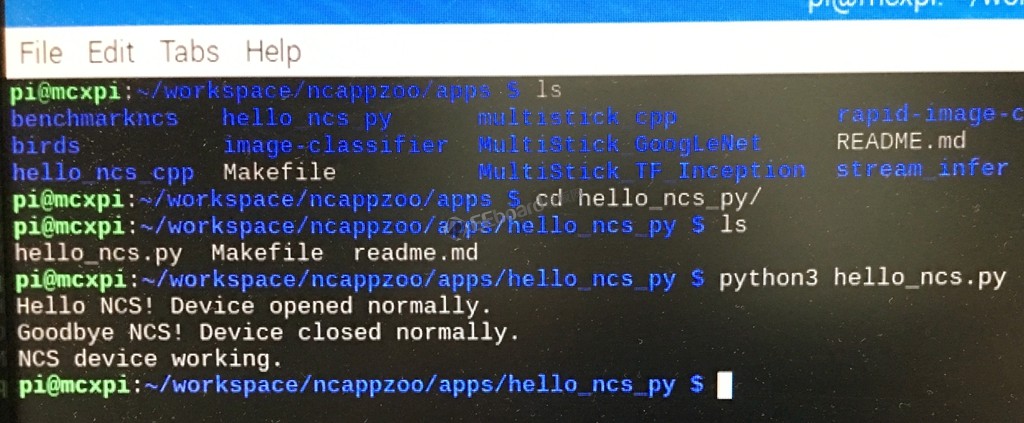
另外,如果只使用树莓派一个工具,编译也是非常头疼的问题,限制于ARM架构在性能上无法与x86机器相比,所以ARM架构的单板计算机基本都有这个通病,除了慢外,树莓派上的1GB内存也是头疼的地方,在编译的时候有时会直接提示内存不足的错误。
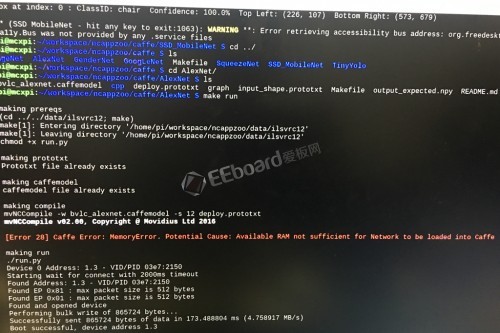
跨过这些坎后,恭喜你,已经迈入了真正可以接触、了解深度学习的大门了。先演示一个在树莓派上通过神经计算棒进行图像识别的demo,可以明显的看到,图像识别的速度应该不输于人脑的反应时间,而且这个demo可以叠加使用神经计算棒来加快图像识别的速度。
接下来用上两根神经计算棒,用于识别图片中的鸟是什么鸟。

说下为何要两根棒子,一根棒子是用于识别出图片中的鸟在什么位置,另一根是用于识别鸟是什么鸟。其中用到了深度学习框架Caffe中的两个模型TinyYolo以及GoogleNet,首先通过TinyYolo以及GoogleNet将图片中的鸟用框标识出来,然后再通过GooleNet模型实现识别。
车辆识别案例,同样是通过TinyYolo以及GoogleNet两个模型实现的。
小结
试过了Up Squared Board与Movdius神经计算棒的组合,又玩了树莓派3B+神经计算棒的组合,个人还是有些看法的。

- Up Squared Board与Movdius神经计算棒组合(评测)
优点:1,支持原生态Ubuntu16.04版本系统,官方SDK可以无缝使用,支持Caffe,支持TensorFlow;2,USB3.0接口,从终端到Movidius神经计算棒传输速度更快;3,USB接口不集中在一起布局,支持同时使用两根Movidius神经计算棒不需要额外的USB Hub接口。
缺点:1,价格老贵了;2,默认没有WiFi模块,使用无线网需要额外购买mini PCIe的WiFi模块或者USB接口的WiFi模块;3,有点大材小用。
- 树莓派3B与Movdius神经计算棒组合
优点:1,虽然称不上最佳AI学习平台,但绝对是最具性价比的AI入门组合;2,树莓派作为业内生态圈最广的一个开源计算机平台,配套的硬件外设、软件工具都极为丰富,容易上手;3,板载WiFi模块,再通过像VNC这类软件工具可以实现最精简、最轻便的使用。
缺点:1,不支持最新的TensorFlow;2,配置略低,不适合在树莓派上完成编译工作;3,4个USB接口无法有效利用
- Movidius神经计算棒
优点:1,第一款真正意义上用于离线AI入门学习的套件,让更多的工程师或者电子爱好者进入深度学习的大门;2,单个神经棒适配能力强,适用于任何可以安装Ubuntu16.04系统x86架构电脑,即便是没有Up Board,树莓派,你也可以使用PC+虚拟机+Ubuntu系统来使用。
缺点:1,不能用于训练,性能决定了只适合推理;2,发热,这是真实存在但不注意又容易忽略的问题,意识到发热大的时候笔者也同时想明白为什么Movidius NCS使用铝制外壳,那可不仅仅是为了什么高大上,做工,更多的应该是为了散热,夏天使用或许要加上散热措施。
随着AI的概念被应用到各行各业,离线AI推理的工作优势也凸显出来,甚至说有些领域通过边缘AI推理可以实现比通过云端推理得到更靠谱的结果,比如无人机视觉避障。目前来说,不支持最新版TensorFlow的树莓派+Movidius NCS神经计算棒的组合显然还无法成为最佳的AI学习平台,但绝对是最具性价比的AI入门学习/开发组合,而且以树莓派在江湖中的地位,相信支持最新版Tensorflow也是早晚的事情。
如果有想法、感兴趣,想先人一步进入将来最具前景的深度学习大门,可以访问爱板网官方商城购买:
笔者有幸参加了2月3日慕客信CEO Kevin亲自指导的AI培训,文章GitHub中SDK内容来源于该培训。感谢慕客信提供。
目前在树莓派上能实现的基本都是基于Caffe深度学习框架的一些应用案例,而TensorFlow的一些案例只能表示遗憾。当然,这些遗憾也不是没法办解决,你可以通过自己的电脑+虚拟机+Ubuntu系统去实现,这里就不再另说明。
懒得看上文啰嗦桥段的可以直接看最后的小结。



