【有了Python+Tensorflow!所有验证码识别都能快人一步!快速识别】

验证码分析和处理
网上搜索验证码识别能够得到很多教程,但大部分都是将验证码切割成单个字符训练,有时候 验证码字符大小不一或者发生重叠,切割验证码变得不适用。因此通过CNN技术将整块验证码进行识别,能使问题变得更加简单(以下操作对其他验证码分析有参考作用)。小编推荐大家加一下这个群:103456743这个群里好几千人了!大家遇到啥问题都会在里面交流!而且免费分享零基础入门料资料web开发 爬虫资料一整套!是个非常好的学习交流地方!也有程序员大神给大家热心解答各种问题!很快满员了。欲进从速哦!各种PDF等你来下载!全部都是免费的哦!只为帮助大家快速入门,所以小编在群里等你们过来一起交流学习呢!
在这里我们选择模拟学习这样的验证码:
该验证码来源于这里(正如sci-hub网站所言”to remove all barriers in the way of science”,知识就该如此)。

该验证码只由六位小写字母、噪点和干扰线组成,如果能去除噪点和干扰线,能够大大降低学习的难度。很多验证码的噪点和干扰线RGB值和字母的不一致,这个我们能通过Photoshop来分析,使用颜色取样器工具,分别在图片噪点、干扰线、空白处和字母处点击获得RGB值,如下图:

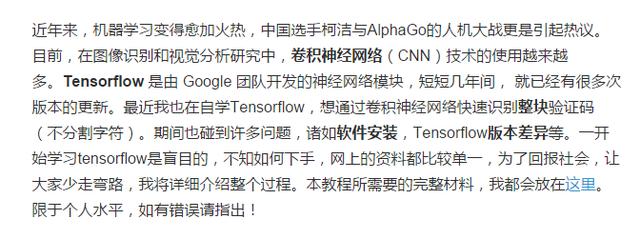
分析后发现,只要将图片二值化只保留字母,就能得到不错的输入图片:

实现代码如下:
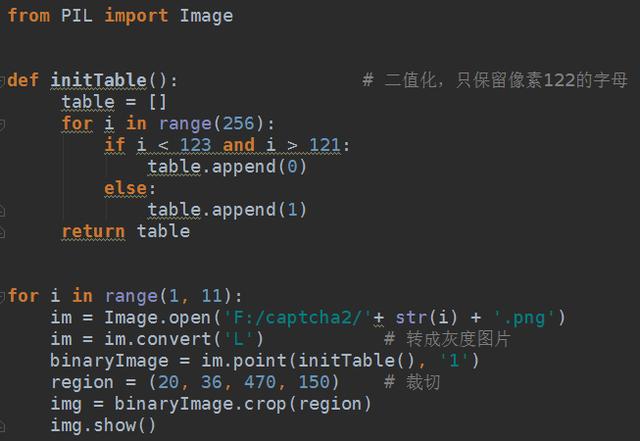


然后点击+按钮,输入tensorflow,install package。

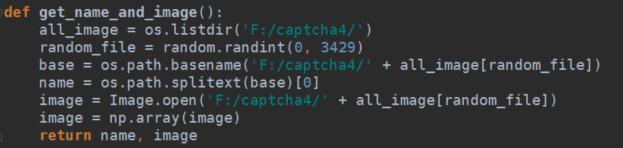
接下来定义一个函数,随机从训练集(3430张)中提取验证码图片,由于验证码经过我手动打标签(码了6小时),在这里只要获取验证码的名字和图片就够了,我默认放在”F:/captcha4/”目录下,需要注意的是返回的图片是以矩阵的形式。
接下来定义两个函数,将名字转变成向量,将向量转变成名字。
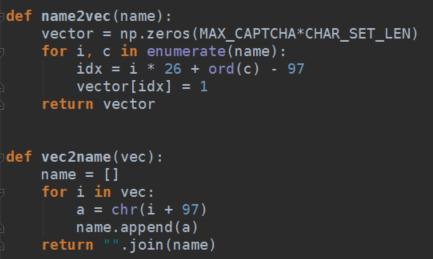
生成一个训练batch,也就是采样的大小,默认一次采集64张验证码作为一次训练,需要注意通过get_name_and_image()函数获得的image是一个含布尔值的矩阵,在这里通过1*(image.flatten())函数转变成只含0和1的1行114*450列的矩阵。

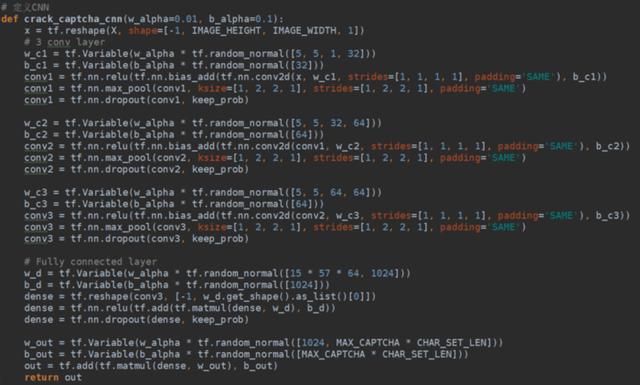
接下来定义卷积神经网络结构,我们采用3个卷积层加1个全连接层的结构,在每个卷积层中都选用2*2的最大池化层和dropout层,卷积核尺寸选择5*5。需要注意的是在全连接层中,我们的图片114*450已经经过了3层池化层,也就是长宽都压缩了8倍,得到15*57大小。
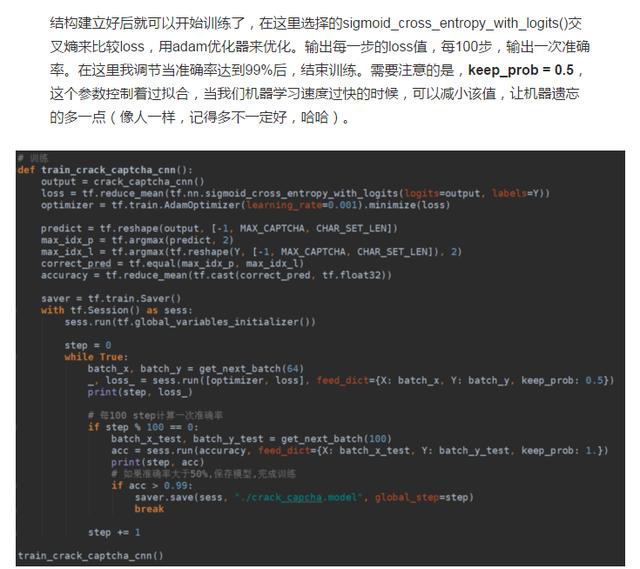
训练完成后,你应该会得到如下几个文件。在这里我花了将近9个小时跑了1800步,达到99.5%的准确率。输出文件的详细介绍参考这里。
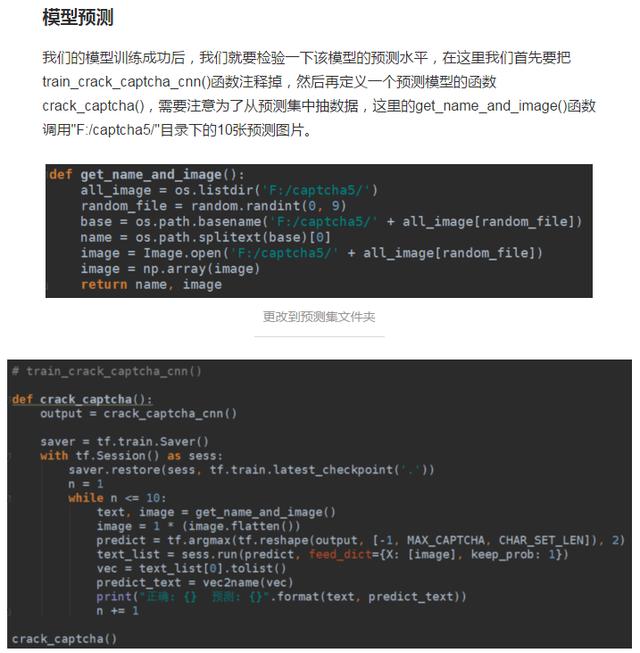
预测结果如下:


希望大家以后在tensorflow的学习道路中少点阻碍!!!



