
近年来以快速、准确地机器视觉为基础的技术替代人力检测农产品质量的技术受到了广泛关注。
在这项研究中,我们描述了联合多模式特征袋(JMBoF)分类框架的低等级表示,用于检查收获后干燥大豆种子的外观质量。提取了两类加速的鲁棒特征和L * a * b *颜色特征的空间布局,以表征干大豆种子仁。特征包模型分别用于从以上两个特征生成可视词典描述符。为了准确表示图像特征,我们引入了低秩表示(LRR)方法,从长联合的两种模态字典描述符中消除了冗余信息。多类支持向量机算法用于对联合多模式特征包的编码LRR进行分类。我们在大豆种子图像数据集上验证了JMBoF分类算法。所提出的方法大大优于文献中最先进的单峰袋特征方法,它可能在将来成为收获后干大豆种子分类程序中的一项重要且有价值的技术。
介绍
大豆它富含氨基酸,维生素,矿物质和脂肪,是浓缩蛋白和植物油的最重要来源。
大豆种子质量可以以几种方式来测量
- 包括拉曼光谱
- 近红外光谱
- 太赫兹光谱
- 高效液相色谱法-质谱法
- 毛细管电泳质谱法
- 扫描型电子显微镜
- 核磁共振技术
通过测量大豆种子的化学和营养成分,这些技术可用于区分质量。
这些方法的缺点在于,它耗时且需要复杂的实验预处理,并且不适合检测外观参数。大豆种子产品的品质因数,价格和适销性直接受到外观质量的影响。此外,有缺陷的大豆种子经常引起疾病,无法长成健康的植物。大豆及其制品的精细加工和储存的第一步重要步骤是筛选外观不佳的种子样品。可以使用人和机器视觉技术根据大豆种子的外观对种子进行分级。基于人类视觉的分级方法非常耗时,分离大量种子的速度和效率较低。与其他检测和分析技术相比,基于机器视觉的技术具有无损,低成本,高精度和高效率的特点,因此在食品外观质量评估中备受关注。
近年来,提出了几种基于机器视觉和机器学习技术的人工智能系统,用于检测和判别大豆种子的质量。例如,Ahmad 等。进行了基于知识领域的实验,使用颜色信息对无症状和有症状的大豆种子进行了分类16。Shatadal&Tan训练了使用RGB颜色特征的前馈神经网络,将大豆种子分类为有声,受绿霜破坏和发臭虫破坏的类别。
提取L * a * b *颜色特征,能量,熵和对比度的三个纹理特征以及周长,面积,圆度,伸长率,紧密度,偏心率,椭圆轴比和等效直径的八个形状特征作为BP人工神经网络的输入网络并建立一个三层分类器,以对六个类别进行分类-霉变,虫害,破碎,皮肤损坏,部分侦探和正常大豆粒18。
这些先前的方法使用颜色,形态和质地的整体视觉特征来描述大豆种子。全局特征通常包含大量无效的背景信息,并且使用它们很容易掩盖局部详细信息。无效特征的引入和有效详细判别信息的丢失将不可避免地影响分类模型的性能,从而影响最终识别的准确性。有缺陷的大豆种子特征经常出现在局部图像中,即使在较小的局部范围内也是如此。与使用全局特征描述有缺陷的大豆种子相比,有效的局部图像特征可以用作区分大豆种子质量的关键手段。
近年来,基于特征包模型的低水平局部视觉特征表示的最新技术在对象识别中显示出巨大的潜力。从文档分析方法派生的BOF方法将低级本地图像特征转换为视觉单词特征,以表示图像属性。
过去算法中有使用密集尺度不变特征的BoF来代表小麦籽粒品种或引入了一种支持向量机(SVM)分类器,用于基于尺度不变特征变换(SIFT)BoF视觉词汇对四种重要的南方蔬菜害虫进行分类20。
上述研究仅使用了一种BoF视觉词典,难以充分表达复杂的农业对象。Abozar Nasirahmadi 等。提出了一个特征模型袋,该模型加入了Harris,Harriese-Laplace,Hessian,Hessian-Laplace和最大稳定的极值区域关键点检测器,以及用于对甜和苦杏仁品种进行分类的尺度不变特征变换描述符。尽管已经实施了几种局部特征算法来改善农产品质量检测系统的性能,但是针对大豆种子检测质量的研究很少。
在本文中,作者们打算使用基于BoF的算法来验证大豆种子图像分类的效果。此外,多个特征的简单组合将不可避免地导致特征的冗余以代表图像,并在一定程度上影响特征识别的最终过程中分类器的性能。为了进一步提高智能识别系统的性能,提出了一种低秩表示(LRR)算法在子空间中长而独特的特征中找到最低等级的表示。该方法可以通过在低秩子空间中生成新的低维描述符来有机地合并语义词典的不同类别,并消除不相关的语义词典信息在该空间中的影响。
本研究的目的是利用联合多模式BoF(JMBoF)分类框架的低级表示形式,准确,无损且快速地确定大豆种子的质量。本文的其余部分安排如下:首先,介绍了用于捕获图像的实验材料和设备。其次,介绍了与JMBoF相关的大豆干品质检测方法。
实验
实验材料
用于实验的大豆种子购自当地市场。
有10种子叶缺乏,物理损坏,自然破裂,种皮损伤,涂层的干瘪,子叶萎缩性,蠕虫咬伤,种皮,腐朽,子叶发霉和异形缺陷大豆种子的样品(参见下图 ):
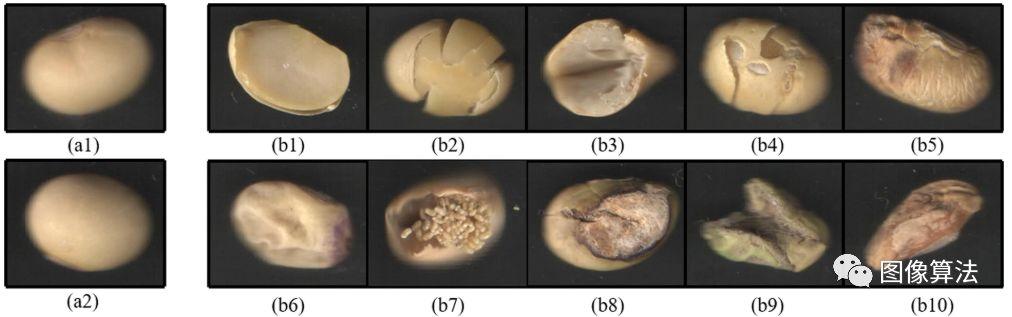
将大豆种子外观质量不同的图像用于分类研究。左侧显示了两个好的大豆种子样本图像(a1,a2)。(b1)子叶缺失,(b2)物理损坏,(b3)自然裂开,(b4)睾丸受损,(b5)壳剥皮,(b6)子叶萎缩,(b7)蠕虫咬伤,(b8)种皮腐烂,(b9)子叶霉菌和(b10)异形大豆种子图像显示在右侧。
物理损坏是指在对种子仁进行物理或机械挤压后将种皮和子叶分裂。子叶缺乏,物理损坏,自然破裂和种皮受损的种子仁如果没有最外层的保护,则长期保存后容易发霉。严重脱壳和子叶萎缩的种子粒被认为营养不良,从而影响人类健康和相关产品质量。食入蠕虫叮咬,已腐烂的子叶,子叶型和异形种子会损害人类和动物的健康。因此,就大豆种子的外观特征而言,对大豆种子进行分级是必要且重要的。在此实验中,我们尝试自动区分三个等级的商品,就外观质量而言,是中等和不健康的大豆种子。
优质大豆种子包含约8%的种皮,90%的子叶和2%的胚轴(包括羽状,下胚轴和胚根),良好的外观特征表明种皮完整且光滑,子叶饱满,这将有利于人类和动物的健康。中等的表明种皮破裂,子叶破裂或子叶略微 riv缩,但这并不损害人类和动物的健康;不健康的现象表明种皮或子叶严重萎缩,子叶萎缩,虫咬,睾丸腐烂,子叶变质或异形,食用后会损害人类和动物的健康,有843个大豆种子用于测试。每种类型都有281个样本。训练集包含70%随机选择的样本,其余30%用于测试目的。
实验装置
视觉光谱成像设备(Perfection V850 Pro,美国爱普生)用于捕获大豆种子的图像。
成像系统的主要部分包括黑色吸收罩,透明平板玻璃板,电机驱动的移位电子平台,电荷耦合成像设备(CCD),通信电缆和计算机。将每个大豆样品以相等的间隔放置在透明玻璃板上。然后将黑色吸收盖水平放置在样品上方作为图像背景。
马达驱动的变速平台带有变速线性光和变速镜。移动的线性光源通过透明的平板玻璃板将线性光束发射到样品表面。样品将光束反射到移动镜,然后来自移动镜的光束被反射到固定镜。
最后,CCD收集从固定镜反射的线性样本光谱。与传统的相机拍摄技术相比,马达驱动的移位电子拍摄平台拍摄照片可以确保照片中任何位置的每个大豆种子都是均匀的。成像设备固定在封闭的黑盒子中,该盒子可以阻挡外部光线的影响。通信电缆用于通过内部成像设备与外部计算机连接。
每张原始捕获的照片包含20个内核,其中每个内核映像都会自动分离并存储到磁盘中。与传统的相机拍摄技术相比,马达驱动的移位电子拍摄平台拍摄照片可以确保照片中任何位置的每个大豆种子都是均匀的。成像设备固定在封闭的黑盒子中,该盒子可以阻挡外部光线的影响。通信电缆用于通过内部成像设备与外部计算机连接。每张原始捕获的照片包含20个内核,其中每个内核映像都会自动分离并存储到磁盘中。与传统的相机拍摄技术相比,马达驱动的移位电子拍摄平台拍摄照片可以确保照片中任何位置的每个大豆种子都是均匀的。成像设备固定在封闭的黑盒子中,该盒子可以阻挡外部光线的影响。通信电缆用于通过内部成像设备与外部计算机连接,每张原始捕获的照片包含20个内核,其中每个内核映像都会自动分离并存储到磁盘中。
方法
色彩空间转换
L * a * b *是国际照明委员会(CIE)25指定的色彩空间,其中L *代表亮度,a *和b *分别代表绿红色和蓝黄色颜色分量。L * a * b *颜色空间不仅包含RGB颜色空间的所有色域,而且表示RGB无法做到的部分颜色空间。RGB颜色空间不能直接传输到L * a * b *颜色空间。完成转换需要两个步骤。首先必须将RGB颜色空间转换为特定的CIE XYZ颜色空间26,

相对于XYZ空间的参考白点(X n,Y n,Z n)的三刺激值,进一步定义了L * a * b *颜色空间:
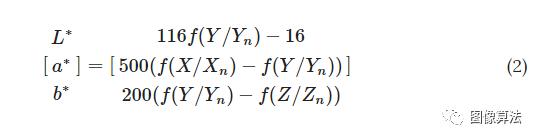
哪里,
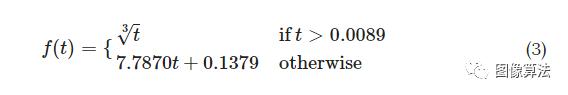
从RGB到L * a * b *的颜色空间转换的示例如下图所示 :
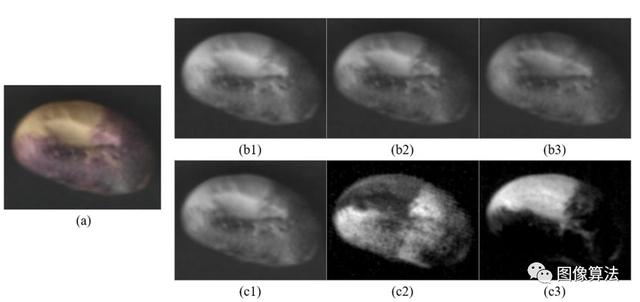
从RGB到CIE L * a * b *的色彩空间转换,可以轻松量化颜色之间的视觉差异。(a)将大豆种子的RGB图像分解为(b1)红色,(b2)绿色和(b3)蓝色分量,并转换为(c1)L *,(c2)a *和(c3)b *颜色通道。
SURF特征空间描述符
SURF是Bay 27引入的一种成功的特征检测算法。目的是定义图像的唯一且健壮的空间描述符。该算法包括以下三个主要步骤:
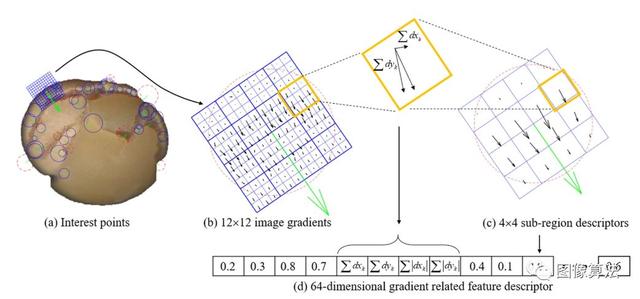
一个示例显示了检测到的(a)兴趣点:由圆心显示的位置,由圆心的绿色半径显示的比例,由半径方向显示的主导方向以及由圆环颜色定义的类别。即,黄色背景为深色(红色虚线圆圈)或深色区域旁边为黄色(蓝色实心圆圈);(b)由Haar小波响应在12×12规则平方的采样点处计算得到的图像梯度;(c)在水平和垂直方向上Haar小波响应的3×3平方区域中,通过计算的矢量和计算出4×4个子区域描述符,这与绿色箭头和(d)来自强度结构4×4子区域的串联64维梯度相关特征描述符。
- (1)检测兴趣点(参见图 (a))。它利用了Hessian Blob检测器行列式的整数近似,该整数近似可以通过三个预定义的积分算符来计算。它的特征描述符基于感兴趣点周围的Haar小波响应之和。特征区域的类别可以由拉普拉斯算子(即,黑森矩阵的迹线)28的符号(由-1和+1表示)确定。
- (2)获取子区域中的梯度信息。感兴趣的区域被分成与选定方向对齐的较小的4×4平方子区域(请参见图 (c)),并且对于每个子区域,均在3×3个规则间隔的采样点处提取Haar小波响应(请参见图3B)。 3(b))。响应乘以高斯增益,以抵抗变形,噪声和平移。
- (3)生成特征空间描述符。来自强度结构每个4×4局部邻域子区域的串联64维梯度相关特征描述符从每个检测到的兴趣点形成特征空间描述符(见图 3(d))。(∑ dXķ,Σ dÿķ,∑ | dXķ| ,∑ | dÿķ| )
特色模型袋
BoF是一种适用于文档分类领域中的图像分类的技术。而不是像文档分类那样使用实际的单词。使用BoF算法使用图像特征等,其最终组合为视觉词典表示图像的视觉词。
为此,它包括以下两个主要步骤:
- (1)提取具有独立特征的“包”。在这项研究中,我们提取了L * a * b *颜色特征和SURF特征的两个特征袋,其中L * a * b *颜色特征由16×16子区域内平均颜色分量的两部分组成提取图像中的图像和相应的空间坐标。
- (2)生成可视词典。执行k均值聚类方法以聚类在步骤1中获得的特征向量。聚类中心定义为可视单词。收集所有视觉单词以生成视觉词典。聚类中心的数量是可视词典的大小。因此,将低级图像特征量化为高级语义信息,以通过视觉单词的分布来表达图像内容。
联合低阶特征表示
在上述的BoF方法中,视觉词典的大小将影响视觉单词构成的特征对图像内容的可解释性:小尺寸词典可能无法完全描述图像特征,太大的词典可能会导致多余的语义表达。
此外,SURF和L * a * b *的新联合模态特征将使字典的维数成倍增加,这将进一步增加特征的冗余语义表示,为了解决这个问题,我们首先通过设置大量的字典(数量= 800)来从图像中提取大尺寸的视觉词典,然后使用LRR方法消除多余的语义信息来有效地表达图像内容。LRR假设高维数据Y具有较低的固有维数。为了减轻维数的问题,原始Y可以分为低秩矩阵X和稀疏误差矩阵E的两个分量:

其中,表示核规范,表示L 1-范数,而λ是正则化参数。上述优化问题本质上是在低维子空间中找到高维数据的最佳投影。除去残留后ë,紧凑的视觉词典组X将被用作原始图像的有效表达22,23。| |⋅| |∗| |⋅| |1个
支持向量机回归
支持向量机的算法30,31是用于在该空间中的输入空间转换成通过非线性变换一个高维的Hilbert空间,然后执行线性分类。SVM方法针对给定的点N假设一组训练数据Λ :
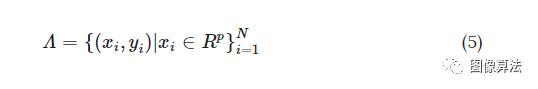
其中预测值y i对应于自变量x i。SVM方法使用核函数φ将自变量x投影到高维特征空间中,以建立线性拟合函数。可以通过解决以下优化问题来建立方程:

其中,ω是与模型的复杂性有关的超平面的法向矢量;λ是可调参数,是松弛变量。
统计分析
所述ķ倍交叉验证技术31是用来评估所建立的模型的稳健性,用于快速并准确地确定收获后干燥的大豆种子质量。将训练大豆样品分为k个相等大小的子样品,其中k等于训练大豆样品的数量。其中一个的ķ大豆样品被选择为未知验证数据和其余ķ - 1个大豆子样本被用于训练目的。每个分割的k -1个大豆子样本数据将被精确训练一次,以预测未用于估算的其余数据。验证结果是对k的平均值 次以评估拟合模型的分类性能。
算法概述
用于确定大豆种子质量的JMBoF分类框架的示意图如下图图所示 。
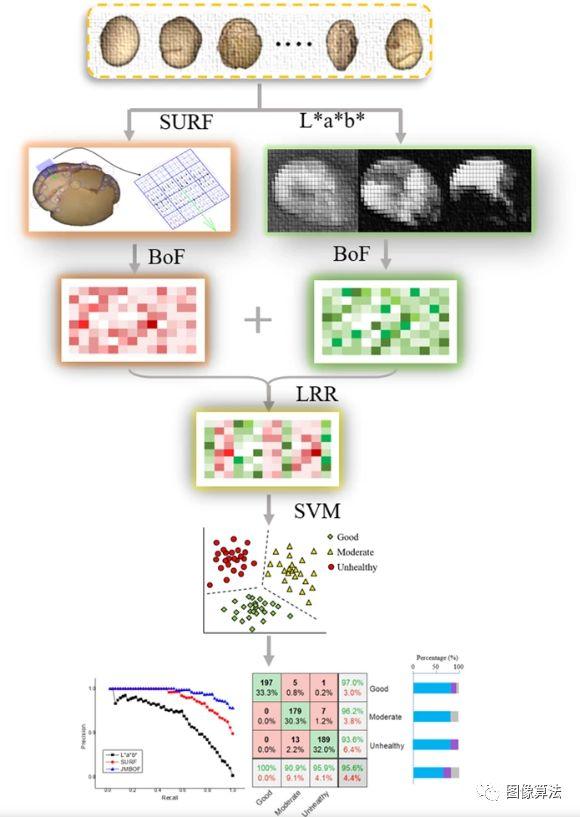
实现我们的大豆类别分类算法的步骤如下
- (1)在图像的16×16子区域内提取L * a * b *颜色分量,并在提取图像的图像中提取相应的空间坐标。
- (2)从大豆图像数据集中提取SURF特征。
- (3)将BoF算法应用于通过使用K均值聚类对特征空间进行量化来减少特征数量,从而分别构建L * a * b *-和SURF相关的视觉词典;
- (4)通过串联L * a * b *-和SURF相关的视觉词典来形成混合语义信息。
- (5)使用LRR方法将乘法维可视词典投影到低级空间,以消除冗余的语义信息。
- (6)执行SVM算法以在高维内核空间中构造分裂超平面,以将联合LRR数据分为三类。
结果与讨论
颜色特征评估
如下图所示 :
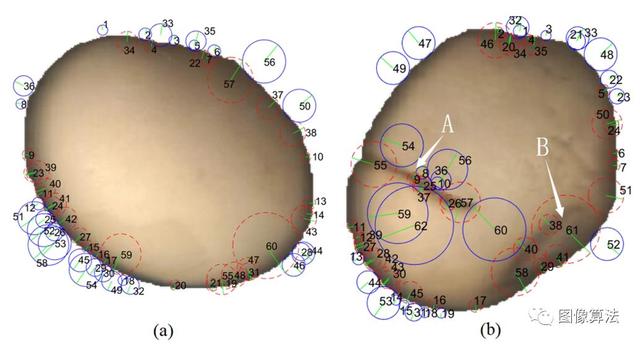
使用SURF算法比较(a)良好和(b)缺陷大豆种子图像的兴趣点分布。检测到的特征点主要分布在大豆图像的边缘以及裂纹(在位置A)和皱缩(在位置B)区域。特征点区域用蓝色实线(Laplacian = -1)或红色虚线((Laplacian = +1))圆标记。绿色半径表示主要方向。每个特征点均已编号。
三种大豆种子仁的外观颜色特性互不相同。子叶暴露大豆的暴露黄色比好大豆 更亮。天然裂解大豆的子叶表面颜色稍微更白和更暗。其他不健康豆的图像与其他颜色特征混合在一起。因此,可以采用颜色特征来区分大豆种子的质量。
通过使用定制的成像设备,以RGB颜色格式存储收集的原始大豆图像数据。RGB颜色模型取决于设备,该模型最初旨在对物理显示器或数据采集设备的输出进行建模。大豆种子的图像分类实际上是基于人类对大豆种子颜色特征的视觉综合感知。L * a * b *颜色空间模仿了眼睛的非线性响应。它可以保留大豆种子图像色彩特征的广泛色域。可以在L * a * b *颜色模型中发现人眼可以感知的所有颜色。
L * a * b *颜色空间中颜色特征的分布比RGB更均匀。RGB颜色空间包含过多的蓝色和绿色之间的过渡颜色,而缺少黄色和绿色和红色之间的其他颜色。RGB颜色空间的各个分量之间的强度值差异很小,因此RGB大豆图像的三个分量的视觉感知极为接近。从RGB到L * a * b *的色彩空间转换后,L * a * b *色彩空间的分量在三个不同的色彩通道之间具有显着差异,因此显示三种极为不同的视觉感知效果图像。
它使算法能够轻松量化颜色之间的视觉差异,因为它与欧氏空间结构更加一致。转换后的可区分特征更适合于基于k均值32的后续颜色字典生成过程。为了更准确地表达大豆种子仁图像的颜色特征,我们将RGB颜色描述符转换为CIEL * a * b *。
SURF功能评估
SURF算法可以通过测量图像的主导方向来估计放置角度。大豆籽粒可任意放置在成像面板中,但是,提取的有效特征不受放置角度的影响,因为SURF特征对于图像旋转是不变的。通过SURF算法检测出总共60个特征点。检测到的特征点主要分布在大豆图像的边缘。特征点的类别对应于Laplacian 27的符号。在外部边缘检测到的拉普拉斯算子为-1,并用蓝色实心圆标记;内侧边缘处的拉普拉斯算子为+1,并用红色虚线圆圈标记;每个特征点均已编号。绿色半径表示主要方向。主导方向与特征区域有关。围绕内边缘区域和外边缘区域的主导方向垂直于大豆轮廓的切线方向。优质大豆仁的表面颜色相对光滑且均匀,因此梯度变化相对较小,而边缘区域周围的颜色变化明显,因此边缘处的梯度变化相对于内部平滑区域更大。
SURF算法主要基于梯度算法,通过SURF算法检测出总共62个特征点。每个特征点均已编号。所检测到的特征点主要分布在边缘,开裂和皱缩大豆仁的面积。在边缘的外部检测到的拉普拉斯算子为-1,用蓝色实心圆标记;内侧边缘上的拉普拉斯算子为+1,并用红色虚线圆圈标记;检测中心的裂纹区域的拉普拉斯算子为1,并用红色虚线圆圈标记;检测中心在收缩区域的拉普拉斯值+1,并用红色虚线圆圈标记。在破裂和收缩的区域中,主要方向分别近似垂直于破裂和收缩的方向。相对于黄色背景区域,在裂纹和皱缩区域的位置处形成了较暗的图像区域,因此在这些位置处边缘处的梯度变化相对较大。SURF方法主要基于梯度算法,因此这些特征位置显而易见。在检测到的破裂和皱缩区域的梯度相关信息可以用作估计大豆品质的区别特征。
联合多模式特征评估
混淆矩阵图用于总结和可视化提出的JMBoF + SVM算法的性能结果。如图所示 ,行表示混淆矩阵,表示预测结果,列表示实际结果。正确的分类结果显示在绿色对角线单元上。对于训练集,正确地分别将197、179和189个对象标识为好,中和不健康的大豆。这些分别对应于所有591个训练大豆实例的33.3%,30.3%和32.0%。同样,对于测试集,分别将84、53和70个对象正确分类为好,中和不健康的实例。这些分别对应于所有252张测试大豆图像中的33.3%,21.0%和27.8%。红色非对角线元素显示模型做出错误预测的位置。
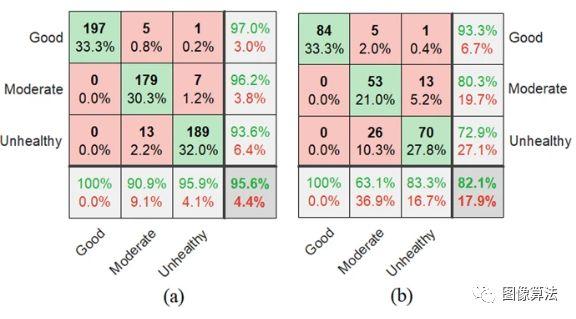
通过使用混淆矩阵图形在训练(a)和测试(b)数据集上使用JMBoF + SVM模型在外观质量上区分3种优质,中度和不良大豆种子的分类结果摘要。
对于训练集,将5个中度物种和1个不健康物种错误地分类为好物种,分别为0.8%和0。在所有591个良好实例中,分别占2%。7个不健康的物种被误认为是中度物种,占所有591个良好实例的1.2%。13个中度物种被错误地归类为不健康物种,占所有591个良好实例的2.2%。同样,对于测试集,将5个中等和1个不健康的物种错误地归类为好物种,分别相当于所有252个大豆实例的2.0%和0.4%。13个不健康的物种被错误地归类为中度样本,相当于所有252个大豆实例中的5.2%。26种中度种被错误地归类为不健康种,占所有252种大豆实例的10.3%。在203个好的预测中,有97.0%是正确的,而3.0%是错误的。在186个中等预测中,有96个。2%是正确的,而3.8%是错误的。在202个不健康的预测中,正确的预测为93.6%,错误的预测为6.4%。在197个好案例中,所有案例都被正确地预测为好物种。在197个中度病例中,有90.9%被正确分类为中度物种,而9.1%被分类为良好和不健康物种。在197个不健康的病例中,有95.9%被正确归类为不健康,而4.1%被归类为良好和中度物种。同样,对于测试集,在90个好的预测中,有93.3%是正确的,而6.7%是错误的。在66个中等预测中,有80.3%是正确的,而19.7%是错误的。在96个不健康的预测中,正确的预测为72.9%,错误的预测为27.1%。在84个好的案例中,所有案例都被正确地预测为好的物种。在84例中度病例中,有63.1%被正确分类为中度和36例。9%被归类为良好和不健康。在84个不健康的病例中,正确分类为不健康的占83.3%,良好和中度的占16.7%。总体而言,大豆训练和测试集分别有95.9%和82.1%的预测是正确的,而4.4%和17.9%的预测是错误的。
比较算法性能
精确召回(PR)曲线用于可视化评估分类器性能。精度表示真实肯定率,而召回率则表示相对于所有肯定预测34而言真实肯定的概率。
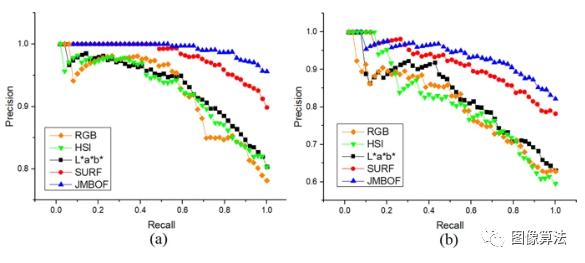
使用RGB + BoF + SVM,HSI + BoF + SVM,L * a * b * + BoF + SVM,SURF的方法在外观质量上区分三种优质,中度和不良大豆种子的精确召回曲线在训练(a)和测试(b)数据集上分别使用+ BoF + SVM和JMBoF + SVM 。
上图显示了在不同阈值的精度和召回率之间的权衡,即召回率随着精度下降而增加的趋势。
显然,在不同的情况下,JMBoF + SVM模型基本上比RGB + BoF + SVM,HSI + BoF + SVM,L * a * b * + BoF + SVM和SURF + BoF + SVM模型拥有更高的准确率百分比。召回门槛。平均平均精度(mAP)分数是精度调用曲线下的面积35可以用作算法性能的综合评估。JMBoF + SVM模型分别在训练和测试大豆图像数据集上产生的最高mAP分数分别为0.973和0.918,并且优于RGB + BoF + SVM的0.904和0.787,HSI + BoF + SVM的0.905和0.791,L * a * b * + BoF + SVM为0.914和0.811,SURF + BoF + SVM为0.962和0.893。
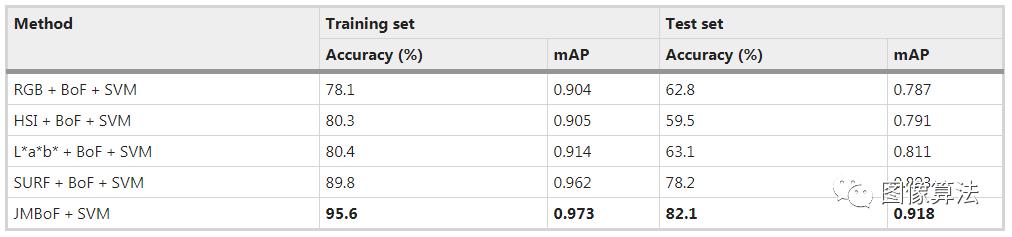
表中使用RGB + BoF + SVM,HSI + BoF + SVM,L * a * b * +对3种优质,中度和不良健康大豆种子的外观质量进行分级的准确性和平均平均精度(mAP)得分BoF + SVM,SURF + BoF + SVM和JMBoF + SVM模型分别在训练和测试数据集上。
RGB + BoF + SVM模型的精度为78.1%和62.8%,HSI + BoF + SVM模型的精度为80.3%和59.6%,L * a * b * + BoF + SVM模型的结果在训练和测试大豆图像数据集上的准确度分别为80.4%和63.1%。
基于L * a * b *的单峰算法优于其他两个算法,可能是因为可以在L * a * b *颜色空间中突出显示大豆样品的几种可辨别的颜色特征,基于颜色的单峰方法主要根据外观的总体特征区分大豆类别,有缺陷的大豆的受损部分有时会占据大豆表面的一小部分。
相应的提取特征在整个特征向量中也占很小的比例,这将导致在随后的分类过程中忽略了所识别的信息,因此生成的识别率较低。与基RGB,HSI和L * a * b *的全局颜色模型不同,SURF + BoF + SVM模型不会应用来自大豆图像的全局颜色信息。它试图检测潜在的特征点,并从感兴趣区域构造基于梯度的描述符。这些特征点主要分布在大豆核的边缘和缺陷部位。由于获得了有效的区分特征,SURF + BoF + SVM模型提高了分类精度,比训练和测试大豆图像数据集上的L * a * b * + BoF + SVM模型分别高9.4%和15.1%。但是,此方法的一个潜在缺点是有缺陷的补丁和完整补丁与全局图像结构之间的关系会被忽略。这可以通过从整个图像中采样全局L * a * b *特征来部分补偿。JMBoF + SVM模型利用了基于局部兴趣区域梯度的特征和全局颜色特征信息来进一步提高分类准确性。L * a * b * + BoF + SVM模型在训练和测试大豆图像数据集上的分类精度最高,达到95.6%和82.1%,分别为5.7%和3。
结论
本文首先对外观色特性进行了评估,以对大豆种子仁进行分类。RGB大豆图像的三个组成部分的视觉感知极为接近。从RGB到L * a * b *的色彩空间转换后,L * a * b *色彩空间的分量显示出三个不同色彩通道之间的明显视觉差异。视觉感知效果的图像类型极为不同,因此可以轻松地形成鲜明的特征。SURF功能不变于图像旋转。SURF算法可以通过不测量图像的主导方向来估计放置角度。尽管将大豆粒任意放置在成像面板中,但提取的有效特征不受放置角度的影响。主导方向与特征区域有关。围绕内边缘区域和外边缘区域的主导方向垂直于大豆轮廓的切线方向。在破裂和收缩的区域中,主要方向分别近似垂直于破裂和收缩的方向。边缘处的梯度变化相对于内部平滑区域较大,并且相对于黄色背景区域,在裂纹和皱缩区域的位置处形成的图像区域较暗,因此在这些位置处,边缘处的梯度变化相对较大。SURF方法主要基于梯度算法,因此这些特征位置显而易见。主方向分别近似垂直于裂纹和收缩的方向。边缘处的梯度变化相对于内部平滑区域较大,并且相对于黄色背景区域,在裂纹和皱缩区域的位置处形成的图像区域较暗,因此在这些位置处,边缘处的梯度变化相对较大。SURF方法主要基于梯度算法,因此这些特征位置显而易见。主方向分别近似垂直于裂纹和收缩的方向。边缘处的梯度变化相对于内部平滑区域较大,并且相对于黄色背景区域,在裂纹和皱缩区域的位置处形成的图像区域较暗,因此在这些位置处,边缘处的梯度变化相对较大。SURF方法主要基于梯度算法,因此这些特征位置显而易见。
将RGB + BoF + SVM,HSI + BoF + SVM,L * a * b * + BoF + SVM,SURF + BoF + SVM和JMBoF + SVM的五种不同算法应用于大豆品质分类。JMBoF + SVM的基于多模式的方法优于其他四种基于单模式的算法,这可能是因为JMBoF + SVM模型综合利用了全局颜色特征和基于局部兴趣区域梯度的特征(SURF)信息。在训练和测试大豆图像数据集上,JMBoF + SVM模型分别具有最高95.6%和82.1%的准确性。所提出的算法有可能被应用到智能自动大豆分级机中,以准确,无损,快速地筛选出不良籽粒。
基于机器视觉技术快速准确地确定收获后干大豆种子的品质http://t.zijieimg.com/CC648J/
转载请注明:徐自远的乱七八糟小站 » 基于机器视觉技术快速准确地确定收获后干大豆种子的品质



