上海交大提出零样本语义分割:像素级别特征生成|已开源
上海交大提出零样本语义分割:像素级别特征生成|已开源

编辑|陈大鑫
本文介绍的论文是刚被ACM MM 2020接收的一篇零样本语义分割论文《Context-aware Feature Generation for Zero-shot Semantic Segmentation》。
这篇论文提出了一种新的零样本语义分割方法,相比较现有方法在性能上有大幅提升(平均50%的相对提升),并且具备现有方法不具备的一些附加功能,比如生成带有特定上下文信息的像素级别特征,判断影响每个像素级别特征的上下文范围大小。
另外本论文数据库、代码、模型都已经开源。

论文地址:https://arxiv.org/pdf/2008.06893.pdf
代码地址:https://github.com/bcmi/CaGNet-Zero-Shot-Semantic-Segmentation
1 论文背景
近年来,零样本学习(zero-shot learning)非常火爆,吸引了广大研究人员的兴趣,关注的问题也从分类任务逐渐扩展到其他任务,比如零样本检索、零样本目标检测、零样本语义分割等等。
零样本检索和零样本目标检测目前有升温趋势,零样本语义分割也开始兴起。因为分割掩码(segmentation mask)的标注成本要比图像标签高很多,所以零样本语义分割比零样本分类有更大的研究价值和应用前景。
下图是零样本语义分割任务的图示。和零样本分类相同,零样本语义分割把所有种类分为已知种类和未知种类两个集合,两个集合没有交集。训练集只有已知种类的分割掩码,测试集包含已知种类和未知种类。零样本语义分割旨在通过种类级别的语义表征(比如词向量、属性向量等)从已知种类向未知种类迁移信息,从而在测试阶段完成已知种类和未知种类的分割。

2 相关工作
现有的零样本语义分割方法有SPNet[1]和ZS3Net[2 ], 如下图所示。SPNet根据已知种类数据学习从像素级别特征到词向量的映射,在测试阶段可以通过比较映射后的像素级别特征和所有种类的词向量完成分割。
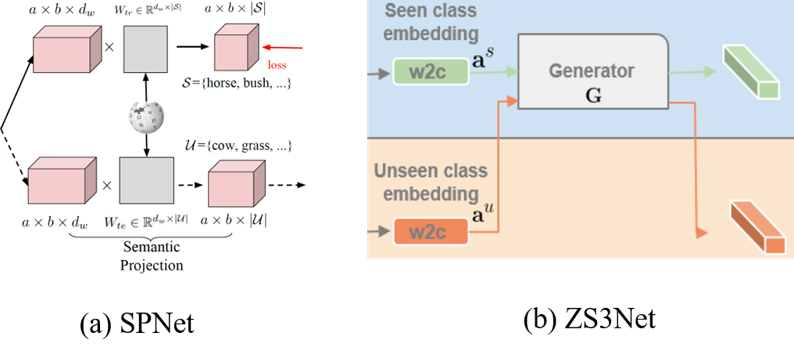
但是这种做法一个最严重的问题是已知种类偏见(seen bias),也就是所有像素都被分到已知种类,导致未知种类的分割性能趋近于零。这个现象在广义零样本分类(generalized zero-shot classification)里面也被广泛研究过。SPNet针对已知种类偏见提出了一种简单的校准方案,把已知种类的预测值减去一个常量,从而让已知种类的预测值和未知种类的预测值有可比性。但是这种简单的校准方案效果并不理想。ZS3Net用特征生成的方式解决已知种类偏见的问题,即根据已知种类数据学习从词向量到像素级别特征的映射。学习映射之后,可以用未知种类的词向量生成未知种类的像素级别特征,对最后一层分类器微调,使其可以兼顾已知种类和未知种类。ZS3Net里面的特征生成器输入一个种类的词向量和采样得到的随机向量,生成该种类的像素级别特征。然而,用这种方式生成的像素级别特征多样性有限,并且没有充分考虑影响像素级别特征的上下文信息。
3
方法
为了研究上下文信息对像素级别特征的影响,作者在Pascal-Context数据集上训练DeepLabv2模型,提取最后一层1×1卷积之前的特征图(feature map)的像素级别特征。简单起见,我们只关注种类“猫”的像素级别特征,并用K-means算法把这些像素级别特征聚成K类。
可以看出像素级别特征受到像素在所属物体中的位置、所属物体的姿势、所属物体的背景环境等因素影响。比如左图K=2的情况,猫轮廓的像素级别特征被聚成一类,猫内部的像素级别特征被聚成一类。右图K=5的情况,红色像素受到背景中床单的影响,蓝色像素受到背景中绿色植被的影响。
实际上,各种上下文因素对像素级别特征的影响非常复杂,所以只能通过网络学习捕捉上下文信息对像素级别特征的影响。基于上述观察,作者设计了CaGNet (Context-aware feature Generation), 旨在生成特定上下文环境中的像素级别特征。

整体网络结构
下图是方法的整体网络结构,E是分割骨干网络,CM是上下文信息提取模块,G是特征生成器,D是鉴别器,C是分类器。CM模块输出上下文信息图(context map)和特征图(feature map)。上下文信息图包每个像素的上下文表征,特征图包含每个像素的特征。CM模块由几层打孔卷积(dilated convolution)构成,可以聚集不同尺度的上下文信息。考虑到每个像素级别特征受到影响的上下文范围可能不同,CM为每个像素动态选择合适的上下文尺度,所以据此也能判断每个像素受到哪种上下文尺度的影响最大。CM模块的技术细节请参看论文。
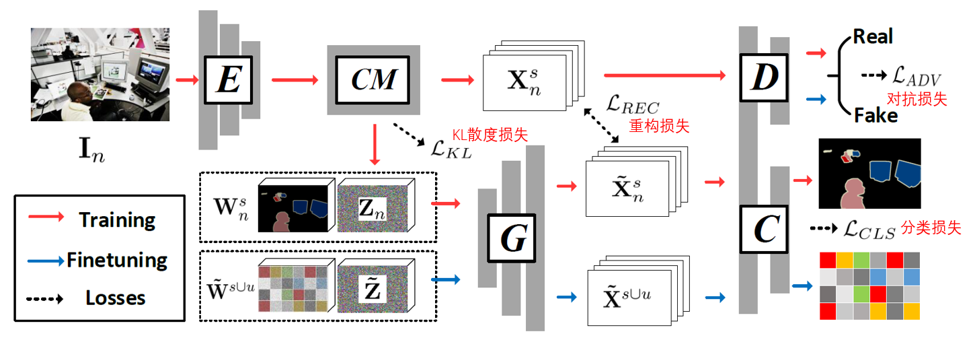
作者把每个像素的上下文表征映射到上下文潜在编码(contextual latent code),并通过KL散度损失使其和单位高斯分布接近,假设上下文信息有足够的消歧性。换言之,确定一个种类,充分的上下文信息可以决定唯一的像素级别特征,也就是说上下文信息和像素级别特征之间存在一一对应的关系。
基于这种假设,一个像素的上下文潜在编码和该像素种类对应的词向量共同作为特征生成器G的输入,可以重构该像素的特征(重构损失)。
另外,作者用鉴别器D和分类器C保证生成的特征分布接近真实的特征分布,并且属于预期的种类。先用已知种类的像素训练网络,因为上下文潜在编码被强制接近单位高斯分布,给定一个未知种类的词向量,可以从单位高斯分布生成随机向量,和未知种类的词向量共同输入到特征生成器G,得到该未知种类的像素级别特征。
通过采样不同的随机向量,可以生成该未知种类在不同上下文环境中的像素级别特征。生成的未知种类像素级别特征可以用来微调分类器C,完成从可见类向不可见类的知识迁移。
4 实验结果
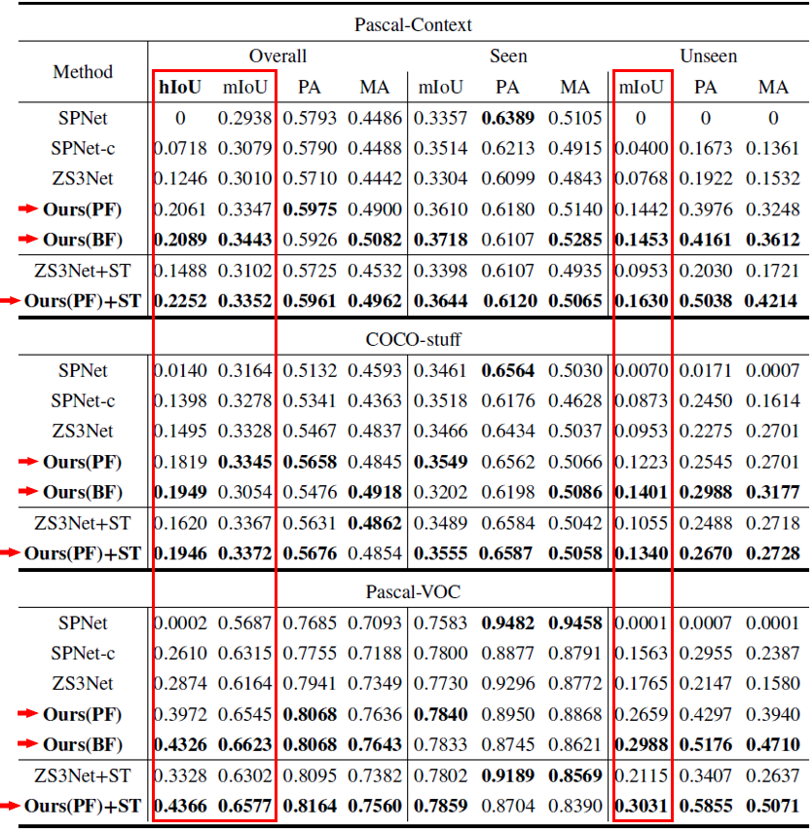
作者在三个语义分割数据集Pascal-VOC, Pascal-Context, COCO-stuff上做实验,用到的评价指标有harmonic IoU (hIoU)、mean IoU(mIoU)、pixel accuracy(PA)、mean accuracy(MA), 其中hIoU是最主要的评价指标。
与SOTA模型对比
下面的表格总结了在三个数据库上本文的方法和现有方法SPNet、ZS3Net的实验结果。其中ST表示自学习策略 (self-training),即用训练集中未标注的未知种类像素辅助训练。从表格中可以看到本文的方法在不可见类指标和综合指标上均取得了大幅提升。对于hIoU指标,Ours(BF)相较于基准方法在三个数据集上分别带来了67.7%、30.4%和 50.5% 的相对提升。
Pascal-VOC数据集上可视化结果对比
下图是基准方法和本文的方法在Pascal-VOC数据集上的零样本语义分割可视化结果,可以看出本文的方法能够更有效地分割不可见类物体,比如显示器(第一、六行,棕色)、火车(第二、五行,淡绿色)、沙发(第三行,翠绿色)、绵羊(第四、八行,深蓝色)、盆栽植物(第七行,深绿色)。

重构特征
另外,本文的模型可以用来重构特征,即给定上下文信息和某种类的词向量,可以生成在给定上下文环境中该种类像素的特征。
为了验证从已知种类到未知种类的可迁移性,作者在测试集上利用从测试图片提取的上下文信息生成未知种类的像素级别特征,并计算和真实像素级别特征之间的重构损失。
特征重构损失的可视化结果
下图是基于Pascal-VOC数据集测试集图片的特征重构损失的可视化结果。通过对比w/o CM和with CM, 可以看出加入CM模块之后本文的方法能准确重构出可见类甚至不可见类的像素级别特征,比如沙发(第一行)、显示器(第二行)、盆栽植物(第三行)、绵羊(第四行)。

前文介绍过,本文的CM模块带有上下文选择器,可以为每个像素动态选择合适的上下文尺度,所以据此也能判断每个像素受到哪种上下文尺度的影响最大。
上下文选择器的可视化效果
下图是基于Pascal-VOC数据集的上下文选择器的可视化效果。上下文选择器可以推断出影响每个像素级别特征的上下文范围大小(小尺度、中尺度或大尺度)。
观察下图可以得出,具有区分性的局部区域(第一行桌面上的物品,第三行的猫脸和猫尾巴)内的像素点趋于受到小尺度上下文信息的影响,其余像素点趋于受到中尺度或大尺度上下文信息的影响。

5 总结
本文提出了一种新的零样本语义分割方法,相比较现有方法在性能上有大幅提升(平均50%的相对提升),并且具备现有方法不具备的一些附加功能(比如生成带有特定上下文信息的像素级别特征,判断影响每个像素级别特征的上下文范围大小)。
踩坑记录
作者对AI科技评论谈到:
其实在做这个工作之前,我们“浪费”了大半年的时间尝试把很多零样本分类的方法照搬到零样本语义分割,结果发现完全不work,最终才转移到像素级别特征生成上来。并且,我们现在已经把像素级别(pixel-wise)特征生成升级到碎片级别(patch-wise)特征生成,结果有了进一步提升。但是再往上走,因为未知种类物体的形状大小未知,很难生成一整张完整的特征图,这也是零样本语义分割亟待解决的一个问题。我们的数据库、代码和模型都已经开源,欢迎关注零样本语义分割任务。
参考文献:
[1] Yongqin Xian, Subhabrata Choudhury, Yang He, Bernt Schiele, and Zeynep Akata, “Semantic Projection Network For Zero-and Few-Label Semantic Segmentation”,CVPR, 2019.
[2] Maxime Bucher, Tuan-Hung Vu, Mathieu Cord, and Patrick Pérez,”ZeroShot Semantic Segmentation”, NeurIPS, 2019.
https://m.toutiaocdn.com/i6864229950606705166/?app=news_article×tamp=1598236112&use_new_style=1&req_id=20200824102832010129035094143EFE53&group_id=6864229950606705166&tt_from=android_share&utm_medium=toutiao_android&utm_campaign=client_share
转载请注明:徐自远的乱七八糟小站 » 上海交大提出零样本语义分割:像素级别特征生成|已开源