在U盘中运行深度神经网络?详解英特尔Movidius神经元计算棒
人工智能的热潮正在席卷各个行业,如何让各式各样的设备都智能化已成为研究热点。机器学习中最流行的深度学习通常需要较大的计算量,因此服务器加上高性能显卡成为最常见的选择。
不过,此类组合平台在功耗和体积上都存在较大限制,无法使用在终端设备或者物联网设备,如监控摄像头、无人机等。针对这种情况,比较可行的方法是将数据通过网络发送到云端服务器,但这会耗费大量网络流量和带宽,并且很难保证计算的实时性。另外一个方法是使用专用芯片或FPGA加速,在性能和功耗方面取得折中,但这种方法的开发门槛较高且周期长,部署的时候需要设计定制化的电路板和供电系统。
针对上述问题,英特尔给出了自己的方案——英特尔Movidius™神经元计算棒!
一个小小的计算棒如何能加速客户端计算?让我们一起走进Movidius™神经元计算棒,了解其基本结构、实用工具和编程方法,让大家能够更好地了解其在计算、开发、部署方面的特性。


Movidius神经网络加速芯片
Movidius神经网络加速芯片是整个技术的核心。Movidius提供代号为Myraid的VPU(Video Processing Units),当前正在推广是Myraid2 MA2X5X系列,其两款产品MA2150和MA2155的主要差异在于内存大小:前者为1G内存, 后者为4G内存。Myraid2提供大概1T Flops的计算能力,功耗均值约为1瓦。

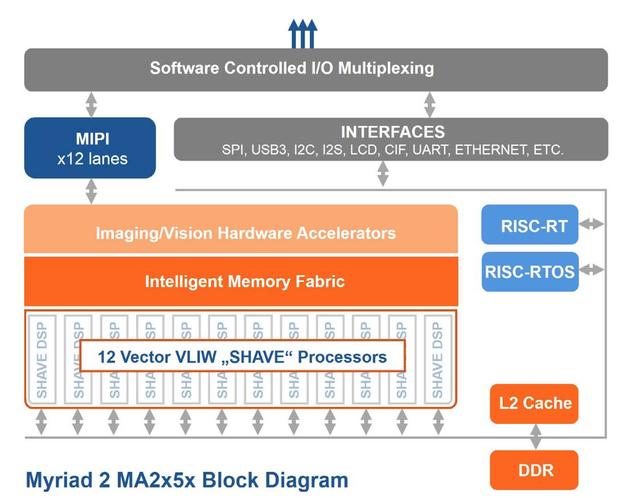
Myraid2芯片结构如上图所示,2个轻量级CPU运行一个实时系统RTOS,管理各种外设,读取卷积神经网络模型。芯片的核心部件是向量计算单元(SHAVE),这种单元最多有12个,参与计算的SHAVE数量将会直接影响程序性能。橙色方块是一些图像处理专用加速器,如锐化、去噪、缩放等,这种加速器在目前的开发工具中尚无法使用,将在以后的版本中开放支持。

Movidius会为特定的客户提供开发板,但对普通用户而言,通用、简单的接口和封装往往更受欢迎。英特尔Movidius推出了基于Myraid2芯片的神经元计算棒,将所有的功能封装到了U盘大小的设备中,用户只需要将计算棒插入USB 2.0(推荐USB3.0)以上的接口中,即可享用机器学习的强大功能。


Movidius开发套件可以从https://ncsforum.movidius.com 免费下载。开发套件主要包含了三部分:函数库、工具和开发实例,当前推荐的开发环境为Ubuntu 16.04,x86_64。为了支持更多IOT设备,Raspberry Pi也可以运行。
需要注意的是,Movidius™神经元计算棒主要是用于做深度学习的模型推理,而对模型的训练建议使用其他平台。
当用户考虑将已经训练好的模型在神经元计算棒上使用时,总是迫不及待想知道其性能,SDK中有一个非常有用的profiler工具可以把用户的模型加载到计算棒中,快速进行性能验证。在bin目录下的运行mvNCProfile.pyc,将模型作为参数输入,并用参数-s 来设定SHAVE的个数。SHAVE越多性能越好,最多为12个。
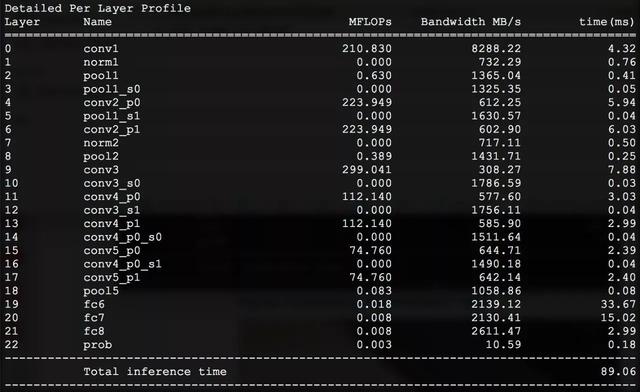
上图是验证Alexnet在Myraid2上使用12个SHAVE的性能,工具会给出模型中每层的运行时间和内存的消耗情况。当使用12个SHAVE时,Alexnet运行一次的时间为89.06 ms,而使用1个SHAVE时,其运行时间为281.06 ms。
目前Movidus开发套件支持C和Python3编程,在SDK中有很多例子,如常见的Alexnet, Googlenet, Squeezenet等都有实例,用户可以很快上手。如果单个计算棒的性能不够,还可以使用多个进行加速,取得线性加速比。


Movidius计算平台帮助开发者快速构建神经网络加速器,推动人工智能的应用。目前已经在无人机、AR、机器人甚至是可穿戴设备上得到应用 。如大疆最新的无人机Spark采用了Myraid2芯片来加速图像处理算法,Google的Clips也采用Movidius 芯片来加速机器学习算法。下一代MyraidX芯片将会带来更强的计算能力和更低能耗比,为用户带来更多选择。

如果你对 Google 的 Project Tango 感兴趣,或者看过 PingWest 品玩的相关报道,可能会记得在计算机视觉方面全球知名的硅谷公司 Movidius。它曾经堪称世界上最神秘的技术公司之一,早在三年前就被 Google 引入了 Project Tango 计划,生产名为 “VPU” 的芯片:一种专门面向计算机视觉计算设计的超级处理器。而这家公司的目标,是让计算机看懂世界。
今天,这家公司挑开了神秘的面纱,正式发布了一款面向开发者群体的“深度神经计算棒” Fathom:它就像一支 U 盘,采用标准的 USB-A 接口,却能够为与它相连的设备提供野兽般强大的机器视觉处理能力。

顾名思义, Movidius 把一个面向机器视觉调优的深度学习神经网络框架缩小到了一个 U 盘大小,就变成了 Fathom。开发者可以直接把 Fathom 插到他们的硬件上,不再需要“借用”机载的处理器或者增加新的处理器。比如用在无人机上,无人机从传感器、摄像头获取的图像传输到 Fathom 计算棒里,而计算棒能以极低的功率和极高的效率(16-20 图像/秒/瓦)向无人机传回元数据(人、物体、障碍等等)
驱动 Fathom 的核心是 Movidius 前年推出的第二代 VPU:Myriad 2。
如果说摄像机、传感器是计算机视觉的“眼睛”的话,VPU 的定位就是的“大脑”。与适合多种用途的 CPU、GPU 不同,VPU 专门为计算机视觉进行优化,可以用于 3D 扫描建模、室内导航、360°全景视频等更前沿的计算机视觉用途。相较主流的移动处理芯片(集成 GPU 的 SoC),Myriad VPU 的身材更小,视觉处理运算的效能更高。

Myriad 2 采用 28 纳米制程,每秒可以进行 3 万亿次浮点运算,功耗不到 0.5 瓦,同时支持 6 个 60 帧 1080P 视频内容输入。此前接受采访时,该公司CEO Remi El-Ouazzane 对 PingWest品玩记者透露,Myriad 2 跟其他用于进行机器视觉处理的“非专业处理器”相比,能达到“1/10 的功耗、1/5 的尺寸和 1/5 的价格,10 倍的视觉处理性能。”
Fathom 适配性很广,可以支持 PC、无人机、机器人等硬件平台。它可以在不到 1 瓦的工作功率下运行一个经过完全训练的神经网络。它的学习能力可以用于物体识别、自然语言理解、自动驾驶等。

The Verge 报道,Fathom 的价格将不高于 100 美元。如此物美价廉的一台 U 盘型深度学习计算机,今天在整个科技行业我想不出比它更伟大的新产品了。
Movidius 在全年完成了 4000 万美元的 E 轮融资,投资方包括华山资本、西桥资本、爱尔兰银行、舜宇光学等等。Movidius 共有近百名员工,分布在美国、罗马尼亚和爱尔兰三地。该公司的技术指导委员会实力十分强大,拥有多名半导体和处理器行业的元老级人物,包括被苹果收购的 P.A.Semi 创始人 Daniel Dobberpuhl、卡内基梅隆大学计算机科学/计算机视觉专家金出武雄,以及前苹果 iPhone 和 iPod 部门工程副总裁 David Tupman。
就在今年早些时候,Google 还宣布未来将在 Nexus 手机中加入 Myriad 2 芯片。这意味着,作为 Android 手机行业标杆设备的 Nexus 手机,可能将标配 Project Tango 的三维视觉扫描功能。这将让 Movidius 的获得十分可观的技术前景和利润空间。