用 OpenCV 检测图像中各物体大小
雷锋网 AI 研习社按:本文为雷锋网字幕组编译的技术博客,原标题为 Measuring size of objects in an image with OpenCV,作者为 Adrian Rosebrock 。
翻译 | 尘央 整理 | 孔令双
原文链接:
https://www.pyimagesearch.com/2016/03/28/measuring-size-of-objects-in-an-image-with-opencv/
 在图像中测量物体的大小与计算从相机到物体之间的距离是相似的,在这两种情况下,我们需要定义一个比值,它测量每个给定指标的像素个数。
在图像中测量物体的大小与计算从相机到物体之间的距离是相似的,在这两种情况下,我们需要定义一个比值,它测量每个给定指标的像素个数。
我将其称为「像素/度量」比率,在下一节中我将更正式地定义它。
「像素/度量」比率
为了确定图像中物体的大小,我们首先需要使用一个 参考物体进行「校准」(不要与内部/外部校准混淆)。我们的参考物体应该有两个重要的属性:
- 属性 1:我们应该在一个可测量的单位(如毫米、英寸等)内,知道这个物体的尺寸(根据宽度或高度)。
- 属性 2:我们应该能够在图像中轻松地找到这个参考物体,要么基于物体的位置(如参考物体总是被放置在图像的左上角)或通过表象(像一个独特的颜色或形状,独特且不同于其他物体的物体)。在任何一种情况下,我们的参考都应该以某种方式具有惟一的可识别性。
在本例中,我们将使用一个两角五分的美元硬币作为参考物体,并在所有示例中确保它始终是图像中最左的物体:
 图1:我们将使用一个两角五分的美元硬币作为参照物,并确保它始终作为图像中最左边的物体放置,这样我们就可以很容易地根据轮廓的位置对其进行排序。
图1:我们将使用一个两角五分的美元硬币作为参照物,并确保它始终作为图像中最左边的物体放置,这样我们就可以很容易地根据轮廓的位置对其进行排序。
通过保证1 / 4是最左的物体,我们可以从左到右对物体轮廓进行排序,获取1 / 4(这将始终是排序列表中的第一个轮廓),并使用它来定义我们的 pixels_per_metric ,我们将其定义为:
pixels_per_metric = object_width / know_width
一个两角五分的美元硬币是 0.955 英寸。现在假设我们的 object_width (以像素为单位)被计算为 150 像素宽(基于它的相关边框)。
因此,pixels_per_metric 为:
pixels_per_metric = 150px / 0.955in = 157px
因此,在我们的图像中,每 0.955 英寸大约有 157 个像素。利用这个比率,我们可以计算图像中物体的大小。
基于计算机视觉的物体尺寸检测
既然我们知道「像素/度量」比率 ,就可以实现用于测量图像中物体大小的 Python 驱动程序脚本。
新建一个文件,将其命名为 object_size.py ,插入以下代码:
# import the necessary packages
from scipy.spatial import distance as dist
from imutils import perspective
from imutils import contours
import numpy as np
import argparse
import imutils
import cv2
def midpoint(ptA, ptB):
return ((ptA[0] + ptB[0]) * 0.5, (ptA[1] + ptB[1]) * 0.5)
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser
ap.add_argument(“-i”, “–image”, required=True,
help=”path to the input image”)
ap.add_argument(“-w”, “–width”, type=float, required=True,
help=”width of the left-most object in the image (in inches)”)
args = vars(ap.parse_args)
第 2 行到第 8 行导入我们需要的 Python 包。在该例中,我们将充分利用 imutils package ,所以如果你没有安装这个包,确保在继续下一步之前安装这个包。
$ pip install imutils
否则,如果你确实安装了 imutils ,请确保你有最新的版本,本文的版本为 0.3.6:
pip install –upgrade imutils
第 10 行和第 11 行定义一个称为中点的辅助方法,顾名思义,用于计算(x, y)-坐标的两组之间的中点。
第 14 行到第 19 解析我们的命令行参数。我们需要两个参数:一个是图像,该图像为包含我们想测量物体的输入图像的路径,第二个是参照物的宽度(以英寸为单位),假定参照物在我们图像中的最左端。
现在,我们能加载我们的图像并对其进行预处理:
# load the image, convert it to grayscale, and blur it slightly
image = cv2.imread(args[“image”])
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
gray = cv2.GaussianBlur(gray, (7, 7), 0)
# perform edge detection, then perform a dilation + erosion to
# close gaps in between object edges
edged = cv2.Canny(gray, 50, 100)
edged = cv2.dilate(edged, None, iterations=1)
edged = cv2.erode(edged, None, iterations=1)
# find contours in the edge map
cnts = cv2.findContours(edged.copy, cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
cnts = cnts[0] if imutils.is_cv2 else cnts[1]
# sort the contours from left-to-right and initialize the
# ‘pixels per metric’ calibration variable
(cnts, _) = contours.sort_contours(cnts)
pixelsPerMetric = None
第 2 行到第 4 行:从磁盘中加载我们的图像,将该图像灰度化,并利用高斯过滤器将其平滑化。第 8 行到第 10 行:对其进行边缘检测,并通过膨胀和腐蚀使边缘过渡得更加平滑。
第 13 行到第 15 行:在边缘检测后的图中寻找与物体一致的边缘(例如轮廓)。
第 19 行:将这些边缘从左到右排序(允许我们提取参照物)。第 20 行:初始化 pixelsPerMetric 值。
下一步就是检测每个轮廓:
# loop over the contours individually
for c in cnts:
# if the contour is not sufficiently large, ignore it
if cv2.contourArea(c)
continue
# compute the rotated bounding box of the contour
orig = image.copy
box = cv2.minAreaRect(c)
box = cv2.cv.BoxPoints(box) if imutils.is_cv2 else cv2.boxPoints(box)
box = np.array(box, dtype=”int”)
# order the points in the contour such that they appear
# in top-left, top-right, bottom-right, and bottom-left
# order, then draw the outline of the rotated bounding
# box
box = perspective.order_points(box)
cv2.drawContours(orig, [box.astype(“int”)], -1, (0, 255, 0), 2)
# loop over the original points and draw them
for (x, y) in box:
cv2.circle(orig, (int(x), int(y)), 5, (0, 0, 255), -1)
在第 2 行,我们开始对每个轮廓进行循环。如果轮廓不够大,我们丢弃该区域,假设它是边缘检测过程中遗留下来的噪声(第 4 行和第 5 行)。
倘若轮廓区域足够大,我们在第 9-11 行计算图像的旋转边界框,特别注意使用 OpenCV 2.4 的 cv2.cv.BoxPoints 函数和 OpenCV 3 的 cv2.boxPoints 方法。
在第 17 行,我们在左上方、右上角、右下角和左下方的顺序排列我们旋转的边界框坐标,如上周的博客文章所说的那样。
最后,第 18-21 行以绿色绘制物体的轮廓,然后将边界框矩形的顶点绘制成红色的小圆圈。
既然我们已经将边界矩形框排好序了,就能计算出一系列的中点:
# unpack the ordered bounding box, then compute the midpoint
# between the top-left and top-right coordinates, followed by
# the midpoint between bottom-left and bottom-right coordinates
(tl, tr, br, bl) = box
(tltrX, tltrY) = midpoint(tl, tr)
(blbrX, blbrY) = midpoint(bl, br)
# compute the midpoint between the top-left and top-right points,
# followed by the midpoint between the top-righ and bottom-right
(tlblX, tlblY) = midpoint(tl, bl)
(trbrX, trbrY) = midpoint(tr, br)
# draw the midpoints on the image
cv2.circle(orig, (int(tltrX), int(tltrY)), 5, (255, 0, 0), -1)
cv2.circle(orig, (int(blbrX), int(blbrY)), 5, (255, 0, 0), -1)
cv2.circle(orig, (int(tlblX), int(tlblY)), 5, (255, 0, 0), -1)
cv2.circle(orig, (int(trbrX), int(trbrY)), 5, (255, 0, 0), -1)
# draw lines between the midpoints
cv2.line(orig, (int(tltrX), int(tltrY)), (int(blbrX), int(blbrY)),
(255, 0, 255), 2)
cv2.line(orig, (int(tlblX), int(tlblY)), (int(trbrX), int(trbrY)),
(255, 0, 255), 2)
第 4-6 行打开我们的有序边界框,计算左上角和右上角之间的中点,然后计算右下角之间的中点。
我们还将分别计算左上+左下+右上+右下+右下之间的中点(第 10 行和第 11 行)。
第 14-17 行在图像上绘制蓝色中间点,然后将中间点与紫色线连接。
接下来,我们需要通过调查参照物来初始化 pixelsPerMetric 变量:
# compute the Euclidean distance between the midpoints
dA = dist.euclidean((tltrX, tltrY), (blbrX, blbrY))
dB = dist.euclidean((tlblX, tlblY), (trbrX, trbrY))
# if the pixels per metric has not been initialized, then
# compute it as the ratio of pixels to supplied metric
# (in this case, inches)
if pixelsPerMetric is None:
pixelsPerMetric = dB / args[“width”]
首先,我们计算出我们的中点集合之间的欧氏距离(第 2 和 3 行)。dA 变量将包含高度距离(以像素为单位),而 dB 将保留宽度距离。
然后在第 8 行进行检查,看看我们的 pixelsPerMetric 变量是否被初始化了,如果没有初始化,我们将 dB 除以我们提供的宽度,从而得到(近似的)像素/英寸。
既然我们的 pixelsPerMetric 变量已经被定义,我们就可以测量图像中物体的大小:
# compute the size of the object
dimA = dA / pixelsPerMetric
dimB = dB / pixelsPerMetric
# draw the object sizes on the image
cv2.putText(orig, “{:.1f}in”.format(dimA),
(int(tltrX – 15), int(tltrY – 10)), cv2.FONT_HERSHEY_SIMPLEX,
0.65, (255, 255, 255), 2)
cv2.putText(orig, “{:.1f}in”.format(dimB),
(int(trbrX + 10), int(trbrY)), cv2.FONT_HERSHEY_SIMPLEX,
0.65, (255, 255, 255), 2)
# show the output image
cv2.imshow(“Image”, orig)
cv2.waitKey(0)
第 2 行和 3 行通过将各自的欧几里得距离除以像素值来计算物体的尺寸(以英寸为单位)。
第 6-11 行绘制图像上物体的尺寸,第 14 行和第 15 行显示输出结果。
检测物体大小的结果
为了测试我们 object_size.py 脚本,只需用以下命令:
$ python object_size.py –image images/example_01.png –width 0.955
你的输出结果应该如下所示:
 图 2:使用 OpenCV 、Python 、计算机视觉和图像处理技术测量图像中物体的大小。
图 2:使用 OpenCV 、Python 、计算机视觉和图像处理技术测量图像中物体的大小。
上图所示,我们已经成功地计算出图像中每个物体的大小——我们的名片被正确地显示为 3.5 英寸 x 2英寸。同样,我们的镍被准确地描述为 0.8 英寸 x 0.8 英寸。
尽管如此,并不是所有的结果都很精确。
Gameboy 墨盒的尺寸略有不同(尽管大小相同)。两个季度的高度也下降了 0.1 英寸。
所以,这是为什么呢?怎么物体的检测不是百分百的准确呢?原因是双重的:
- 首先,我赶紧用我的 iPhone 拍了这张照片。这个角度当然不是完全 90 度地「向下看」物体(就像鸟瞰一样)。如果不是完全 90 度视图(或者尽可能接近它),物体的尺寸可能会显得扭曲。
- 其次,我没有使用相机的内部和外部参数来校准我的 iPhone 。如果不确定这些参数,照片很容易出现径向和切向镜头畸变。为了找到这些参数而执行额外的校准步骤,可以「不扭曲」我们的图像,并导致更好的对象大小近似(但我将把失真校正的讨论作为未来博客文章的主题)。
与此同时,在拍摄物体时,尽量接近 90 度的视角 —— 这将有助于提高你对物体大小的估计的准确性。
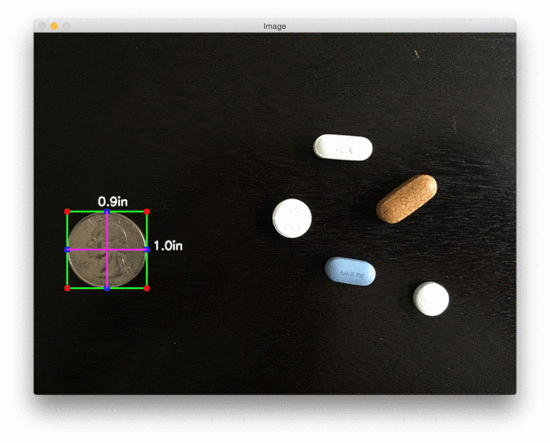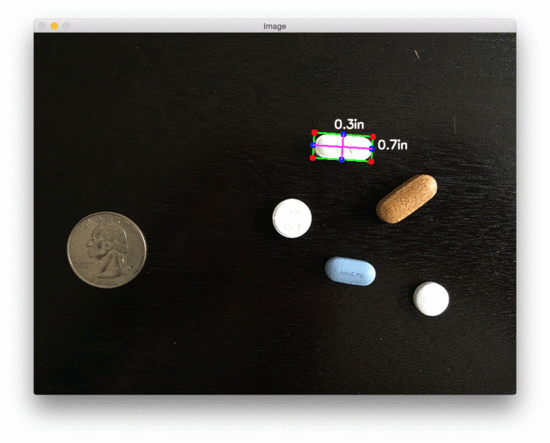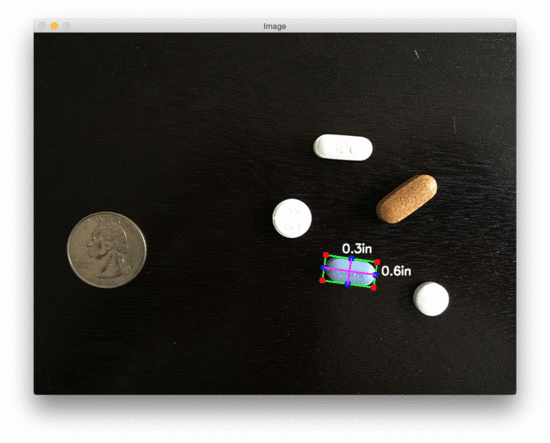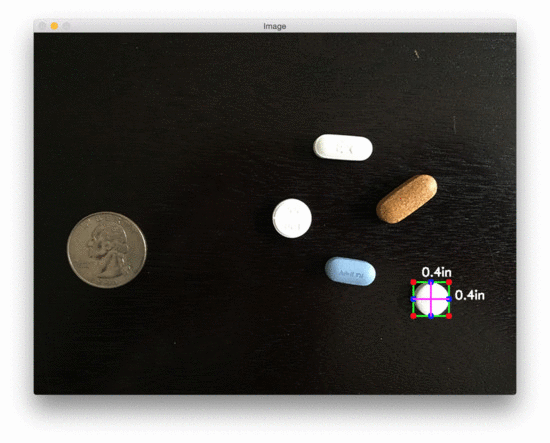
让我们看第二个测量物体尺寸的例子,这次测量药丸的尺寸:
$ python object_size.py –image images/example_02.png –width 0.955
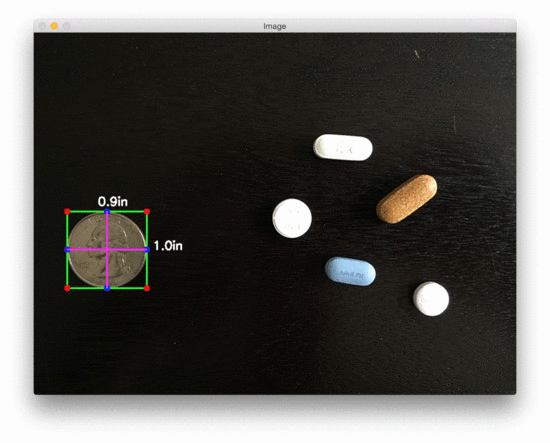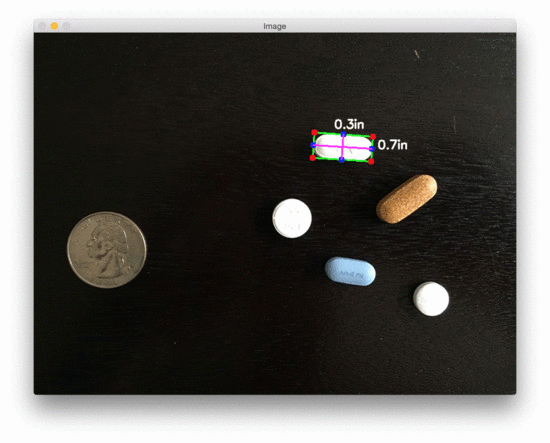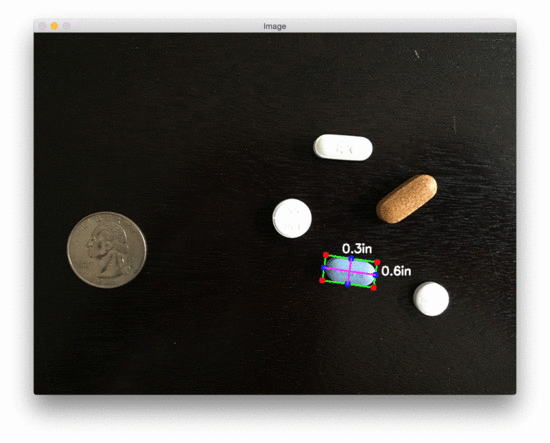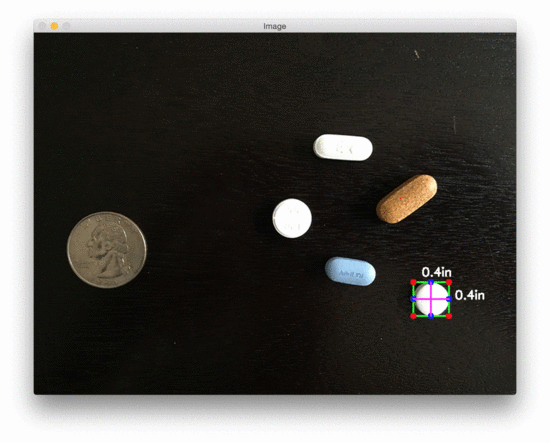 图3:用 OpenCV 测量图像中药丸的尺寸
图3:用 OpenCV 测量图像中药丸的尺寸
在美国,20000 多种处方药中有近 50% 是圆形和/或白色的,因此如果我们能根据它们的测量结果对药片进行过滤,我们就更有可能准确地识别出药物。
最后,我们最后一个例子,这次使用 3.5 英寸 x2 英寸的名片来测量两个唱片 EPs 和一个信封的大小:
$ python object_size.py –image images/example_03.png –width 3.5
 图4:最后一个用 Python + OpenCV 测量图像中物体大小的例子。
图4:最后一个用 Python + OpenCV 测量图像中物体大小的例子。
同样,结果也不是很完美,但这是由于(1)视角和(2)透镜失真,如上所述。
总结
在本篇博客中,我们学习了如何通过 Python 和 OpenCV 检测图像中的物体大小。
就像在我们的教程中,要测量从相机到物体的距离,需要确定「像素/度量」比率,它描述了能够「适应」特定数目的英寸、毫米、米等的像素的数量。
为了计算这个比率,我们需要一个具有两个重要属性的参照物:
- 属性 1:我们知道该参照物的尺寸(比如宽和高)以及其测量单位(英尺,毫米等)。
- 属性 2:该参照物应该很容易找到,无论是在对象的位置上还是在外观上。
如果可以满足这两个属性,那么可以使用该参照物来校准 pixels_per_metric 变量,然后计算图像中其他物体的大小。
在下一篇博文中,我们将进一步介绍这个例子,并学习如何计算图像中各物体之间的距离。
一定要使用下面的表格注册 PyImageSearch 的通讯,当下一篇博客文章发布时,你将会收到通知——你不容错过!
雷锋网字幕组编译
用 OpenCV 检测图像中各物体大小http://t.jinritoutiao.js.cn/dh8HDK/
转载请注明:徐自远的乱七八糟小站 » 用 OpenCV 检测图像中各物体大小



