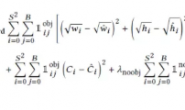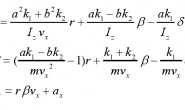【谷歌新论文提出像素递归超分辨率:利用神经网络消灭低分辨率图像】
机器之心编译
参与:吴攀
马赛克有时候是人类实现幸福生活的一大妨碍,谷歌也一直在致力于用技术提升人类的幸福程度。之前机器之心就曾报道过谷歌曾经提出一种提升图像分辨率的技术,参见《消灭所有马赛克,谷歌宣布机器学习图像锐化工具 RAISR》。近日,Google Brain 又在 arXiv 上发布了一篇新论文《Pixel Recursive Super Resolution》,介绍了另一种增强图像分辨率的技术。机器之心对这篇论文进行了简要介绍,论文原文可点击「阅读原文」下载。

摘要:我们提出了一个像素递归超分辨率模型(pixel recursive super resolution model),其能为图像合成逼真的细节同时还能提升它们的分辨率。一张低分辨率图像可能对应多种可能的高分辨率图像,因此使用一个独立于像素的条件模型(conditional model)来对超分辨率过程(super resolution process)建模往往会导致不同细节的平均化——因此造成边缘模糊。相比而言,我们的模型能够基于一张低分辨率输入,通过对高分辨率图像像素的统计依赖(statistical dependencies)的合适建模来表示一个多模态条件分布(multimodal conditional distribution)。我们使用了一种 PixelCNN 架构来定义在自然图像上的强优先(strong prior),并使用了一个深度调节卷积网络(deep conditioning convolutional network)来联合优化这个优先。人类评估表明来自我们提出的模型的样本比强 L2 回归基线更逼近真实的照片。

图 1:我们在一个名人脸部图像数据集上以端到端的方式训练的概率像素递归超分辨率模型(probabilistic pixel recursive super resolution model)的图示。左列是来自测试集的 8×8 的低分辨率输入。中列和右列分别是 32×32 像素的我们的模型的预测结果与真实样本(ground truth)。我们的模型整合了强大的脸部优先以合成逼真的头发和皮肤细节。
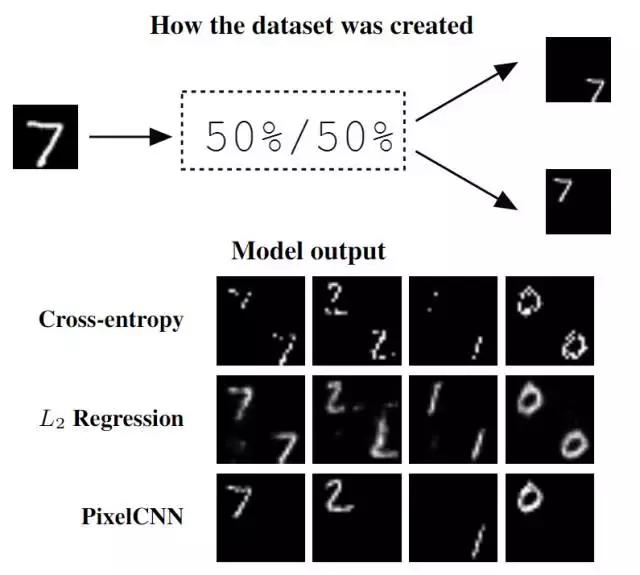
图 2:上图:图片表示了试验数据集(toy dataset)中输入输出对的一种创建方式。下图:在这个数据集上训练的几个算法的预测示例。像素独立的 L2 回归和交叉熵模型没有表现出多模态预测。PixelCNN 输出是随机的,且多个样本时出现在每个角的概率各为 50%。

图 3:我们提出的超分辨率网络包含了一个调节网络(conditioning network)和一个优先网络(prior network)。其中调节网络是一个 CNN,其接收低分辨率图像作为输入,然后输出 logits——预测了每个高分辨率(HR)图像像素的条件对数概率(conditional log-probability)。而优先网络则是一个 PixelCNN,其基于之前的随机预测进行预测(用虚线表示)。该模型的概率分布的计算是在来自优先网络和调节网络的两个 logits 集之和上作为 softmax operator 而实现的。
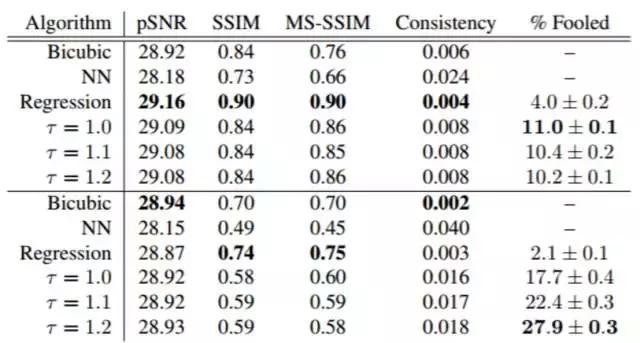
表 1:顶部:在裁切过的 CelebA 测试数据集上,从 8×8 放大到 32×32 后的测试结果。底部:LSUN 卧室。pSNR、SSIM 和 MS-SSIM 测量了样本和 ground truth 之间的图像相似度。Consistency(一致性)表示输入低分辨率图像和下采样样本之间在 [0,1] 尺度上的均方误差(MSE)。% Fooled 表示了在一个众包研究中,算法样本骗过一个人类的常见程度;50% 表示造成了完美的混淆。