【神级程序员用Python3抓取12306车次信息!超详细的新手案例教学!】
前言
最近学习Python,所以呢?跟大家一样,都是看看官网,看看教程,然后就准备搞一个小东西来试试,但是网上的很多这样的例子不是不够详细就是版本是2的。用到3上就会发生一些bug!所以今天给大家分享这么一个实站教学!在给大家分享之前呢,小编推荐一下一个挺不错的交流宝地,里面都是一群热爱并在学习Python的小伙伴们,大几千了吧,各种各样的人群都有,特别喜欢看到这种大家一起交流解决难题的氛围,群资料也上传了好多,各种大牛解决小白的问题,这个Python群:330637182 欢迎大家进来一起交流讨论,一起进步,尽早掌握这门Python语言。

结果展示:
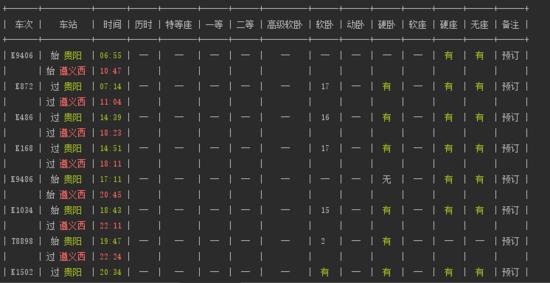
我在window上运行的结果
下面这一段说明我是抄的,哈哈,因为我自己再怎么写还不是同样的内容。
让我们先给这个小应用起个名字吧,既然及查询票务信息,那就tickets,其实 大家随意了,需要发布就需要起一个更好的名字,不然只要自己玩儿的懂,但是要有程序的特点,所以还是tickets相关的吧。方便阅读和自己记忆。
我们希望用户只要输入出发站,到达站以及日期就让就能获得想要的信息,比如要查看10月31号贵阳-遵义西的火车余票, 我们只需输入:
python3.5 lnlr.py 贵阳 遵义西 2017-10-31
注意:上面的日期(包括后面的)是笔者写文章时确定的日期,当你在做这个项目的时候可能要根据当前时间做适当调整。
转化为程序语言就是:
python3.5 lnlr.py from to date
另外,火车有各种类型,高铁、动车、特快、快速和直达,我们希望可以提供选项只查询特定的一种或几种的火车,所以,我们应该有下面这些选项:
-g 高铁
-d 动车
-t 特快
-k 快速
-z 直达
这几个选项应该能被组合使用,所以,最终我们的接口应该是这个样子的:
python3.5 lnlr.py [options] from to date
接口已经确定好了,剩下的就是实现它了。
环境
Centos 7 linux 系统
Python3.5.2
使用到的库
docopt——>命令行解释器(把我玩儿死)
colorama—>一个文本着色器
requests —>爬虫必备,http请求库
prettytable->表格显示
安装库
- 未安装之前

Linux上面目前的库
安装库:
pip3.5 install requests colorama docopt prettytble
- 安装之后
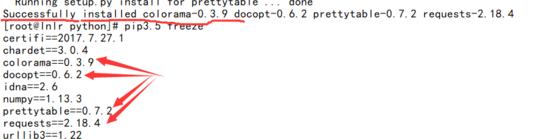
安装完成之后的库列表
ok,我们环境有了,库有了,那么应该干啥呢?
爬虫个人分析:
- 制定爬取内容
- 选取目标
- 准备环境,上面就提前说了,因为这个本来就是在搞爬虫,所以…
- 分析该网站的html结构,得到url
- 爬取数据
- 分析数据
- 封装数据(组装数据),弄成自己想要的样子
- coding……
那么我们开始吧
第一步
当然是打开12306的官网了,然后进行一个余票查询,当然首先你得按一下f12,打开控制台面板哦。
我是查询的是:贵阳–遵义西 10-31号的车票
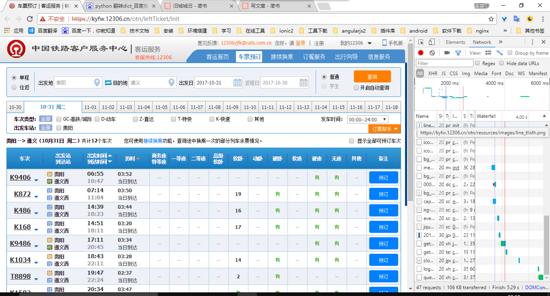
f12之后,查票页面
我先埋下一个伏笔:
我看到的贵阳-遵义 10-31的车次一共是11个班次。
第二步
首先在控制台找到Network按钮,点击。然后选择XHR —》找到请求到后台的接口,
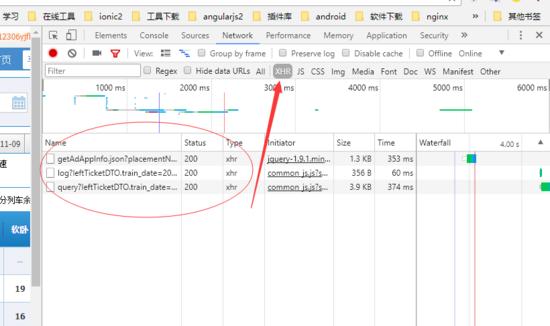
请求接口
那么我们先看一个三个接口的请求和返回的数据:
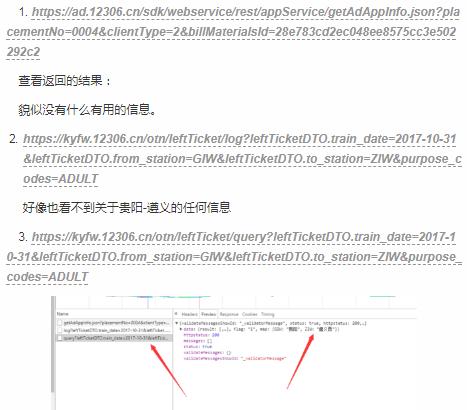
第三个接口返回的数据
哈哈,在里面我看到了贵阳,遵义,那么大胆的猜测这个接口有可能就是我们需要的。
我们继续点开看看有什么东西,这些数据都是以json的格式传递过来的。
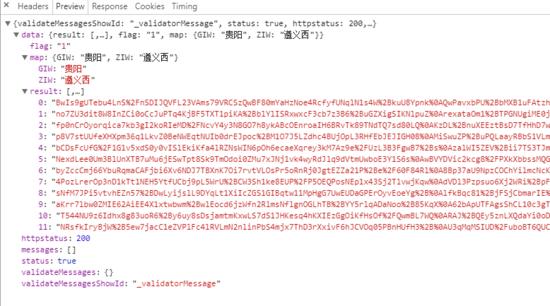
展开结果
到这里我相信,聪明的人已经知道了这个就是我们所需要的接口了,而这些数据就绝对是车次信息的数据。
由上面的我f12查看到的数据是11条,那么你们就没有点小激动么?
说明这个接口就是我们所需要的接口无误。那么现在我们就要得到它的url咯。
靠,双十一快到了,被女朋友抓去看了一会儿衣服,可能今天就不写了,明天接着写。
那么这样:我就明天开始分析url,然后就coding
请求的接口URL:
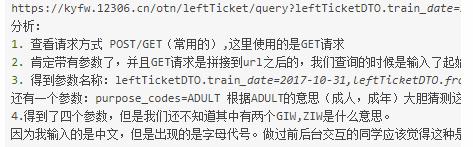
分析参数的获取
leftTicketDTO.train_date=2017-10-31 时间
leftTicketDTO.from_station=GIW 出发地
leftTicketDTO.to_station=ZIW 目的地
同学们请注意:我们输入的是中文,出来的是地点代码,说明中间有一层转换,那么在常规的网站中,只有两种三种方式能这样处理?
- 将这个地点-地点代码字典写入js中,这个地方不可能,因为国内的地点太多。
- 将地点-地点代码字典写入本地文件,然后使用。
- 从远端服务器进行获取,在这里也没必要,因为每次都要去请求后台,增加服务器的压力,这个是没必要的,因为这个字典的话是基本不会变化的。
ok经过上面的分析,我们就能很清楚的知道这个字典绝对是从js获取的,那么我们就也一样的使用发f12来检查到资源,找到该页面所引用的所有js,然后进行分析。
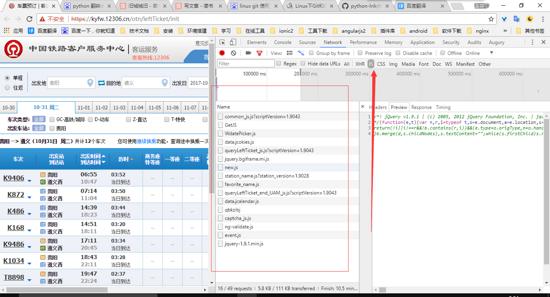
该页面所加载的js文件
上图中的矩形中的就是当前页面中的所有js,当然每个js的作用我就不一一的说了,各位需要帮助的可以email我,或者在下面留言。
那么我直接查看各个的内容,发现有一个是:
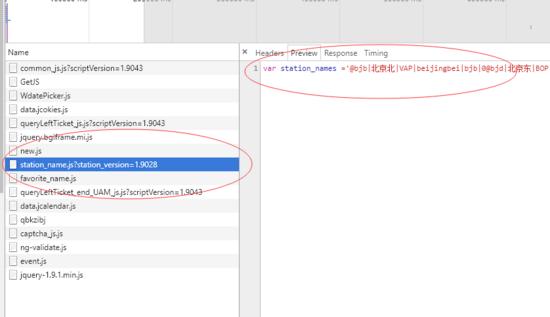
包含了地点,地点代码js
这样我们就得到了一个js的请求地址哦。 https://kyfw.12306.cn/otn/resources/js/framework/station_name.js?station_version=1.9028

浏览器中输入该URL看到的结果
我们还可以来一个测试:
我在查询的时候是输入了,贵阳-遵义,搜索一下看看吧。
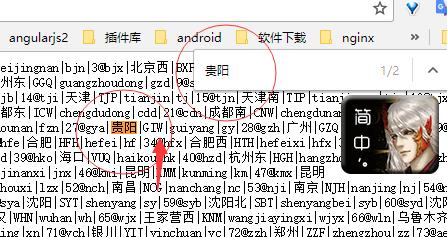
搜索
同学们,看到这个你们觉得爽不爽,说明这个文件就是我们所需要的。
ok,到这里,编码前期准备工作,所有的都昨晚了,我从一步一步的分析,然后截图。给大家思路,方法,步骤。希望大家能够更明白,更多的是学习到其中的分析思路哈。
codingwars
- 首先爬取地点-代码code字典。

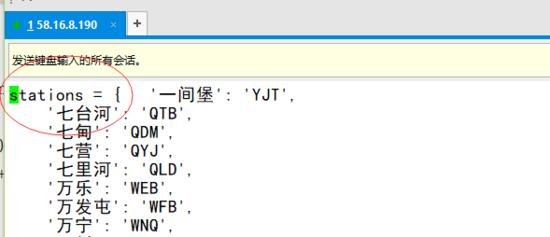
新增一个stations字典名称
好的,到这里我们的地点-地点代码就得到了,那么我们就应该写那个爬取车次信息的py了。
处理输出的代码:

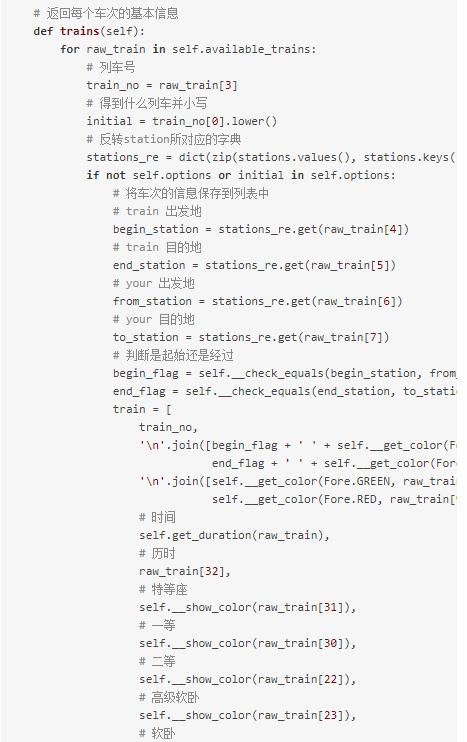


成果展示:
但是我在远端上使用xshell没有颜色,这个是什么鬼。最后发现是自己设置xshell而已。
好的,下面就是我们的程序执行的结果。
如果程序输入的地点在字典中查询不到,那么就不能查票。所以我们需要随时更新stations.py文件(地点-code字典表)
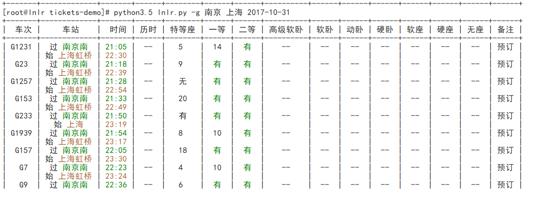
成果展示
ok,到这里的话,我们的所有的爬虫就抓取成功,并且输出成我们想要的结果了。我准备下一步就是搞那个抢票。试试吧。



