机器不学习 www.jqbxx.com : 深度聚合机器学习、深度学习算法及技术实战
上一篇文章介绍了CNN的基础知识以及它的优势,今天这篇文章主要来看一看一些著名的卷积神经网络的结构特点,以便我们对CNN有更加直观地认识。
一、LeNet-5
论文:http://yann.lecun.com/exdb/publis/pdf/lecun-01a.pdf
这个可以说是CNN的开山之作,由Yann LeCun在1998年提出,可以实现对手写数字、字母的识别。结构如下:
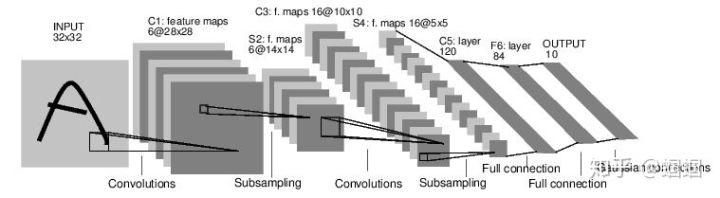
图中的 subsampling,即“亚采样”,就是我们前面说的pooling,因为pooling其实就是对原图像进行采样的一个过程。它总共7层,分别有2个CONV层,2个POOL层,3个FC层。当然,它的输入规模很小,是32×32大小的单通道图片。
我们可以用下面的式子,来表示上面的网络结构:
Input(32×32)–>CONV(6 filters)–>AvgPOOL–>CONV(16 filters)–>AvgPOOL–>FC(120)–>FC(84)–>FC(10)
细节没什么好说的。后面我们可以试着用TensorFlow或者Keras来复现一下。
二、AlexNet
论文:http://vision.stanford.edu/teaching/cs231b_spring1415/slides/alexnet_tugce_kyunghee.pdf
AlexNet于2012年由Alex Krizhevsky, Ilya Sutskever 和 Geoffrey Hinton等人提出,并在2012 ILSVRC (ImageNet Large-Scale Visual Recognition Challenge)中取得了最佳的成绩。这也是第一次CNN取得这么好的成绩,并且把第二名远远地甩在了后面,因此震惊了整个领域,从此CNNs才开始被大众所熟知。
这里简单地说一下这个ILSVRC,它是一个ImageNet发起的挑战,是计算机视觉领域的奥运会。全世界的团队带着他们的模型来对ImageNet中的数以千万的共1000个类别的图片进行分类、定位、识别。这个是一个相当有难度的工作,1000个类别啊。
那我们来看看这个AlexNet的结构把:
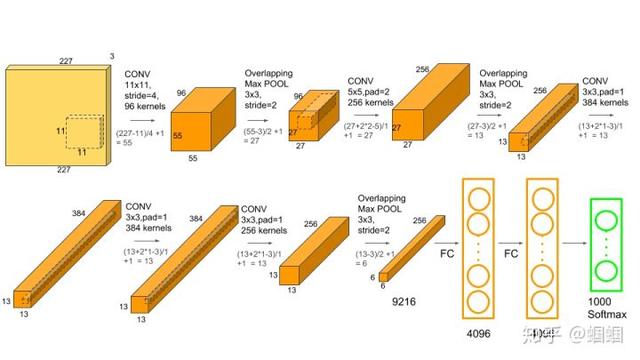
图片来源:https://www.learnopencv.com/understanding-alexnet/
输入的图片是256×256,然后进行随机的裁剪得到227×227大小,然后输入进网络中。可见,这个输入比LeNet的要大得多,这种大小,在当年已经是图片的主流大小了。
AlexNet共有8层,其中5个CONV层和3个FC层,这里没有算上POOL层,因为严格意义上它不算层,因为没有可训练的参数。
关于AlexNet有如下要点:
- 用ImageNet的1500万张来自2万2千个类别的图片进行训练,在两个GTX 580 GPU上训练了5,6天;使用ReLU激活函数,而之前的神经网络,包括LeNet,都是使用sigmoid或者tanh激活函数,AlexNet证明了ReLU函数在效率效果上更佳,速度提高很多倍;使用了很多的数据扩增技术(Dada Augmentation),比如图片反转、剪切、平移等等,来扩充训练集,使得训练的模型鲁棒性更强;第一次使用dropout正则化技术;使用mini-batch SGD(也成随机梯度下降)来加快训练。
总之,AlexNet让人们认识到CNN的强大和巨大的潜能,并为之后的研究提供了很多有用的经验和技术。
三、VGG Net
论文:https://arxiv.org/pdf/1409.1556.pdf
这个网络于2014年被牛津大学的Karen Simonyan 和Andrew Zisserman提出,主要特点是 “简洁,深度”。 深, 是因为VGG有19层,远远超过了它的前辈; 而简洁,则是在于它的结构上,一律采用stride为1的3×3filter,以及stride为2的2×2MaxPooling。所以虽然深,但是结构大家一眼就可以记住。
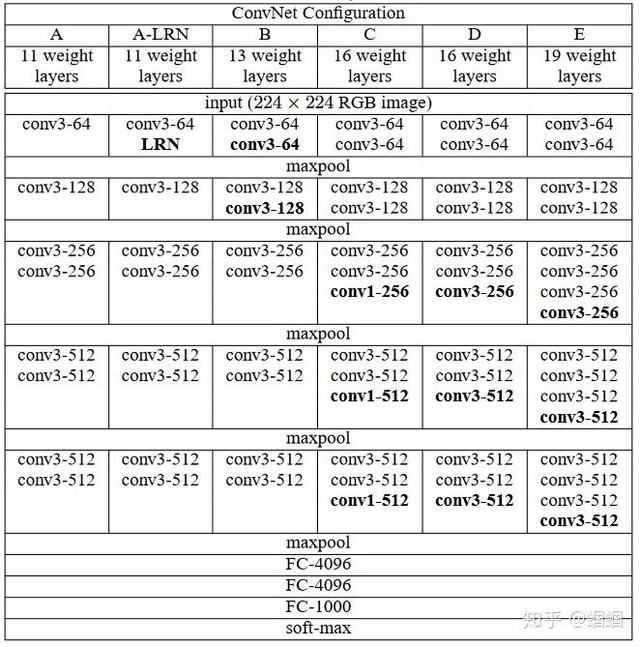
这个图来自于VGG的论文,每一列是他们研究的不同的结构,我们直接看E的那个结构,不难发现,若干个CONV叠加,然后配一个MaxPooling,再若干个CONV,再加一个MaxPooling,最后三个FC。而且,每个MaxPooling之后,CONV的filter的个数都翻倍,分别是64,128,256,512,结构十分规则有规律。
VGG刷新了CNN的深度,其简明的结构更是让人印象深刻。
四、Inception Net(GoogleNet)
论文:https://www.cs.unc.edu/~wliu/papers/GoogLeNet.pdf
看了前面的网络结构之后,我们会发现,他们越来越深,filter越来越多,参数越来越多。 似乎提高CNN的表现的方法就是堆叠更多的CONV、POOL层排成一列(我们称之为sequential model,熟悉keras的同学应该知道)就行了。确实那个时候大家都在想方设法增加网络的层数,让我们的CNN更加庞大。
但我们也应该清楚,一味地增加层数、增加通道数(filters越多,输出图像的通道数就越多),会让我们的计算量急剧增加,模型变得过于复杂,从而更容易过拟合,这样反而会让模型的性能下降。
Inception Net不再是使用Sequential model,在结构上有了重大创新。
在sequential model中,所有操作,无论是CONV还是POOL,都是排成一些序列。但是Google他们就想,为什么不可以同时进行各种操作呢?于是论文的作者有一个大胆的想法,假如我们有3个CONV和一个MaxPOOL,何不让它们平行地运算,然后再整合在一起?:
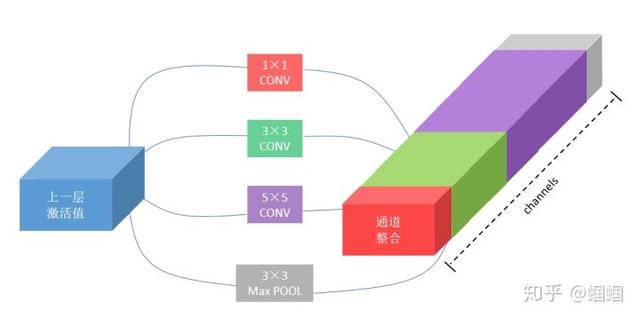
这样做有一个问题,就是,整合在一起之后,channels这个维度会过大。
于是作者想出了一个好办法,那就是使用filter为1×1的CONV来进行降维:
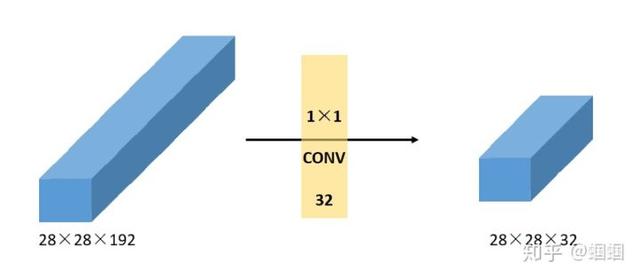
前面学过了卷积的操作,我们知道,一个1×1的filter去卷积,图像的长和宽都不会变化,同时,输出图像的channels数等于filters的个数,所以对于图中的192个channels的图像,我们用32个filter,就可以把维度降低到32维。
于是,我们可以利用1×1CONV的这个特点,来改造上面的整合过程:
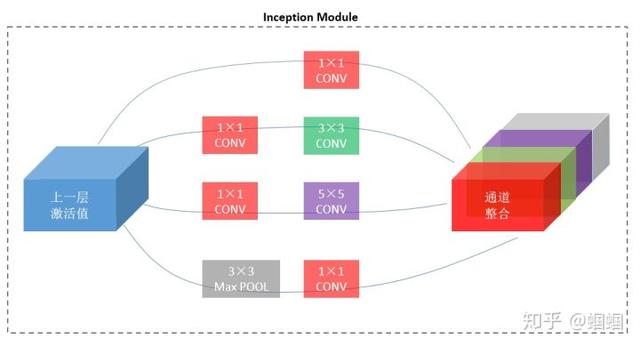
可见,通过使用1×1CONV,输出的通道数大大减少,这样,整个模型的参数也会大大减少。
上面这个部分,称为“Inception Module”,而Inception Network,就是由一个个的inception module组成的:
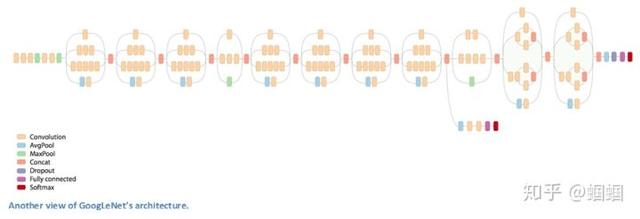
图片来源:https://adeshpande3.github.io/The-9-Deep-Learning-Papers-You-Need-To-Know-About.html
通过inception module,GoogleNet成功地把CNN的层数增加到了超过100层!(如果把一个module当做一层的话,则是22层)。
这个GoogleNet就牛逼了,名副其实地“深”,而且参数的数量也比我们前面介绍的AlexNet要少很多倍!所以训练出的模型不仅效果好,而且更快。
五、ResNet (残差网络)
论文:https://arxiv.org/pdf/1512.03385.pdf
最后要介绍的就是ResNet,于2015年由微软亚洲研究院的学者们提出。
前面讲了,CNN面临的一个问题就是,随着层数的增加,CNN的效果会遇到瓶颈,甚至会不增反降。这往往是梯度爆炸或者梯度消失引起的。
ResNet就是为了解决这个问题而提出的,因而帮助我们训练更深的网络。 它引入了一个 residual block(残差块):
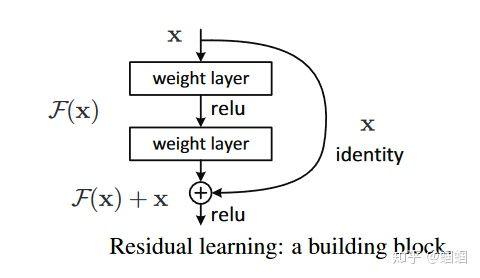
这个图来自原论文。 可以很直观地看出,这个残差块把某一层的激活值,直接一把抓到了后面的某一层之前 ,这个过程称之为“skip connection(跳跃连接)”。 这个做法,相当于把前面的信息提取出来,加入到当前的计算中,论文作者认为,这样的做法,可以 使神经网络更容易优化。事实上却是是这样。
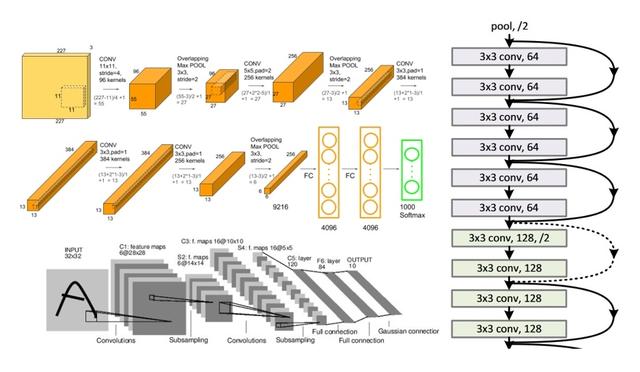
通过这种residual block,他们成功地搭建了一个拥有 152层的CNN!深不见底! 我从论文中截取网络的一部分如下:
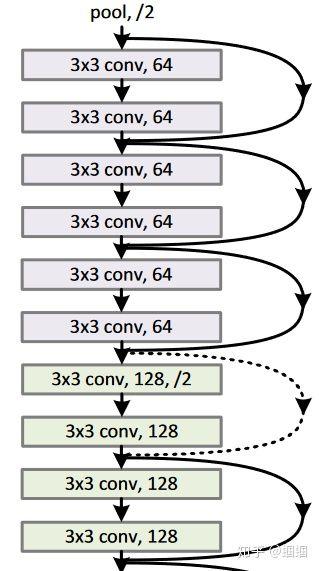
关于具体的细节以及为什么residual block有效,可以查阅原论文或者网上的其他教程。
转自:https://www.zhihu.com/people/guo-bi-yang-78/posts
机器不学习:窥探CNN经典模型——他山之玉 可以攻石http://t.jinritoutiao.js.cn/dJjrA3/
转载请注明:徐自远的乱七八糟小站 » 机器不学习:窥探CNN经典模型——他山之玉 可以攻石



