图像太大,显存放不下?来看看跑FCN网络的高效方法
作者:Liad Pollak Zuckerman
编译:ronghuaiyang
一种使用全卷积网络的trick,用来跑大尺寸的输入图像。
全卷积(deep neural)网络通常用于计算机视觉任务,如语义分割、超分辨率等。它们的最佳属性之一是,它们适用于任何大小的输入,例如不同大小的图像。然而,在大规模输入(如高分辨率图像或视频)上运行这些网络可能会消耗大量GPU内存。在这篇文章中,我将提供一个简单的方法来缓解这个问题。该算法将GPU内存使用量降低到3-30%。
全卷积网络(从现在开始叫做FCN)是一个仅由卷积层组成的网络。为了简单起见,在这篇文章中,我们将重点讨论图像,但同样的方法也适用于视频或其他类型的数据。
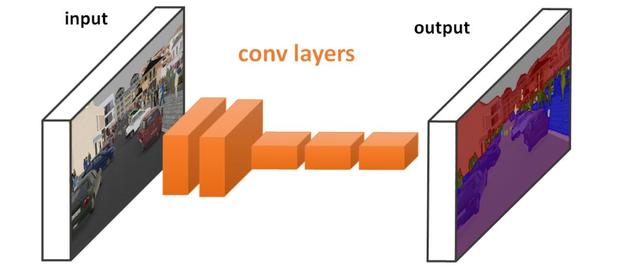
一个全卷积网络做分割
对于图像处理中的许多任务,要求输入和输出图像具有相同的大小是很自然的。这可以通过使用FCNs加上适当的填充来实现。由于这是一个标准的程序,从现在开始,我们将假定它成立。
在这种架构下,输出图像中的每个像素都是对输入图像中相应的patch进行计算的结果。
patch的大小称为网络的感受野(RF)。
这是一个关键点。我们将很快看到算法如何使用这个属性。
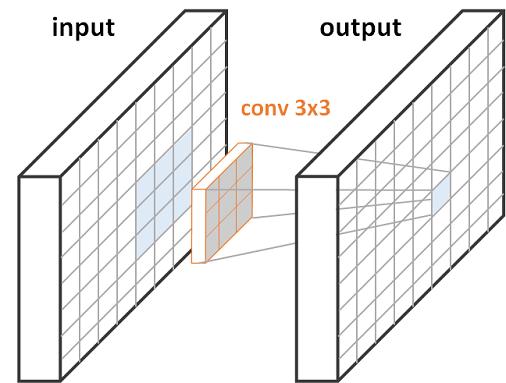
一层使用3×3卷积的FCN,每个像素的输出对应输入图像的3×3的patch

2层的FCN:每层都是3×3卷积,每个输出像素对应5×5大小的输入图像
上面我们可以看到一个(顶部)和两个(底部)3×3 conv层FCNs的图。对于一个层(顶部),右边的蓝色输出像素是对左边的蓝色输入块的计算结果。当有两个层(底部)时,我们在输入和输出之间有一个特征映射。feature map(中间)中的每个绿色像素都是计算超过3×3的绿色输入patch(左边)的结果,就像在单层情况下一样。类似地,每个蓝色输出像素(右)是计算一个蓝色3×3 feature map patch(中)的结果,该patch起源于一个5×5蓝色输入patch(左)。
如前所述,理论上,我们可以将网络应用于任何输入大小。然而,实际上,计算通过网络的前向通道需要在内存中保存大量的特征图,这会耗尽GPU资源。
我在研究视频和3d图像时遇到了这个限制。网络无法在我们的NVIDIA v100 GPU上运行,这导致我开发了这个解决方案。
传统的cnn以全连接的层结束。因此,每个输出像素都是对整个输入进行计算的结果。FCNs不是这样的。正如我们所看到的,只有接收域大小的输入patch影响单个输出像素。因此,要计算单个输出像素,不需要将整个feature map保存在内存中!
换句话说:
我们可以一次计算输出值的一小部分,同时只从输入中传递必要的像素。这大大降低了GPU的内存使用。
让我们来看看下面的例子:
我们的输入是一个28×28的图像,如下图所示。由于内存限制,我们可以通过大小为12×12的网络patch。简单的方法是从原始输入输入12×12个patch(如下图所示),然后使用12×12个输出patch构建28×28个输出图像。

每个输出像素是通过网络的不同patch的结果。例如,橙色像素是传递橙色12x12patch的结果。
不幸的是,这种方法不会产生与同时传递整个28×28输入相同的结果。原因是边界效应。
为了理解这个问题,让我们看看下图中标记的红色像素。周围的红色方块代表感受野,在本例中大小为5×5,并跨越蓝色和橙色斑块。为了正确地计算红色输出像素,我们需要同时计算蓝色和橙色像素。因此,如果我们分别运行蓝色和橙色的patch,就像在naive方法中那样,我们将没有必要的像素来精确地计算它的值。显然,我们需要另一种方式。
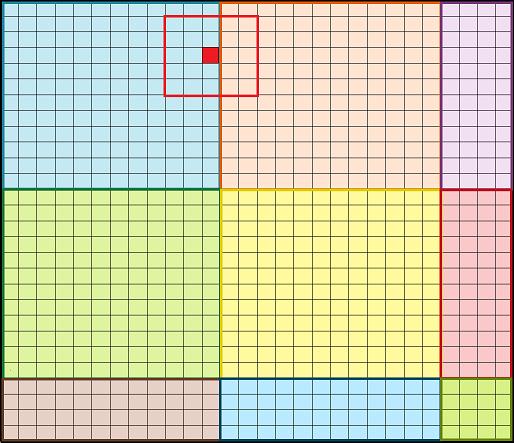
红色 :一个边界上的像素和它周围的感受野
那么我们如何才能让它正确呢?我们可以使用重叠的patch,这样每个5×5的patch都包含在通过网络的12×12的patch中。重叠量应比感受野(RF -1)小1个像素。在我们的例子中,感受野RF=5,所以我们需要4个像素的重叠。下面的动画演示了如何在给定的限制下通过网络传递不同的图像补丁。它显示每个12×12输入patch(边框)在输出(填充)中贡献的像素量更少。例如,蓝色正方形的轮廓要比蓝色像素填充的区域大。
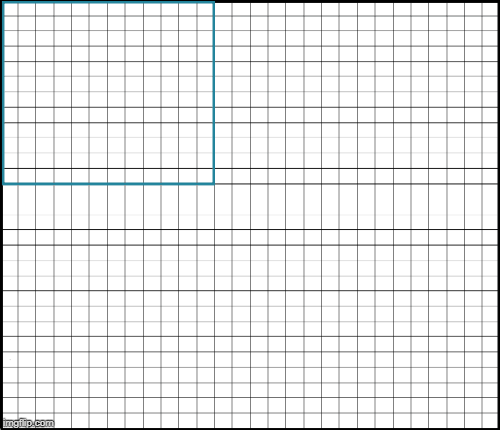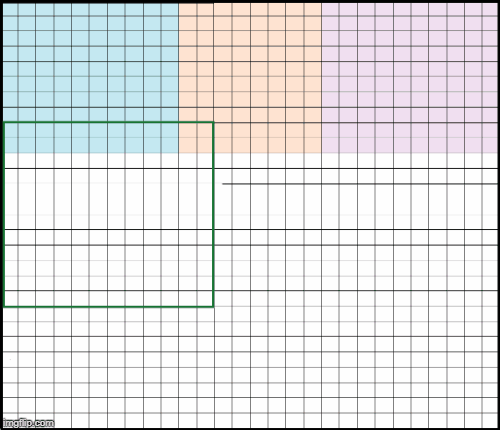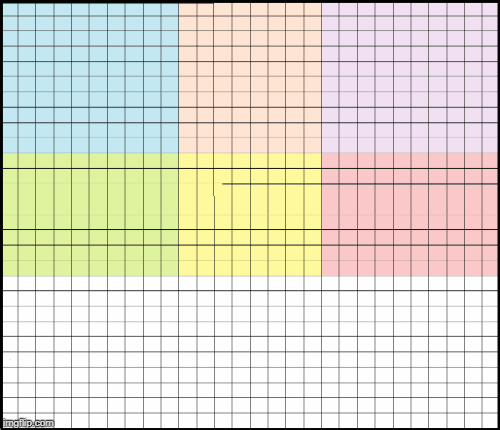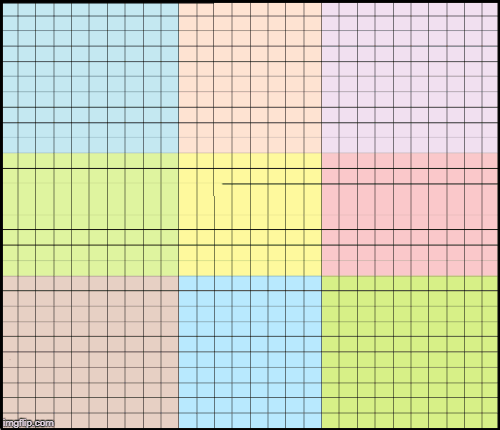
重叠的patch,例如,橙色像素是传递橙色12x12patch的结果。
回到我们标记的红色像素。现在,如下图所示,由于重叠,它可以被正确计算。它周围的5×5的patch完全包含在橙色的12×12的patch中(边框)。
实际上,每个像素都有一个12×12的patch,其中包含了其感受野大小的周围像素。通过这种方式,我们可以确保和运行整个28×28图像的结果是相同的。
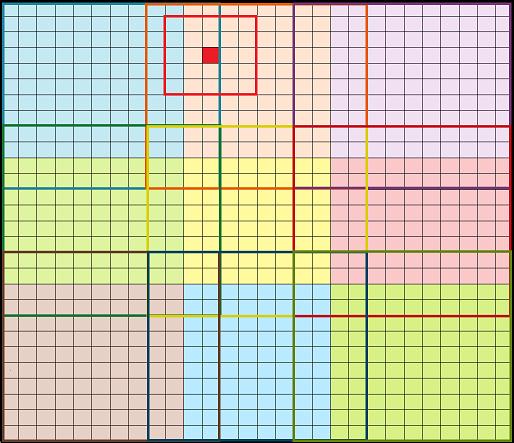
红色 :一个边界上的像素和它周围的感受野
下表给出了一些关于GPU内存使用和运行时间的实验结果。正如承诺的那样,内存消耗将显著减少!
注意:虽然每个图像的运行时间较慢,但使用此方法我们可以并行传递多个图像,因此节省时间。以第三行为例,使用该算法我们可以同时运行13幅图像,与直接运行6幅图像所花费的时间相同。

通过使用patch by patch算法,与标准方法相比,GPU的内存使用减少了67%-97%。
实验在NVIDIA Tesla K80 GPU上进行。
英文原文:
https://towardsdatascience.com/efficient-method-for-running-fully-convolutional-networks-fcns-3174dc6a692b
图像太大,显存放不下?来看看跑FCN网络的高效方法https://m.toutiaocdn.com/i6769532973365592580/?app=news_article×tamp=1591200500&use_new_style=1&req_id=202006040008190100260772131E2B3D73&group_id=6769532973365592580&tt_from=android_share&utm_medium=toutiao_android&utm_campaign=client_share
转载请注明:徐自远的乱七八糟小站 » 图像太大,显存放不下?来看看跑FCN网络的高效方法



