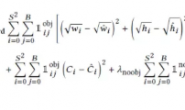【目前最快最简单的神速排序算法——桶排序】
PS:桶排序最大的好处是可以有效利用多线程的力量。

其实在我们生活的这个世界中到处都是被排序过的。上图这种情况大家一定都遇到过;站队的时候会按照身高排序,考试的名次需要按照分数排序,网上购物的时候会按照价格排序,电子邮箱中的邮件按照时间排序……

总之很多东西都需要排序,可以说我们就是生活在排序中,不论被动或主动!!今天呢,咱们就来探讨一个最快最简单的排序算法——桶排序!

桶排序定义:
假定:输入是由一个随机过程产生的[0, 1)区间上均匀分布的实数。将区间[0, 1)划分为n个大小相等的子区间(桶),每桶大小1/n:[0, 1/n), [1/n, 2/n), [2/n, 3/n),…,[k/n, (k+1)/n ),…将n个输入元素分配到这些桶中,对桶中元素进行排序,然后依次连接桶输入0 ≤A[1..n] <1辅助数组B[0..n-1]是一指针数组,指向桶(链表)。

桶排序算法思想:
其思想非常简单易懂:将一个数据表分割成许多小数据集,每个数据集对应于一个新的集合(也就是所谓的桶bucket),然后每个bucket各自排序,或用不同的排序算法,或者递归的使用bucket sort算法,往往采用快速排序,是一个典型的divide-and-conquer分而治之的策略。其中核心思想在于如何将原始待排序的数据划分到不同的桶中,也就是数据映射过程f(x)的定义,这个f(x)关乎桶数据的平衡性(各个桶内的数据尽量数量不要差异太大),也关乎桶排序能处理的数据类型(整形,浮点型;只能正数,或者正负数都可以)。另外,桶排序的具体实现,需要考虑实际的应用场景,因为很难找到一个通吃天下的f(x)。
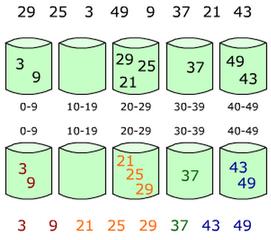
桶排序基本实现步骤:
- 初始化装入连续区间元素的n个桶,每个桶用来装一段区间中的元素。
- 遍历待排序的数据,将其映射到对应的桶中,保证每个桶中的元素都在同一个区间范围中。
- 对每个桶进行排序,最终将所有桶中排好序的元素连起来。
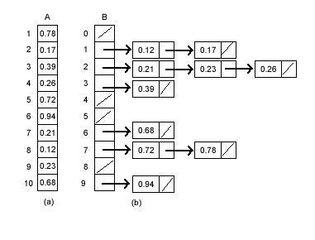
桶排序其中也蕴含着分治的策略,联想之前的计数排序,基数排序就像是桶排序的一个特例,一个数据一个桶。并且和散列(哈希,hash)似乎也有千丝万缕的关系。

桶排序C实现代码:


桶排序实例应用:
1)一年的全国高考考生人数为500 万,分数使用标准分,最低100 ,最高900 ,没有小数,你把这500 万元素的数组排个序。

方法:创建801(900-100)个桶。将每个考生的分数丢进f(score)=score-100的桶中。这个过程从头到尾遍历一遍数据只需要500W次,。然后根据桶号大小依次将桶中数值输出,即可以得到一个有序的序列。而且可以很容易的得到100分有***人,501分有***人。
实际上,桶排序对数据的条件有特殊要求,如果上面的分数不是从100-900,而是从0-2亿,那么分配2亿个桶显然是不可能的,所以桶排序有其局限性,适合元素值集合并不大的情况。
实现代码:

2)已知一组范围在0~10的数据(如:9,5,2,7,7),你有没有什么好方法编写一段程序,将数据从大到小输出呢?
方法:我们只需要借助一个一维数组就可以解决问题。首先,我们申请一个长度为11的数组int a[11],因为我们的数据范围是0~10,而int a[11]的元素正好是a[0]~a[10]。开始的时候,我们将所有元素都初始化为0,表示这些数都未出现过。例如a[0]等于0,就表示待排序数据还未出现过0;同理,若a[9]等于1,则表示待排数据中9出现过1次。
实现代码:

桶排序总结:
桶排序虽快,但其实它是用空间在换时间。如果需要排序的数范围非常宽,那我们就需要申请非常多的“桶”来存储每一个数出现的次数。即使依然只是需要对5个数进行排序,这太浪费空间了!所以在选择使用哪种排序算法之前,还是需要根据实际情况,权衡好复杂度与空间的问题。
转载请注明:徐自远的乱七八糟小站 » 【目前最快最简单的神速排序算法——桶排序】