Colab提供了免费TPU,机器之心帮你试了试
机器之心原创,作者:思源。
最近机器之心发现谷歌的 Colab 已经支持使用免费的 TPU,这是继免费 GPU 之后又一重要的计算资源。我们发现目前很少有博客或 Reddit 论坛讨论这一点,而且谷歌也没有通过博客或其它方式做宣传。因此我们尝试使用该 TPU 训练简单的卷积神经网络,并对比它的运行速度。
我们在网上只发现比较少的信息与资源,最开始介绍 Colab 免费 TPU 的内容还是谷歌开发者 Sam Wittevee 最近的演讲 PPT。因此本文的测试和探索都是基于官方文档和实例所实现的,还有很多 TPU 特性没有考虑到,感兴趣的读者可查阅文末的参考资料,了解更多 Colab 免费 TPU 的特性。
本文所有的测试代码与结果都可以访问:https://colab.research.google.com/drive/1DpUCBm58fruGNRtQL_DiSVbT90spdZgm
试验 Colab 免费 TPU
首先我们需要确保 Colab 笔记本中运行时类型选择的是 TPU,同时分配了 TPU 资源。因此依次选择菜单栏中的「runtime」和「change runtime type」就能弹出以下对话框:

为了确保 Colab 给我们分配了 TPU 计算资源,我们可以运行以下测试代码。如果输出 ERROR 项,则表示目前的运行时并没有调整到 TPU,如果输出 TPU 地址及 TPU 设备列表,则表示 Colab 已经为我们分配了 TPU 计算资源。
如果查看以下测试代码的正常输出,Colab 会为「TPU 运行时」分配 CPU 和 TPU,其中分配的 TPU 工作站有八个核心,因此在后面配置的 TPU 策略会选择 8 条并行 shards。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
import os import pprint import tensorflow as tf if 'COLAB_TPU_ADDR' not in os.environ: print('ERROR: Not connected to a TPU runtime') else: tpu_address = 'grpc://' + os.environ['COLAB_TPU_ADDR'] print ('TPU address is', tpu_address) with tf.Session(tpu_address) as session: devices = session.list_devices() print('TPU devices:') pprint.pprint(devices) |
目前,Colab 一共支持三种运行时,即 CPU、GPU(K80)和 TPU(据说是 TPU v2)。但我们不太了解 Colab 中的 GPU 和 TPU 在深度模型中的表现如何,当然后面会用具体的任务去测试,不过现在我们可以先用相同的运算试试它们的效果。因此我们首先尝试用简单的卷积运算测试它们的迭代时间。
在测试不同的硬件时,需要切换到不同的运行时。如下先定义 128 张随机生成的 256×256 图像,然后定义 256 个 5×5 的卷积核后就能执行卷积运算,其中魔术函数 %timeit 会自动多次执行,以产生一个更为精确的平均执行时间。
|
1 2 3 4 5 6 7 8 9 10 |
import tensorflow as tf import numpy as np import timeit tf.reset_default_graph() img = np.random.randn(128, 256, 256, 3).astype(np.float32) w = np.random.randn(5, 5, 3, 256).astype(np.float32) conv = tf.nn.conv2d(img, w, [1,2,2,1], padding='SAME') with tf.Session() as sess: # with tf.device("/gpu:0") as dev: %timeit sess.run(conv) |
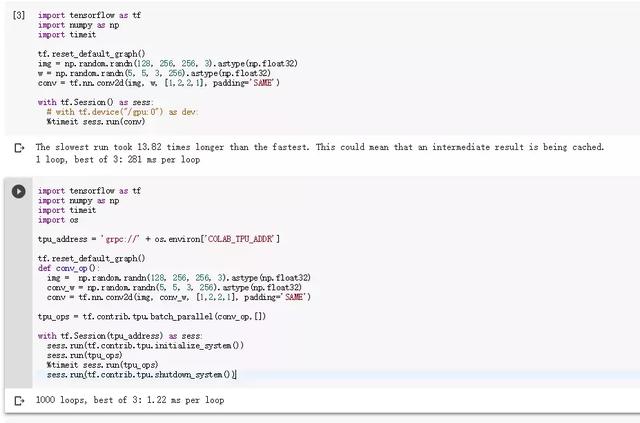
然而,是我们想当然了,使用 TPU 执行运算似乎需要特定的函数与运算,它不像 CPU 和 GPU 那样可以共用相同的代码。分别选择 CPU、GPU 和 TPU 作为运行时状态,运行上面的代码并迭代一次所需要的时间分别为:2.44 s、280 ms、2.47 s。从这里看来,仅修改运行时状态,并不会真正调用 TPU 资源,真正实现运算的还是 CPU。随后我们发现 TF 存在一个神奇的类 tf.contrib.tpu,似乎真正调用 TPU 资源必须使用它改写模型。
因此,根据文档与调用示例,我们将上面的卷积测试代码改为了以下形式,并成功地调用了 TPU。此外,因为每次都需要重新连接不同的运行时,所以这里的代码都保留了库的导入。虽然代码不太一样,但直觉上它的计算量应该和上面的代码相同,因此大致上能判断 Colab 提供的 GPU、TPU 速度对比。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
import tensorflow as tf import numpy as np import timeit import os tpu_address = 'grpc://' + os.environ['COLAB_TPU_ADDR'] tf.reset_default_graph() def conv_op(): img = np.random.randn(128, 256, 256, 3).astype(np.float32) conv_w = np.random.randn(5, 5, 3, 256).astype(np.float32) conv = tf.nn.conv2d(img, conv_w, [1,2,2,1], padding='SAME') tpu_ops = tf.contrib.tpu.batch_parallel(conv_op, [], num_shards=8) with tf.Session(tpu_address) as sess: sess.run(tf.contrib.tpu.initialize_system()) sess.run(tpu_ops) %timeit sess.run(tpu_ops) sess.run(tf.contrib.tpu.shutdown_system()) |
运行后出现了非常意外的结果,这样的卷积运算每一次迭代只需要 1.22 ms。如下图所示,很可能存在变量缓存等其它因素造成了一定程度的缓慢,但 TPU 的速度无可置疑地快。因此如果在 Colab 上测试模型,我们就更希望使用免费的 TPU,不过使用 TPU 需要改模型代码,这又比较麻烦。
尽管简单的卷积运算 TPU 要比 K80 快很多,但这只能给我们一个大致的猜想,因此我们需要测试完整的模型。注意在 tf.contrib.tpu 类中,它还提供了两种使用 TPU 的简单方法,即直接使用 Keras 接口和使用 TPUEstimator 构建模型。
在 tf.contrib.tpu 的文档中,我们发现 tf.contrib.tpu.keras_to_tpu_model 方法可以直接将 Keras 模型与对应的权重复制到 TPU,并返回 TPU 模型。该方法在输入 Keras 模型和在多个 TPU 核心上的训练策略后,能输出一个 Keras TPU 模型的实例,且可分配到 TPU 进行运算。
除此之外,另外一种调用 TPU 计算资源的方法是 tf.contrib.tpu.TPUEstimator,对于修正我们原来的 TensorFlow 模型以适用 TPU,它可能是一种更方便的方式。根据文档所示,TPUEstimator 类继承自 Estimator 类,因此它不仅支持在 TPU 上运算,同时还支持 CPU 和 GPU 的运算。TPUEstimator 隐藏了非常多在 TPU 上训练的细节,例如为多个 TPU 核心复制多个输入和模型等。
TPU 调用文档地址:https://www.tensorflow.org/api_docs/python/tf/contrib/tpu
对比 TPU 与 GPU 的计算速度
为了简单起见,这里仅使用 Fashion-MNIST 数据集与简单的 5 层卷积神经网络测试不同的芯片性能。这个模型是基于 Keras 构建的,因为除了模型转换与编译,Keras 模型在 TPU 和 GPU 的训练代码都是一样的,且用 Keras 模型做展示也非常简洁。
几天前谷歌 Colab 团队发了一版使用 Keras 调用 TPU 的教程,因此我们就借助它测试 TPU 的训练速度。对于 GPU 的测试,我们可以修改该模型的编译与拟合部分,并调用 GPU 进行训练。所以整个训练的数据获取、模型结构、超参数都是一样的,不一样的只是硬件。
教程地址:https://colab.research.google.com/github/tensorflow/tpu/blob/master/tools/colab/fashion_mnist.ipynb
以下是整个测试的公共部分,包含了训练数据的获取和模型架构。Keras 的模型代码非常好理解,如下第一个卷积层首先采用了批归一化,然后用 64 个 5×5 的卷积核实现卷积运算,注意这里采用的激活函数都是指数线性单元(ELU)。随后对卷积结果做 2×2 的最大池化,并加上一个随机丢弃率为 0.25 的 Dropout 层,最后得出的结果就是第一个卷积层的输出。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
import tensorflow as tf import numpy as np import timeit (x_train, y_train), (x_test, y_test) = tf.keras.datasets.fashion_mnist.load_data() # add empty color dimension x_train = np.expand_dims(x_train, -1) x_test = np.expand_dims(x_test, -1) model = tf.keras.models.Sequential() # 以下为第一个卷积层 model.add(tf.keras.layers.BatchNormalization(input_shape=x_train.shape[1:])) model.add(tf.keras.layers.Conv2D(64, (5, 5), padding='same', activation='elu')) model.add(tf.keras.layers.MaxPooling2D(pool_size=(2, 2), strides=(2,2))) model.add(tf.keras.layers.Dropout(0.25)) model.add(tf.keras.layers.BatchNormalization(input_shape=x_train.shape[1:])) model.add(tf.keras.layers.Conv2D(128, (5, 5), padding='same', activation='elu')) model.add(tf.keras.layers.MaxPooling2D(pool_size=(2, 2))) model.add(tf.keras.layers.Dropout(0.25)) model.add(tf.keras.layers.BatchNormalization(input_shape=x_train.shape[1:])) model.add(tf.keras.layers.Conv2D(256, (5, 5), padding='same', activation='elu')) model.add(tf.keras.layers.MaxPooling2D(pool_size=(2, 2), strides=(2,2))) model.add(tf.keras.layers.Dropout(0.25)) model.add(tf.keras.layers.Flatten()) model.add(tf.keras.layers.Dense(256)) model.add(tf.keras.layers.Activation('elu')) model.add(tf.keras.layers.Dropout(0.5)) model.add(tf.keras.layers.Dense(10)) model.add(tf.keras.layers.Activation('softmax')) model.summary() |
在定义模型后,TPU 需要转化模型与编译模型。如下所示,keras_to_tpu_model 方法需要输入正常 Keras 模型及其在 TPU 上的分布式策略,这可以视为「TPU 版」的模型。完成模型的转换后,只需要像一般 Keras 模型那样执行编译并拟合数据就可以了。
注意两个模型的超参数,如学习率、批量大小和 Epoch 数量等都设置为相同的数值,且损失函数和最优化器等也采用相同的方法。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
import os tpu_model = tf.contrib.tpu.keras_to_tpu_model( model, strategy=tf.contrib.tpu.TPUDistributionStrategy( tf.contrib.cluster_resolver.TPUClusterResolver(tpu='grpc://' + os.environ['COLAB_TPU_ADDR']) ) ) tpu_model.compile( optimizer=tf.train.AdamOptimizer(learning_rate=1e-3, ), loss=tf.keras.losses.sparse_categorical_crossentropy, metrics=['sparse_categorical_accuracy'] ) def train_gen(batch_size): while True: offset = np.random.randint(0, x_train.shape[0] - batch_size) yield x_train[offset:offset+batch_size], y_train[offset:offset + batch_size] %time tpu_model.fit_generator(train_gen(1024), epochs=5, steps_per_epoch=100, validation_data=(x_test, y_test)) |
最后在使用 GPU 训练模型时,我们会删除模型转换步骤,并保留相同的编译和拟合部分。训练的结果如下所示,Colab 提供的 TPU 要比 GPU 快 3 倍左右,一般 TPU 训练 5 个 Epoch 只需要 40 多秒,而 GPU 需要 2 分多钟。
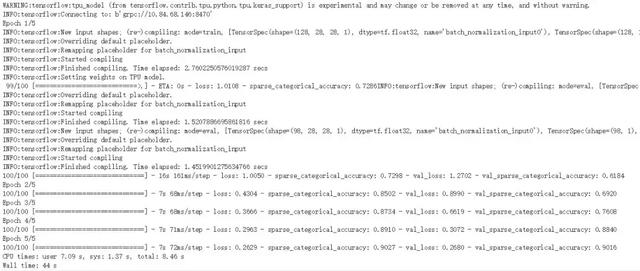
Colab 使用免费 TPU 训练的信息摘要。

Colab 使用免费 GPU 训练的信息摘要。
最后,Colab 确实提供了非常强劲的免费 TPU,而且使用 Keras 或 TPUEstimator 也很容易重新搭建或转换已有的 TensorFlow 模型。机器之心只是简单地试用了 Colab 免费 TPU,还有很多特性有待读者的测试,例如支持 TPU 的 PyTorch 1.0 或循环神经网络在 TPU 上的性能等。
Colab提供了免费TPU,机器之心帮你试了试http://t.jinritoutiao.js.cn/dwP8nk/
转载请注明:徐自远的乱七八糟小站 » Colab提供了免费TPU,机器之心帮你试了试



