【干货|2017年数据科学15个最好用的Python库】

大数据文摘作品,转载要求见文末
作者:Igor Bobriakov
编译:朱璇、卫青、万如苑
导读:随着近几年Python已成为数据科学行业中大火的编程语言,我们将根据以往的经验来为大家总结一下数据科学家和工程师几个最实用的python库。如果你是正在学习Python的学生,也许根据这个表单能够帮你更好地找到学习的重心。
因为所有的python库都是开源的,所以我们还列出了每个库的提交次数、贡献者人数和其他一些来自Github可以代表Python库流行度的指标。
核心库
1. NumPy(Github提交次数:15980,贡献者人数:522)
在用Python处理科学任务时,我们常常需要使用Python的SciPy Stack。SciPyStack是一个专门为用Python处理科学计算而设计的软件集(注意不要把SciPy Stack和SciPy库搞混啦;SciPy库只是SciPy Stack的一部分)。 让我们来看看SciPy Stack里面都包括什么:SciPy Stack其实相当庞大,包括了十几个库。其中NumPy库是它的核心库(特别是最重要的几个库)中的明星。
NumPy(来自NumericalPython)是构建科学计算代码集的最基础的库。 它提供了许多用Python进行n维数组和矩阵操作的功能。该库提供了NumPy数组类型的数学运算向量化,可以改善性能,从而加快执行速度。
2. SciPy(Github提交次数:17213,贡献者人数:489)
SciPy是一个针对工程和科学库。 再次提醒大家SciPyStack不等于SciPy库: SciPy Stack包括线性代数、优化、整合和统计等模块,而 SciPy库的主要功能是建立在NumPy基础之上,因此它使用了大量的NumPy数组结构。 SciPy库通过其特定的子模块提供高效的数学运算功能,例如数值积分、优化等。 值得一提的是SciPy子模块中的所有功能都附有详细的文档可供查阅。
3. Pandas(Github提交次数:15089,贡献者人数:762)
Pandas是一个简单直观地应用于“带标记的”和“关系性的”的数据的Python库。它是探索数据的完美工具,能快速简单地进行数据操作、聚合和可视化。
“数列(Series)”: 一维数组
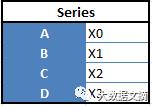
“数据框(Data Frames)” :二维数组
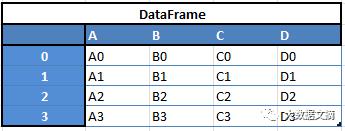
例如,当你想从这两种数据结构中得到一个新的数据框,把一个数列作为新的一行添加至数据框,你就能得到一个如图所示的数据框。
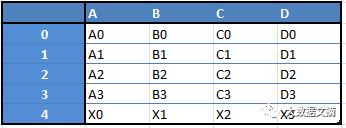
下面列出的只是你可以用Pandas做的事情的一小部分:
● 轻松添加或删除数据框中的数列
● 将其他数据结构转换为数据框
● 处理缺失的数据,比如用NaN表示它们
● 强大的高效分组功能
下图:核心库的Google Trends历史记录
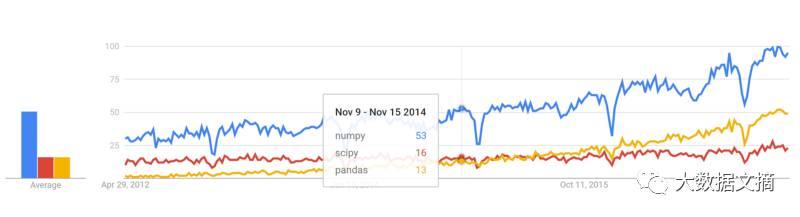
图片来源:trends.google.com
下图:核心库的GitHub下载请求历史记录
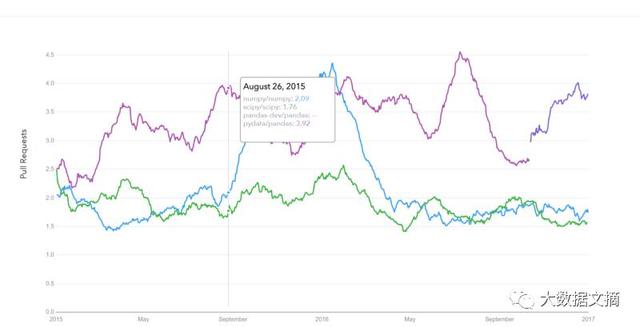
图片来源:datascience.com/trends
可视化类
4. Matplotlib(Github提交次数:21754,贡献者人数:588)
MatPlotlib是另一个SciPy Stack的核心库。它是为能轻松生成简单而强大的可视化图标而量身定制。 MatPlotlib是一个超酷的库,它和NumPy,SciPy以及Pandas一起使Python成为像MatLab、Mathematica这样的科学工具的强力竞争者。
然而,MatPlotlib是一个低端库。这意味着您需要编写更多的代码才能达到高级的可视化效果;换句话说,和使用其他高级工具相比,使用MatPlotlib你需要投入更多的精力,但总体来说MatPlotlib还是值得一试的。
付出一些努力,您就用MatPlotlib做任何您想做的可视化图表:
● 线路图
● 散点图
● 条形图和直方图
● 饼状图
● 茎图
● 轮廓图
● 矢量场图
● 频谱图
Matplotlib还可用来创建标签、网格、图例和许多其他样式图。基本上,一切图表都可以通过Matplotlib来定制。
Matplotlib库还能支持不同的平台,并能使用不同的GUI套件来展示所得到的可视化图表。 各种IDE(比如IPython)都支持Matplotlib的功能。
除了Matplotlib,python还有一些其他库能让可视化变得更加容易。
下图:使用Matplotlib制作的图表展示
5. Seaborn(Github提交次数:1699,贡献者人数:71)
Seaborn主要关注统计模型的可视化,包括热分布图(用来总结数据及描绘数据的整体分布)。 Seaborn是基于且高度依赖于Matplotlib的一个python库。
下图:使用Seaborn制作的图表展示
6. Bokeh(Github提交次数:15724,贡献者人数:223)
还有一个强大的可视化库叫做Bokeh,其目的是互动式的可视化。 与Seaborn不同,Bokeh独立于Matplotlib。 如上所述,Bokeh的卖点是互动性,它通过数据驱动文档(d3.js)风格的新式浏览器来呈现图表。
下图:使用Bokeh制作的图表展示

7. Plotly(Github提交次数:2486,贡献者人数:33)
Plotly是一个基于Web来构建可视化的的工具箱。它有好几种编程语言(其中包括Python)的API,并在plot.ly网站上提供一些强大的、开箱即用的图表。 要使用Plotly,您先需要设置您的Plotly API密钥。Plotly将在其服务器端处理图表,并将结果在互联网上发布。此外,它也提供了一种不需要使用其服务器和网络的offline方法。
下图:使用Plotly制作的图表展示
下图:python可视化库的Google趋势记录
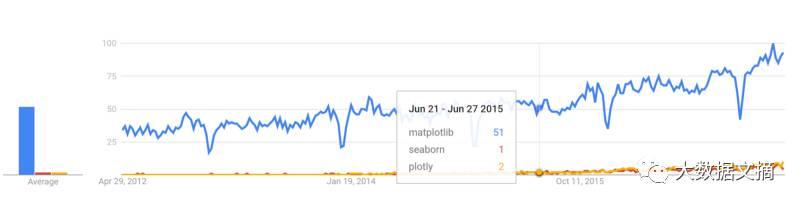
图片来源:trends.google.com
机器学习类
8. SciKit-Learn(Github提交次数:21793,贡献者人数:842)
Scikits是SciPy Stack的另一库,它专为某些特殊功能(如图像处理和机器学习辅助)而设计。对于机器学习而言,SciKit-Learn是其中最突出的一个是库。SciKit-Learn建立在SciPy之上,并大量使用SciPy进行数学操作。
scikit-learn为常见的机器学习算法设计了一个简洁通用的界面,使得在生产系统使用机器学习变的十分简单。 该库有着高质量的代码和文档,性能高,容易使用,是使用Python进行机器学习的行业实践标准。
深度学习类 – Keras / TensorFlow / Theano
在深度学习方面,Keras是最杰出最方便的Python库之一。它可以在TensorFlow或者Theano之上运行。 下面让我们来看一下它们的一些细节:
9.Theano. (提交:25870次,贡献者:300个)
首先我们来谈谈Theano.
Theano同Numpy类似,是一款定义多维矩阵并含有数学运算符和表达式的Python包。通过编译这个库可以在任何环境下有效的运行。由蒙特利尔大学的机器学习小组最初开发,它主要用于满足机器学习的需要。
很重要的一点是要注意到,Theano在低级别运算符上同NumPy紧密的结合在一起。并且这个库优化了GPU和CPU的使用,使其在处理大数据运算时的表现更为迅速。
效率和稳定性的调整,使得即使是非常小的值也能得到更精确的结果,例如,即使给一个非常小的x值,计算log(1 + x)也能给出一个可是别的结果。
10.TensorFlow (提交:16785次,贡献者:795个)

这是一个由Google的程序员开发,为机器学习打造的数据流图像计算开源库。设计它的目的是为了满足Google环境中对训练神经网络的迫切需求。其前身是DistBelief,一个基于神经网络的机器学习系统。而且TensorFlow并非严格受制于Google的框架——它可以广泛地适用于多种真实世界的应用中。
TensorFlow的主要特点是他的多层节点系统,可以在大数据上快速的训练人工神经网络。这点为Google的语音识别以及图像识别提供了助力。
11.Keras (提交:3519次,贡献者:428个)
最后,来看一看Keras,这是一个Python开源库,用于在高级界面上建立神经网络。它简约且直接,并拥有很强的延展性。它使用Theano 和 TensorFlow作为其终端,并且微软正在试图将CNTK(微软自己的认知工具包)结合进去成为一个新的终端。
这种简约的设计方式旨通过紧凑型系统建立来实现更加快捷和简单的操作。
Keras极易上手,并且在使用的过程中有很多快速原型可供参考。它完全用Python写的库,并且本身就非常高级。Keras非常模块化并有很强的拓展性。尽管Keras简易,有高层次定位。Keras仍然拥有足够的深度和力量来进行严肃的建模。
Keras的核心理念是“层级”,一切都是围绕着层级建立的。数据在张量(tensors)中处理好,第一层负责张量的输入,最后一层负责输出,而模型则在这之间建立。
谷歌Trends历史记录
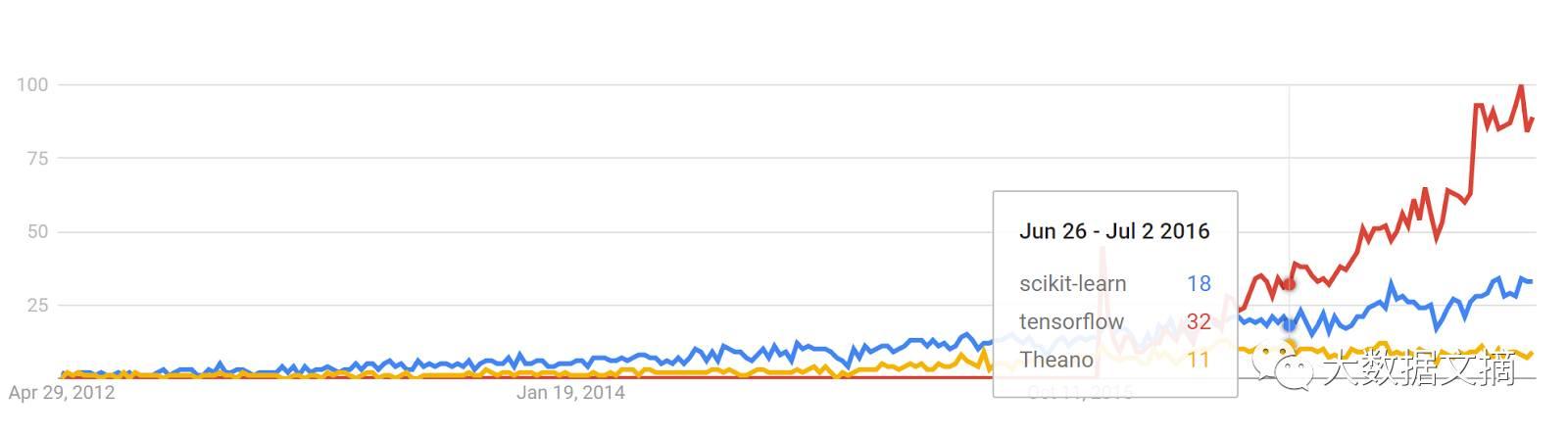
trends.google.com
Github合并请求(pull requests)历史纪录
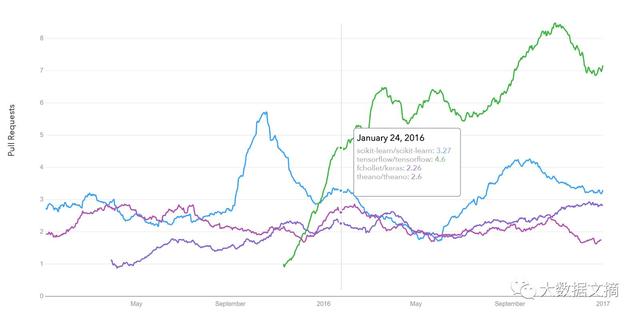
datascience.com/trends
自然语言处理
12.NLTK (提交:12449次,贡献者:196个)
这个库的名字是Natural Language Toolkit(自然语言工具)的缩写。正如其名,它被用于由象征性与统计性自然语言处理的一般任务。NLTK旨在用于自然语言处理的教学与研究等的相关领域(语义学,认知人工智能科学,等等)并现在它的使用受到了很大的关注。
NLTK在功能上允许很多操作,例如文字标签,归类,标记解释,名称识别;通过建立语料树(corpus tree)来解释句子的内外联系,词根提取以及语义推理。所有这些内置模块都允许为不同的任务建造复杂研究系统。
13.Gensim (提交:2878次,贡献者:179个)
这是一个开源的Python库,为人们提供向量空间建模和主题建模的工具。这个库的设计旨在高效处理大规模文本:除了允许内存中处理,效率的主要来源在于广泛使用NumPy的数据结构和SciPy的运算符号,这两个使用起来都十分的高效和简单。
Gensim主要被用于未加工的非结构化的数字文本。Gensim使用了诸如:分层狄式流程(hierarchical Dirichlet processes),潜在语义分析(latent semantic analysis),潜在狄氏分布(latent Dirichlet allocation)以及文档频次(tf-idf,term frequency-inverse document frequency),随机映射,文字/文档向量化(word2vec,document2vec)检测多个文档文字中词语出现的频次,通常被成为语料库(corpus),之类的算法。这些算法都是非监督性的——不需要任何的参数,唯一的输入就是语料库。
谷歌Trends历史记录

图片来源:trends.google.com
Github下载请求历史纪录
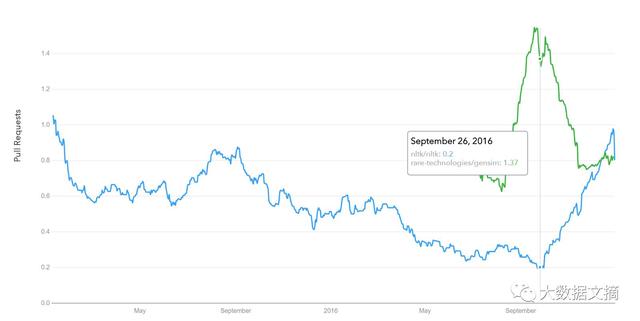
图片来源:datascience.com/trends
数据挖掘与统计
14. Scrapy(提交:6325次,贡献者:243个)
Scrapy是一个制做爬虫程序的库,也被称作“蜘蛛机器人”(spider bots)。旨在提取结构化数据,例如从网页联络信息,或网址链接。
它是开源并由Python写的库。正如其名,它最开始只是为了扒网页所设计,然而现在他已经进化成为一个拥有从API上获取数据并且,用途广泛的爬虫程序。
这个库一直贯彻其“不要在界面设计上重复你自己”的宗旨——鼓励用户写出广泛适用并可重复使用的代码,从而制造强大的爬虫软件。
整个Scrapy的结构都是围绕蜘蛛类建造的,该类封装了爬虫跟踪的一组指令。
15. Statsmodels (提交: 8960, 贡献: 119)
你可能已经从它的名字猜到了,statsmodels是一个让用户通过多种估计方式和统计模型,进行数据探索和统计分析的Python库。
实用的特征有:统计描述,线性回归模型,广义线性模型,离散选择模型,稳健线性模型,时间序列分析以及多种回归子。
这个库同样提供大量为统计分析专门设计的画图方程,并且为更好的展示大数据进行了专门的调整。
结论
以上这些就是由数据科学家和工程师们公认的值得你一探究竟的Python库。
这是每个库在Github上动向的详细数据:
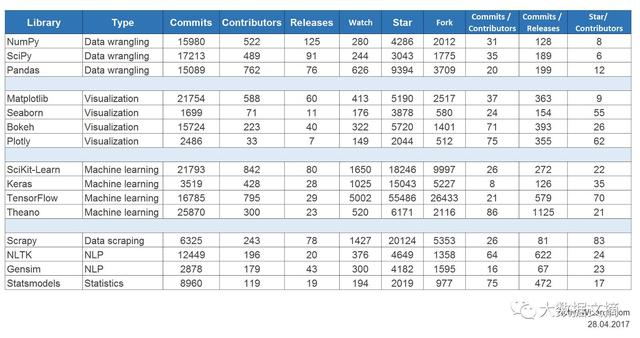
来源:https://docs.google.com/spreadsheets/d/1wLOtLLJ65QMbLumc3F2Mop_4uPIFbyJ6iDZwOp0cXrQ
当然这不是最终极全面的总结。也有其他的库和框架,同样值得为了特殊的任务进行适当的关注。一个很好的例子是另一个程序包SciKit,它重点针对一些特别的领域。像SciKit-Image就针对于图像处理。
所以如果你还想到其他有用的库的话,请在评论区与读者一起分享吧。
原文链接:https://medium.com/activewizards-machine-learning-company/top-15-python-libraries-for-data-science-in-in-2017-ab61b4f9b4a7



