Pytorch 深度学习实战教程(五):今天,你垃圾分类了吗?

1



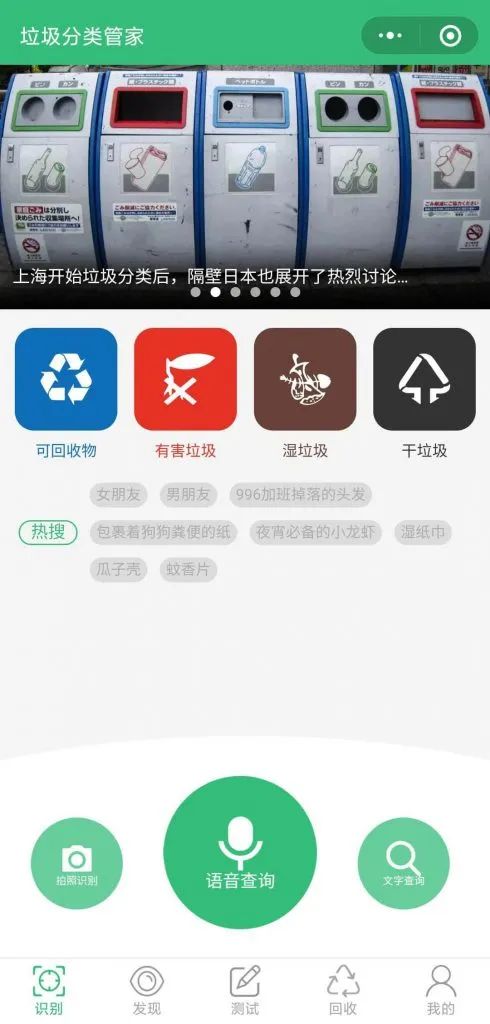
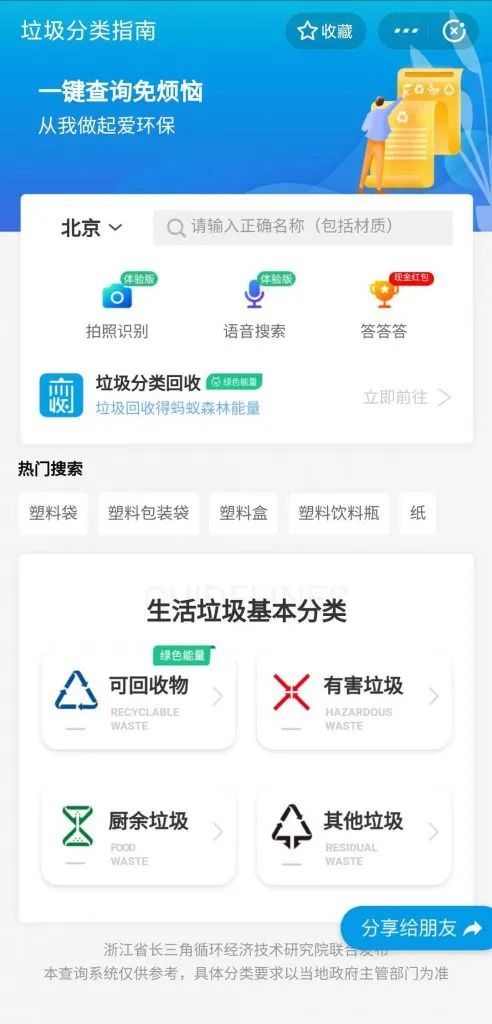
2

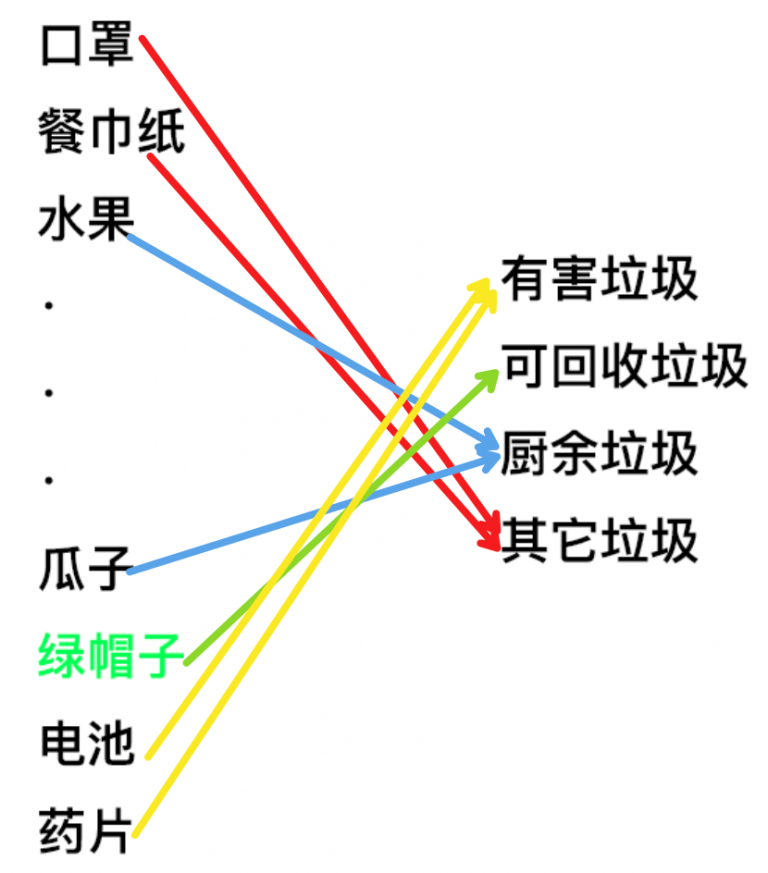
3
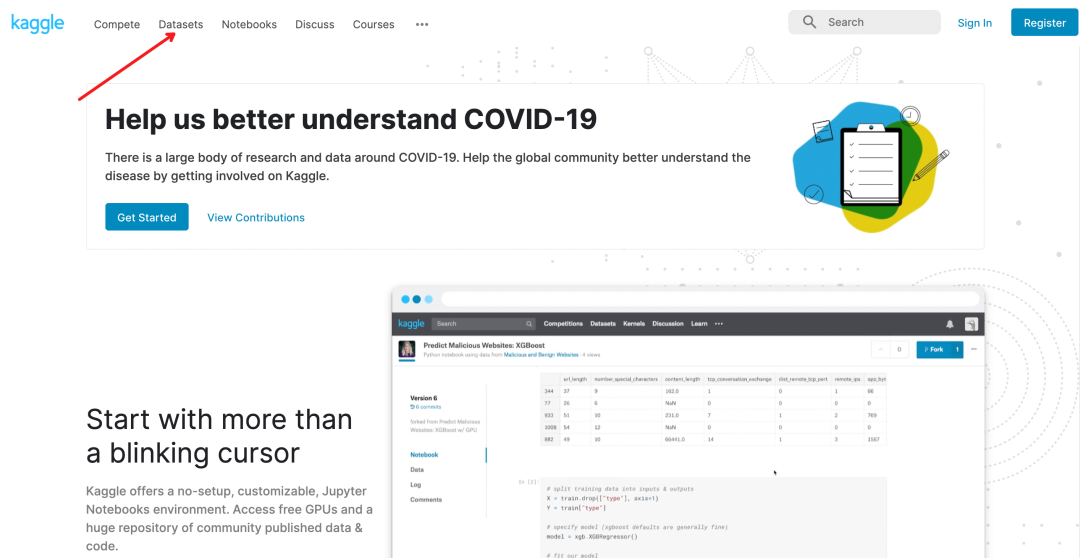
- 写爬虫,爬各大网站的图片数据,然后使用自己的接口清洗或者人工标注;
- 将需求提交给数据标注团队,花经费标注数据。
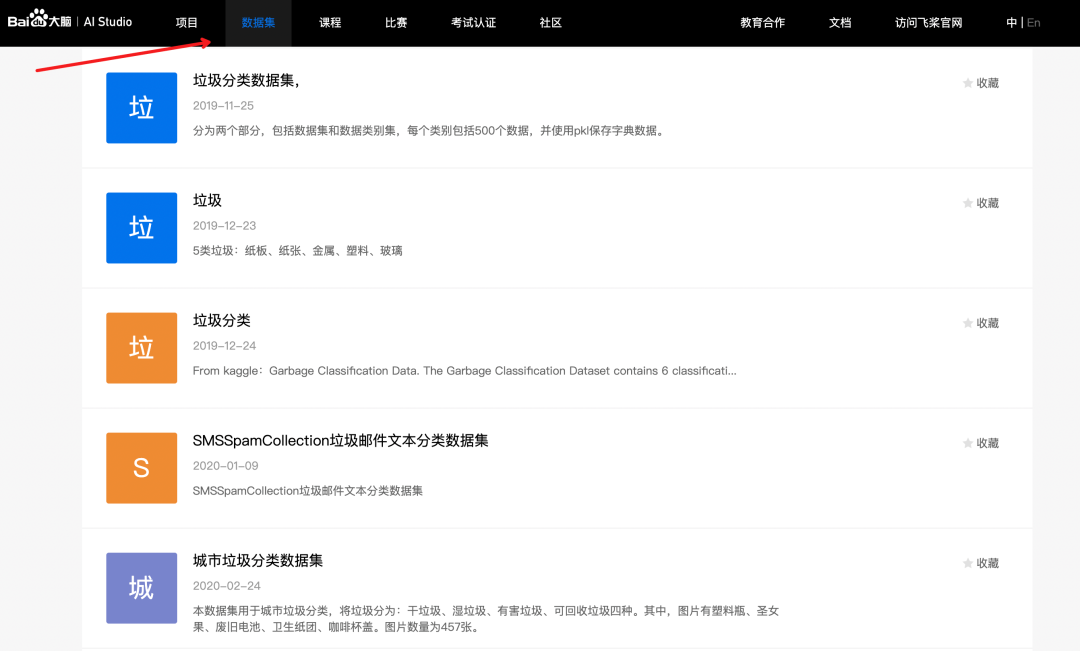
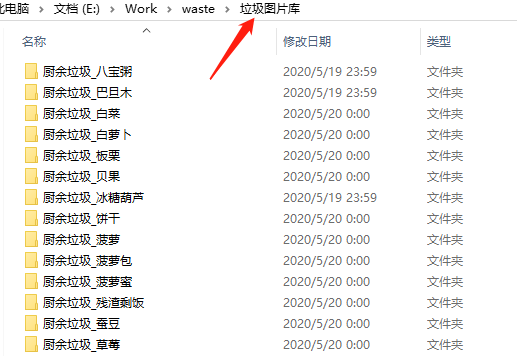
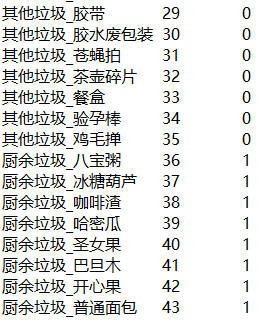
- 最后一个方法,就得碰运气了。翻论文,找公开数据集,或者去 AI 比赛网站或者 AI 开放平台碰碰运气。
4
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
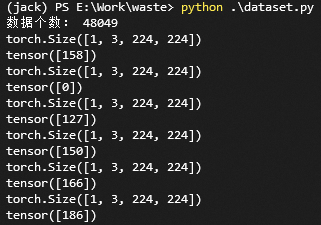
<span class="code-snippet_outer">import torch</span></code><code><span class="code-snippet_outer">from PIL import Image</span></code><code><span class="code-snippet_outer">import os</span></code><code><span class="code-snippet_outer">import glob</span></code><code><span class="code-snippet_outer">from torch.utils.data import Dataset</span></code><code><span class="code-snippet_outer">import random</span></code><code><span class="code-snippet_outer">import torchvision.transforms as transforms </span></code><code><span class="code-snippet_outer">from PIL import ImageFile</span></code><code><span class="code-snippet_outer">ImageFile.LOAD_TRUNCATED_IMAGES = True</span></code><code> </code><code><span class="code-snippet_outer">class Garbage_Loader(Dataset):</span></code><code><span class="code-snippet_outer"> def __init__(self, txt_path, train_flag=True):</span></code><code><span class="code-snippet_outer"> self.imgs_info = self.get_images(txt_path)</span></code><code><span class="code-snippet_outer"> self.train_flag = train_flag</span></code><code> </code><code><span class="code-snippet_outer"> self.train_tf = transforms.Compose([</span></code><code><span class="code-snippet_outer"> transforms.Resize(224),</span></code><code><span class="code-snippet_outer"> transforms.RandomHorizontalFlip(),</span></code><code><span class="code-snippet_outer"> transforms.RandomVerticalFlip(),</span></code><code><span class="code-snippet_outer"> transforms.ToTensor(),</span></code><code> </code><code><span class="code-snippet_outer"> ])</span></code><code><span class="code-snippet_outer"> self.val_tf = transforms.Compose([</span></code><code><span class="code-snippet_outer"> transforms.Resize(224),</span></code><code><span class="code-snippet_outer"> transforms.ToTensor(),</span></code><code><span class="code-snippet_outer"> ])</span></code><code> </code><code><span class="code-snippet_outer"> def get_images(self, txt_path):</span></code><code><span class="code-snippet_outer"> with open(txt_path, 'r', encoding='utf-8') as f:</span></code><code><span class="code-snippet_outer"> imgs_info = f.readlines()</span></code><code><span class="code-snippet_outer"> imgs_info = list(map(lambda x:x.strip().split('\t'), imgs_info))</span></code><code><span class="code-snippet_outer"> return imgs_info</span></code><code> </code><code><span class="code-snippet_outer"> def padding_black(self, img):</span></code><code> </code><code><span class="code-snippet_outer"> w, h = img.size</span></code><code> </code><code><span class="code-snippet_outer"> scale = 224. / max(w, h)</span></code><code><span class="code-snippet_outer"> img_fg = img.resize([int(x) for x in [w * scale, h * scale]])</span></code><code> </code><code><span class="code-snippet_outer"> size_fg = img_fg.size</span></code><code><span class="code-snippet_outer"> size_bg = 224</span></code><code> </code><code><span class="code-snippet_outer"> img_bg = Image.new("RGB", (size_bg, size_bg))</span></code><code> </code><code><span class="code-snippet_outer"> img_bg.paste(img_fg, ((size_bg - size_fg[0]) // 2,</span></code><code><span class="code-snippet_outer"> (size_bg - size_fg[1]) // 2))</span></code><code> </code><code><span class="code-snippet_outer"> img = img_bg</span></code><code><span class="code-snippet_outer"> return img</span></code><code> </code><code><span class="code-snippet_outer"> def __getitem__(self, index):</span></code><code><span class="code-snippet_outer"> img_path, label = self.imgs_info[index]</span></code><code><span class="code-snippet_outer"> img = Image.open(img_path)</span></code><code><span class="code-snippet_outer"> img = img.convert('RGB')</span></code><code><span class="code-snippet_outer"> img = self.padding_black(img)</span></code><code><span class="code-snippet_outer"> if self.train_flag:</span></code><code><span class="code-snippet_outer"> img = self.train_tf(img)</span></code><code><span class="code-snippet_outer"> else:</span></code><code><span class="code-snippet_outer"> img = self.val_tf(img)</span></code><code><span class="code-snippet_outer"> label = int(label)</span></code><code> </code><code><span class="code-snippet_outer"> return img, label</span></code><code> </code><code><span class="code-snippet_outer"> def __len__(self):</span></code><code><span class="code-snippet_outer"> return len(self.imgs_info)</span></code><code> </code><code> </code><code><span class="code-snippet_outer">if __name__ == "__main__":</span></code><code><span class="code-snippet_outer"> train_dataset = Garbage_Loader("train.txt", True)</span></code><code><span class="code-snippet_outer"> print("数据个数:", len(train_dataset))</span></code><code><span class="code-snippet_outer"> train_loader = torch.utils.data.DataLoader(dataset=train_dataset,</span></code><code><span class="code-snippet_outer"> batch_size=1, </span></code><code><span class="code-snippet_outer"> shuffle=True)</span></code><code><span class="code-snippet_outer"> for image, label in train_loader:</span></code><code><span class="code-snippet_outer"> print(image.shape)</span></code><code><span class="code-snippet_outer"> print(label)</span> |
5
创建 train.py 文件,编写如下代码:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
<span class="code-snippet_outer"><span class="code-snippet__keyword">from</span> dataset <span class="code-snippet__keyword">import</span> Garbage_Loader</span></code><code><span class="code-snippet_outer"><span class="code-snippet__keyword">from</span> torch.utils.data <span class="code-snippet__keyword">import</span> DataLoader</span></code><code><span class="code-snippet_outer"><span class="code-snippet__keyword">from</span> torchvision <span class="code-snippet__keyword">import</span> models</span></code><code><span class="code-snippet_outer"><span class="code-snippet__keyword">import</span> torch.nn <span class="code-snippet__keyword">as</span> nn</span></code><code><span class="code-snippet_outer"><span class="code-snippet__keyword">import</span> torch.optim <span class="code-snippet__keyword">as</span> optim</span></code><code><span class="code-snippet_outer"><span class="code-snippet__keyword">import</span> torch</span></code><code><span class="code-snippet_outer"><span class="code-snippet__keyword">import</span> time</span></code><code><span class="code-snippet_outer"><span class="code-snippet__keyword">import</span> os</span></code><code><span class="code-snippet_outer"><span class="code-snippet__keyword">import</span> shutil</span></code><code><span class="code-snippet_outer">os.environ[<span class="code-snippet__string">"CUDA_VISIBLE_DEVICES"</span>] = <span class="code-snippet__string">"0"</span></span></code><code> </code><code><span class="code-snippet_outer"><span class="code-snippet__string">"""</span></span></code><code><span class="code-snippet_outer"> Author : Jack Cui</span></code><code><span class="code-snippet_outer"> Wechat : https://mp.weixin.qq.com/s/OCWwRVDFNslIuKyiCVUoTA</span></code><code><span class="code-snippet_outer">"""</span></code><code> </code><code><span class="code-snippet_outer"><span class="code-snippet__keyword">from</span> tensorboardX <span class="code-snippet__keyword">import</span> SummaryWriter</span></code><code> </code><code><span class="code-snippet_outer"><span class="code-snippet__function"><span class="code-snippet__keyword">def</span> <span class="code-snippet__title">accuracy</span><span class="code-snippet__params">(output, target, topk=(<span class="code-snippet__number">1</span>,))</span>:</span></span></code><code><span class="code-snippet_outer"> <span class="code-snippet__string">"""</span></span></code><code><span class="code-snippet_outer"> 计算topk的准确率</span></code><code><span class="code-snippet_outer"> """</span></code><code><span class="code-snippet_outer"> <span class="code-snippet__keyword">with</span> torch.no_grad():</span></code><code><span class="code-snippet_outer"> maxk = max(topk)</span></code><code><span class="code-snippet_outer"> batch_size = target.size(<span class="code-snippet__number">0</span>)</span></code><code> </code><code><span class="code-snippet_outer"> _, pred = output.topk(maxk, <span class="code-snippet__number">1</span>, <span class="code-snippet__keyword">True</span>, <span class="code-snippet__keyword">True</span>)</span></code><code><span class="code-snippet_outer"> pred = pred.t()</span></code><code><span class="code-snippet_outer"> correct = pred.eq(target.view(<span class="code-snippet__number">1</span>, <span class="code-snippet__number">-1</span>).expand_as(pred))</span></code><code> </code><code><span class="code-snippet_outer"> class_to = pred[<span class="code-snippet__number">0</span>].cpu().numpy()</span></code><code> </code><code><span class="code-snippet_outer"> res = []</span></code><code><span class="code-snippet_outer"> <span class="code-snippet__keyword">for</span> k <span class="code-snippet__keyword">in</span> topk:</span></code><code><span class="code-snippet_outer"> correct_k = correct[:k].view(<span class="code-snippet__number">-1</span>).float().sum(<span class="code-snippet__number">0</span>, keepdim=<span class="code-snippet__keyword">True</span>)</span></code><code><span class="code-snippet_outer"> res.append(correct_k.mul_(<span class="code-snippet__number">100.0</span> / batch_size))</span></code><code><span class="code-snippet_outer"> <span class="code-snippet__keyword">return</span> res, class_to</span></code><code> </code><code><span class="code-snippet_outer"><span class="code-snippet__function"><span class="code-snippet__keyword">def</span> <span class="code-snippet__title">save_checkpoint</span><span class="code-snippet__params">(state, is_best, filename=<span class="code-snippet__string">'checkpoint.pth.tar'</span>)</span>:</span></span></code><code><span class="code-snippet_outer"> <span class="code-snippet__string">"""</span></span></code><code><span class="code-snippet_outer"> 根据 is_best 存模型,一般保存 valid acc 最好的模型</span></code><code><span class="code-snippet_outer"> """</span></code><code><span class="code-snippet_outer"> torch.save(state, filename)</span></code><code><span class="code-snippet_outer"> <span class="code-snippet__keyword">if</span> is_best:</span></code><code><span class="code-snippet_outer"> shutil.copyfile(filename, <span class="code-snippet__string">'model_best_'</span> + filename)</span></code><code> </code><code><span class="code-snippet_outer"><span class="code-snippet__function"><span class="code-snippet__keyword">def</span> <span class="code-snippet__title">train</span><span class="code-snippet__params">(train_loader, model, criterion, optimizer, epoch, writer)</span>:</span></span></code><code><span class="code-snippet_outer"> <span class="code-snippet__string">"""</span></span></code><code><span class="code-snippet_outer"> 训练代码</span></code><code><span class="code-snippet_outer"> 参数:</span></code><code><span class="code-snippet_outer"> train_loader - 训练集的 DataLoader</span></code><code><span class="code-snippet_outer"> model - 模型</span></code><code><span class="code-snippet_outer"> criterion - 损失函数</span></code><code><span class="code-snippet_outer"> optimizer - 优化器</span></code><code><span class="code-snippet_outer"> epoch - 进行第几个 epoch</span></code><code><span class="code-snippet_outer"> writer - 用于写 tensorboardX </span></code><code><span class="code-snippet_outer"> """</span></code><code><span class="code-snippet_outer"> batch_time = AverageMeter()</span></code><code><span class="code-snippet_outer"> data_time = AverageMeter()</span></code><code><span class="code-snippet_outer"> losses = AverageMeter()</span></code><code><span class="code-snippet_outer"> top1 = AverageMeter()</span></code><code><span class="code-snippet_outer"> top5 = AverageMeter()</span></code><code> </code><code> </code><code><span class="code-snippet_outer"> model.train()</span></code><code> </code><code><span class="code-snippet_outer"> end = time.time()</span></code><code><span class="code-snippet_outer"> <span class="code-snippet__keyword">for</span> i, (input, target) <span class="code-snippet__keyword">in</span> enumerate(train_loader):</span></code><code> </code><code><span class="code-snippet_outer"> data_time.update(time.time() - end)</span></code><code> </code><code><span class="code-snippet_outer"> input = input.cuda()</span></code><code><span class="code-snippet_outer"> target = target.cuda()</span></code><code> </code><code> </code><code><span class="code-snippet_outer"> output = model(input)</span></code><code><span class="code-snippet_outer"> loss = criterion(output, target)</span></code><code> </code><code> </code><code><span class="code-snippet_outer"> [prec1, prec5], class_to = accuracy(output, target, topk=(<span class="code-snippet__number">1</span>, <span class="code-snippet__number">5</span>))</span></code><code><span class="code-snippet_outer"> losses.update(loss.item(), input.size(<span class="code-snippet__number">0</span>))</span></code><code><span class="code-snippet_outer"> top1.update(prec1[<span class="code-snippet__number">0</span>], input.size(<span class="code-snippet__number">0</span>))</span></code><code><span class="code-snippet_outer"> top5.update(prec5[<span class="code-snippet__number">0</span>], input.size(<span class="code-snippet__number">0</span>))</span></code><code> </code><code> </code><code><span class="code-snippet_outer"> optimizer.zero_grad()</span></code><code><span class="code-snippet_outer"> loss.backward()</span></code><code><span class="code-snippet_outer"> optimizer.step()</span></code><code> </code><code> </code><code><span class="code-snippet_outer"> batch_time.update(time.time() - end)</span></code><code><span class="code-snippet_outer"> end = time.time()</span></code><code> </code><code><span class="code-snippet_outer"> <span class="code-snippet__keyword">if</span> i % <span class="code-snippet__number">10</span> == <span class="code-snippet__number">0</span>:</span></code><code><span class="code-snippet_outer"> print(<span class="code-snippet__string">'Epoch: [{0}][{1}/{2}]\t'</span></span></code><code><span class="code-snippet_outer"> <span class="code-snippet__string">'Time {batch_time.val:.3f} ({batch_time.avg:.3f})\t'</span></span></code><code><span class="code-snippet_outer"> <span class="code-snippet__string">'Data {data_time.val:.3f} ({data_time.avg:.3f})\t'</span></span></code><code><span class="code-snippet_outer"> <span class="code-snippet__string">'Loss {loss.val:.4f} ({loss.avg:.4f})\t'</span></span></code><code><span class="code-snippet_outer"> <span class="code-snippet__string">'Prec@1 {top1.val:.3f} ({top1.avg:.3f})\t'</span></span></code><code><span class="code-snippet_outer"> <span class="code-snippet__string">'Prec@5 {top5.val:.3f} ({top5.avg:.3f})'</span>.format(</span></code><code><span class="code-snippet_outer"> epoch, i, len(train_loader), batch_time=batch_time,</span></code><code><span class="code-snippet_outer"> data_time=data_time, loss=losses, top1=top1, top5=top5))</span></code><code><span class="code-snippet_outer"> writer.add_scalar(<span class="code-snippet__string">'loss/train_loss'</span>, losses.val, global_step=epoch)</span></code><code> </code><code><span class="code-snippet_outer"><span class="code-snippet__function"><span class="code-snippet__keyword">def</span> <span class="code-snippet__title">validate</span><span class="code-snippet__params">(val_loader, model, criterion, epoch, writer, phase=<span class="code-snippet__string">"VAL"</span>)</span>:</span></span></code><code><span class="code-snippet_outer"> <span class="code-snippet__string">"""</span></span></code><code><span class="code-snippet_outer"> 验证代码</span></code><code><span class="code-snippet_outer"> 参数:</span></code><code><span class="code-snippet_outer"> val_loader - 验证集的 DataLoader</span></code><code><span class="code-snippet_outer"> model - 模型</span></code><code><span class="code-snippet_outer"> criterion - 损失函数</span></code><code><span class="code-snippet_outer"> epoch - 进行第几个 epoch</span></code><code><span class="code-snippet_outer"> writer - 用于写 tensorboardX </span></code><code><span class="code-snippet_outer"> """</span></code><code><span class="code-snippet_outer"> batch_time = AverageMeter()</span></code><code><span class="code-snippet_outer"> losses = AverageMeter()</span></code><code><span class="code-snippet_outer"> top1 = AverageMeter()</span></code><code><span class="code-snippet_outer"> top5 = AverageMeter()</span></code><code> </code><code> </code><code><span class="code-snippet_outer"> model.eval()</span></code><code> </code><code><span class="code-snippet_outer"> <span class="code-snippet__keyword">with</span> torch.no_grad():</span></code><code><span class="code-snippet_outer"> end = time.time()</span></code><code><span class="code-snippet_outer"> <span class="code-snippet__keyword">for</span> i, (input, target) <span class="code-snippet__keyword">in</span> enumerate(val_loader):</span></code><code><span class="code-snippet_outer"> input = input.cuda()</span></code><code><span class="code-snippet_outer"> target = target.cuda()</span></code><code> </code><code><span class="code-snippet_outer"> output = model(input)</span></code><code><span class="code-snippet_outer"> loss = criterion(output, target)</span></code><code> </code><code> </code><code><span class="code-snippet_outer"> [prec1, prec5], class_to = accuracy(output, target, topk=(<span class="code-snippet__number">1</span>, <span class="code-snippet__number">5</span>))</span></code><code><span class="code-snippet_outer"> losses.update(loss.item(), input.size(<span class="code-snippet__number">0</span>))</span></code><code><span class="code-snippet_outer"> top1.update(prec1[<span class="code-snippet__number">0</span>], input.size(<span class="code-snippet__number">0</span>))</span></code><code><span class="code-snippet_outer"> top5.update(prec5[<span class="code-snippet__number">0</span>], input.size(<span class="code-snippet__number">0</span>))</span></code><code> </code><code> </code><code><span class="code-snippet_outer"> batch_time.update(time.time() - end)</span></code><code><span class="code-snippet_outer"> end = time.time()</span></code><code> </code><code><span class="code-snippet_outer"> <span class="code-snippet__keyword">if</span> i % <span class="code-snippet__number">10</span> == <span class="code-snippet__number">0</span>:</span></code><code><span class="code-snippet_outer"> print(<span class="code-snippet__string">'Test-{0}: [{1}/{2}]\t'</span></span></code><code><span class="code-snippet_outer"> <span class="code-snippet__string">'Time {batch_time.val:.3f} ({batch_time.avg:.3f})\t'</span></span></code><code><span class="code-snippet_outer"> <span class="code-snippet__string">'Loss {loss.val:.4f} ({loss.avg:.4f})\t'</span></span></code><code><span class="code-snippet_outer"> <span class="code-snippet__string">'Prec@1 {top1.val:.3f} ({top1.avg:.3f})\t'</span></span></code><code><span class="code-snippet_outer"> <span class="code-snippet__string">'Prec@5 {top5.val:.3f} ({top5.avg:.3f})'</span>.format(</span></code><code><span class="code-snippet_outer"> phase, i, len(val_loader),</span></code><code><span class="code-snippet_outer"> batch_time=batch_time,</span></code><code><span class="code-snippet_outer"> loss=losses,</span></code><code><span class="code-snippet_outer"> top1=top1, top5=top5))</span></code><code> </code><code><span class="code-snippet_outer"> print(<span class="code-snippet__string">' * {} Prec@1 {top1.avg:.3f} Prec@5 {top5.avg:.3f}'</span></span></code><code><span class="code-snippet_outer"> .format(phase, top1=top1, top5=top5))</span></code><code><span class="code-snippet_outer"> writer.add_scalar(<span class="code-snippet__string">'loss/valid_loss'</span>, losses.val, global_step=epoch)</span></code><code><span class="code-snippet_outer"> <span class="code-snippet__keyword">return</span> top1.avg, top5.avg</span></code><code> </code><code><span class="code-snippet_outer"><span class="code-snippet__class"><span class="code-snippet__keyword">class</span> <span class="code-snippet__title">AverageMeter</span><span class="code-snippet__params">(object)</span>:</span></span></code><code><span class="code-snippet_outer"> <span class="code-snippet__string">"""Computes and stores the average and current value"""</span></span></code><code><span class="code-snippet_outer"> <span class="code-snippet__function"><span class="code-snippet__keyword">def</span> <span class="code-snippet__title">__init__</span><span class="code-snippet__params">(self)</span>:</span></span></code><code><span class="code-snippet_outer"> self.reset()</span></code><code> </code><code><span class="code-snippet_outer"> <span class="code-snippet__function"><span class="code-snippet__keyword">def</span> <span class="code-snippet__title">reset</span><span class="code-snippet__params">(self)</span>:</span></span></code><code><span class="code-snippet_outer"> self.val = <span class="code-snippet__number">0</span></span></code><code><span class="code-snippet_outer"> self.avg = <span class="code-snippet__number">0</span></span></code><code><span class="code-snippet_outer"> self.sum = <span class="code-snippet__number">0</span></span></code><code><span class="code-snippet_outer"> self.count = <span class="code-snippet__number">0</span></span></code><code> </code><code><span class="code-snippet_outer"> <span class="code-snippet__function"><span class="code-snippet__keyword">def</span> <span class="code-snippet__title">update</span><span class="code-snippet__params">(self, val, n=<span class="code-snippet__number">1</span>)</span>:</span></span></code><code><span class="code-snippet_outer"> self.val = val</span></code><code><span class="code-snippet_outer"> self.sum += val * n</span></code><code><span class="code-snippet_outer"> self.count += n</span></code><code><span class="code-snippet_outer"> self.avg = self.sum / self.count</span></code><code> </code><code><span class="code-snippet_outer"><span class="code-snippet__keyword">if</span> __name__ == <span class="code-snippet__string">"__main__"</span>:</span></code><code> </code><code><span class="code-snippet_outer"> train_dir_list = <span class="code-snippet__string">'train.txt'</span></span></code><code><span class="code-snippet_outer"> valid_dir_list = <span class="code-snippet__string">'val.txt'</span></span></code><code><span class="code-snippet_outer"> batch_size = <span class="code-snippet__number">64</span></span></code><code><span class="code-snippet_outer"> epochs = <span class="code-snippet__number">80</span></span></code><code><span class="code-snippet_outer"> num_classes = <span class="code-snippet__number">214</span></span></code><code><span class="code-snippet_outer"> train_data = Garbage_Loader(train_dir_list, train_flag=<span class="code-snippet__keyword">True</span>)</span></code><code><span class="code-snippet_outer"> valid_data = Garbage_Loader(valid_dir_list, train_flag=<span class="code-snippet__keyword">False</span>)</span></code><code><span class="code-snippet_outer"> train_loader = DataLoader(dataset=train_data, num_workers=<span class="code-snippet__number">8</span>, pin_memory=<span class="code-snippet__keyword">True</span>, batch_size=batch_size, shuffle=<span class="code-snippet__keyword">True</span>)</span></code><code><span class="code-snippet_outer"> valid_loader = DataLoader(dataset=valid_data, num_workers=<span class="code-snippet__number">8</span>, pin_memory=<span class="code-snippet__keyword">True</span>, batch_size=batch_size)</span></code><code><span class="code-snippet_outer"> train_data_size = len(train_data)</span></code><code><span class="code-snippet_outer"> print(<span class="code-snippet__string">'训练集数量:%d'</span> % train_data_size)</span></code><code><span class="code-snippet_outer"> valid_data_size = len(valid_data)</span></code><code><span class="code-snippet_outer"> print(<span class="code-snippet__string">'验证集数量:%d'</span> % valid_data_size)</span></code><code> </code><code><span class="code-snippet_outer"> model = models.resnet50(pretrained=<span class="code-snippet__keyword">True</span>)</span></code><code><span class="code-snippet_outer"> fc_inputs = model.fc.in_features</span></code><code><span class="code-snippet_outer"> model.fc = nn.Linear(fc_inputs, num_classes)</span></code><code><span class="code-snippet_outer"> model = model.cuda()</span></code><code> </code><code><span class="code-snippet_outer"> lr_init = <span class="code-snippet__number">0.0001</span></span></code><code><span class="code-snippet_outer"> lr_stepsize = <span class="code-snippet__number">20</span></span></code><code><span class="code-snippet_outer"> weight_decay = <span class="code-snippet__number">0.001</span></span></code><code><span class="code-snippet_outer"> criterion = nn.CrossEntropyLoss().cuda()</span></code><code><span class="code-snippet_outer"> optimizer = optim.Adam(model.parameters(), lr=lr_init, weight_decay=weight_decay)</span></code><code><span class="code-snippet_outer"> scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=lr_stepsize, gamma=<span class="code-snippet__number">0.1</span>)</span></code><code> </code><code><span class="code-snippet_outer"> writer = SummaryWriter(<span class="code-snippet__string">'runs/resnet50'</span>)</span></code><code> </code><code><span class="code-snippet_outer"> best_prec1 = <span class="code-snippet__number">0</span></span></code><code><span class="code-snippet_outer"> <span class="code-snippet__keyword">for</span> epoch <span class="code-snippet__keyword">in</span> range(epochs):</span></code><code><span class="code-snippet_outer"> scheduler.step()</span></code><code><span class="code-snippet_outer"> train(train_loader, model, criterion, optimizer, epoch, writer)</span></code><code> </code><code><span class="code-snippet_outer"> valid_prec1, valid_prec5 = validate(valid_loader, model, criterion, epoch, writer, phase=<span class="code-snippet__string">"VAL"</span>)</span></code><code><span class="code-snippet_outer"> is_best = valid_prec1 > best_prec1</span></code><code><span class="code-snippet_outer"> best_prec1 = max(valid_prec1, best_prec1)</span></code><code><span class="code-snippet_outer"> save_checkpoint({</span></code><code><span class="code-snippet_outer"> <span class="code-snippet__string">'epoch'</span>: epoch + <span class="code-snippet__number">1</span>,</span></code><code><span class="code-snippet_outer"> <span class="code-snippet__string">'arch'</span>: <span class="code-snippet__string">'resnet50'</span>,</span></code><code><span class="code-snippet_outer"> <span class="code-snippet__string">'state_dict'</span>: model.state_dict(),</span></code><code><span class="code-snippet_outer"> <span class="code-snippet__string">'best_prec1'</span>: best_prec1,</span></code><code><span class="code-snippet_outer"> <span class="code-snippet__string">'optimizer'</span> : optimizer.state_dict(),</span></code><code><span class="code-snippet_outer"> }, is_best,</span></code><code><span class="code-snippet_outer"> filename=<span class="code-snippet__string">'checkpoint_resnet50.pth.tar'</span>)</span></code><code><span class="code-snippet_outer"> writer.close()</span> |
代码并不复杂,网络结构直接使 torchvision 的 ResNet50 模型,并且采用 ResNet50 的预训练模型。算法采用交叉熵损失函数,优化器选择 Adam,并采用 StepLR 进行学习率衰减。
保存模型的策略是选择在验证集准确率最高的模型。
batch size 设为 64,GPU 显存大约占 8G,显存不够的,可以调整 batch size 大小。
模型训练完成,就可以写测试代码了,看下效果吧!
创建 infer.py 文件,编写如下代码:
|
1 2 |
<span class="code-snippet_outer"><span class="code-snippet__keyword">from</span> dataset <span class="code-snippet__keyword">import</span> Garbage_Loader</span></code><code><span class="code-snippet_outer"><span class="code-snippet__keyword">from</span> torch.utils.data <span class="code-snippet__keyword">import</span> DataLoader</span></code><code><span class="code-snippet_outer"><span class="code-snippet__keyword">import</span> torchvision.transforms <span class="code-snippet__keyword">as</span> transforms </span></code><code><span class="code-snippet_outer"><span class="code-snippet__keyword">from</span> torchvision <span class="code-snippet__keyword">import</span> models</span></code><code><span class="code-snippet_outer"><span class="code-snippet__keyword">import</span> torch.nn <span class="code-snippet__keyword">as</span> nn</span></code><code><span class="code-snippet_outer"><span class="code-snippet__keyword">import</span> torch</span></code><code><span class="code-snippet_outer"><span class="code-snippet__keyword">import</span> os</span></code><code><span class="code-snippet_outer"><span class="code-snippet__keyword">import</span> numpy <span class="code-snippet__keyword">as</span> np</span></code><code><span class="code-snippet_outer"><span class="code-snippet__keyword">import</span> matplotlib.pyplot <span class="code-snippet__keyword">as</span> plt</span></code><code></code><code><span class="code-snippet_outer">os.environ[<span class="code-snippet__string">"CUDA_VISIBLE_DEVICES"</span>] = <span class="code-snippet__string">"0"</span></span></code><code> </code><code><span class="code-snippet_outer"><span class="code-snippet__function"><span class="code-snippet__keyword">def</span> <span class="code-snippet__title">softmax</span><span class="code-snippet__params">(x)</span>:</span></span></code><code><span class="code-snippet_outer"> exp_x = np.exp(x)</span></code><code><span class="code-snippet_outer"> softmax_x = exp_x / np.sum(exp_x, <span class="code-snippet__number">0</span>)</span></code><code><span class="code-snippet_outer"> <span class="code-snippet__keyword">return</span> softmax_x</span></code><code> </code><code><span class="code-snippet_outer"><span class="code-snippet__keyword">with</span> open(<span class="code-snippet__string">'dir_label.txt'</span>, <span class="code-snippet__string">'r'</span>, encoding=<span class="code-snippet__string">'utf-8'</span>) <span class="code-snippet__keyword">as</span> f:</span></code><code><span class="code-snippet_outer"> labels = f.readlines()</span></code><code><span class="code-snippet_outer"> labels = list(map(<span class="code-snippet__keyword">lambda</span> x:x.strip().split(<span class="code-snippet__string">'\t'</span>), labels))</span></code><code> </code><code><span class="code-snippet_outer"><span class="code-snippet__keyword">if</span> __name__ == <span class="code-snippet__string">"__main__"</span>:</span></code><code><span class="code-snippet_outer"> test_list = <span class="code-snippet__string">'test.txt'</span></span></code><code><span class="code-snippet_outer"> test_data = Garbage_Loader(test_list, train_flag=<span class="code-snippet__keyword">False</span>)</span></code><code><span class="code-snippet_outer"> test_loader = DataLoader(dataset=test_data, num_workers=<span class="code-snippet__number">1</span>, pin_memory=<span class="code-snippet__keyword">True</span>, batch_size=<span class="code-snippet__number">1</span>)</span></code><code><span class="code-snippet_outer"> model = models.resnet50(pretrained=<span class="code-snippet__keyword">False</span>)</span></code><code><span class="code-snippet_outer"> fc_inputs = model.fc.in_features</span></code><code><span class="code-snippet_outer"> model.fc = nn.Linear(fc_inputs, <span class="code-snippet__number">214</span>)</span></code><code><span class="code-snippet_outer"> model = model.cuda()</span></code><code> </code><code><span class="code-snippet_outer"> checkpoint = torch.load(<span class="code-snippet__string">'model_best_checkpoint_resnet50.pth.tar'</span>)</span></code><code><span class="code-snippet_outer"> model.load_state_dict(checkpoint[<span class="code-snippet__string">'state_dict'</span>])</span></code><code><span class="code-snippet_outer"> model.eval()</span></code><code><span class="code-snippet_outer"> <span class="code-snippet__keyword">for</span> i, (image, label) <span class="code-snippet__keyword">in</span> enumerate(test_loader):</span></code><code><span class="code-snippet_outer"> src = image.numpy()</span></code><code><span class="code-snippet_outer"> src = src.reshape(<span class="code-snippet__number">3</span>, <span class="code-snippet__number">224</span>, <span class="code-snippet__number">224</span>)</span></code><code><span class="code-snippet_outer"> src = np.transpose(src, (<span class="code-snippet__number">1</span>, <span class="code-snippet__number">2</span>, <span class="code-snippet__number">0</span>))</span></code><code><span class="code-snippet_outer"> image = image.cuda() </span></code><code><span class="code-snippet_outer"> label = label.cuda() </span></code><code><span class="code-snippet_outer"> pred = model(image)</span></code><code><span class="code-snippet_outer"> pred = pred.data.cpu().numpy()[<span class="code-snippet__number">0</span>]</span></code><code><span class="code-snippet_outer"> score = softmax(pred)</span></code><code><span class="code-snippet_outer"> pred_id = np.argmax(score)</span></code><code><span class="code-snippet_outer"> plt.imshow(src)</span></code><code><span class="code-snippet_outer"> print(<span class="code-snippet__string">'预测结果:'</span>, labels[pred_id][<span class="code-snippet__number">0</span>])</span></code><code><span class="code-snippet_outer"> plt.show()</span> |
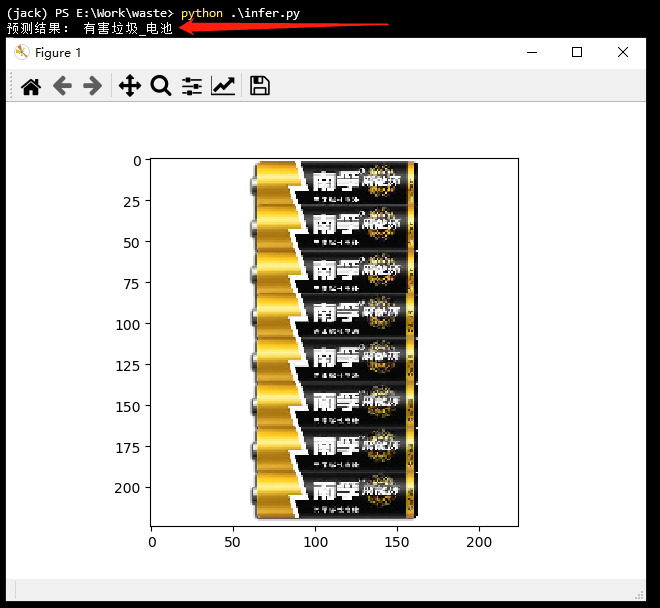
6
- 本文从实战出发,讲解了怎么训练一个自己的「垃圾分类器」。
- baseline 已经提供,提升精度,就是一些细节上的优化了。
 Jack Cui推荐搜索
Jack Cui推荐搜索
::__IHACKLOG_REMOTE_IMAGE_AUTODOWN_BLOCK__::18
点赞加在看,文章更好看
长按二维码向我转账
点赞加在看,文章更好看
::__IHACKLOG_REMOTE_IMAGE_AUTODOWN_BLOCK__::20
受苹果公司新规定影响,微信 iOS 版的赞赏功能被关闭,可通过二维码转账支持公众号。
看一看入口已关闭
在“设置”-“通用”-“发现页管理”打开“看一看”入口



