【基于Python3开发的自动签到拿京豆软件-1.源码及调试过程】
京东网站上,在京东会员首页,有每日签到会送京豆;在我的京东-我的京豆页,有进店签到领京豆;在我的京豆-流量加油站页,有签到领流量。我们用Python来开发写程序,实现每天自动领京豆和流量。主要用到Python,selenium模块和 BeautifulSoup模块。
一、源码
from bs4 import BeautifulSoup
from selenium import webdriver
import time
browser = webdriver.Firefox()#用火狐浏览器
browser.get(‘http://vip.jd.com/home.html’)#打开登录页面
browser.find_element_by_link_text(‘账户登录’).click()
browser.find_element_by_id(‘loginname’).send_keys(‘你的用户名’)
browser.find_element_by_id(‘nloginpwd’).send_keys(‘密码’)
browser.find_element_by_xpath(‘//*[@id=”loginsubmit”]’).click()
time.sleep(1)
try:
browser.find_element_by_class_name(‘sign-in’).click()
print(‘签到成功’)
except:
print(‘不能重复签到,签到失败’)
#print(browser.current_window_handle)调试程序时查看当前的网页句柄
browser.get(‘http://bean.jd.com/myJingBean/list’)
time.sleep(1)
#print(browser.current_window_handle)
#handles = browser.window_handles
#print(handles)
soup = BeautifulSoup(browser.page_source)
ylink =soup.find_all(class_ = ‘s-btn’)
#print(ylink)
for link in ylink:
#print(link.get(‘href’))
browser.get(link.get(‘href’))#获得网址并直接打开
time.sleep(1)
browser.find_element_by_link_text(‘签到’).click()
time.sleep(1)
time.sleep(1)
browser.get(‘http://datawallet.jd.com/profile.html’)
time.sleep(1)
browser.find_element_by_class_name(‘btn-sign’).click()
time.sleep(1)
browser.quit()
二、开发环境的搭建:
- 安装Python3(自行搜索安装,这里不作介绍);
- 安装selenium模块和 BeautifulSoup模块
selenium模块让Python直接控制浏览器,实际点击链接,填写登录信息,几乎就像是有一个人类用户在与页面交互。与Requests和BeautifulSoup相比,selenium允许你用高级的多的方式与网页交互。
安装方法:pip install selenium;
在Python中调用:from selenium import webdriver
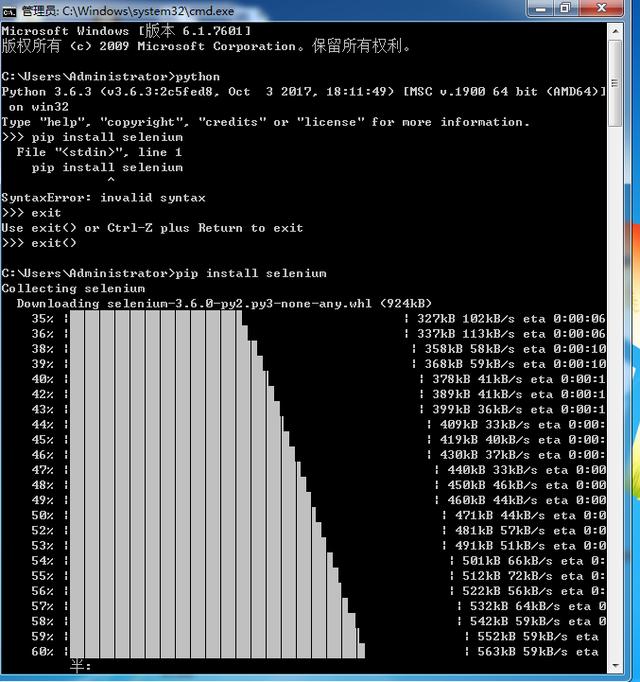
BeautifulSoup模块的名称是bs4(表示 BeautifulSoup第4版),用于从HTML页面(网页源码)中提取信息(比正则表达式要好很多)。
安装方法:在命令行中运行pip install beautifulsoup4;
在Python中调用:from bs4 import BeautifulSoup
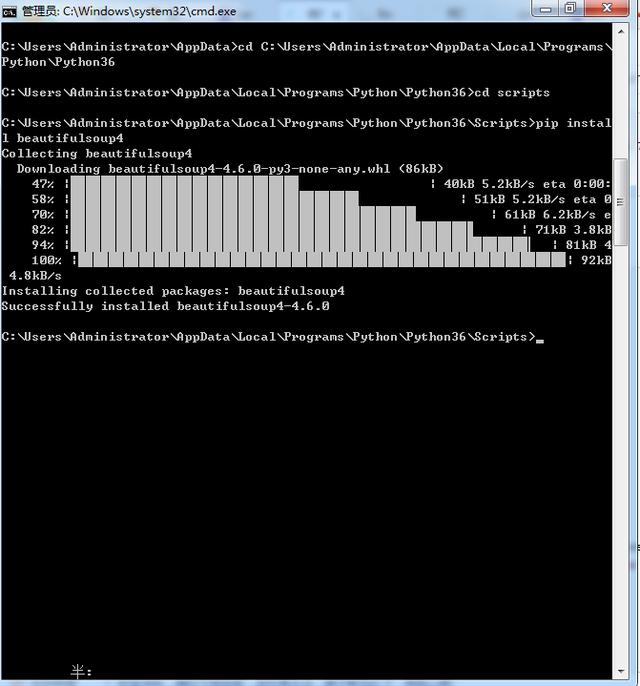
3.安装火狐浏览器(自行下载最新版安装),下载并配置火狐浏览器驱动 geckodriver
geckodriver的下载链接:https://github.com/mozilla/geckodriver/releases
将下载好的geckodriver解压后,将geckodriver.exe放在安装过火狐浏览器的目录下,本机在C:Program Files (x86)Mozilla Firefox;
三、需求分析
第一步,打开浏览器,进入京东登录页面,自动登录;
第二步,签到页点击签到;
第三步,进店签到领京豆栏获得店铺的网址,进入相应店铺点击签到;
第四步,进入签到领流量页面,点击签到领流量。
第一步:
from bs4 import BeautifulSoup
from selenium import webdriver
import time
browser = webdriver.Firefox()#用火狐浏览器
browser.get(‘http://vip.jd.com/home.html’)#打开登录页面
browser.find_element_by_link_text(‘账户登录’).click()
browser.find_element_by_id(‘loginname’).send_keys(‘你的用户名’)
browser.find_element_by_id(‘nloginpwd’).send_keys(‘密码’)
browser.find_element_by_xpath(‘//*[@id=”loginsubmit”]’).click()
第二步:
browser.find_element_by_class_name(‘sign-in’).click()
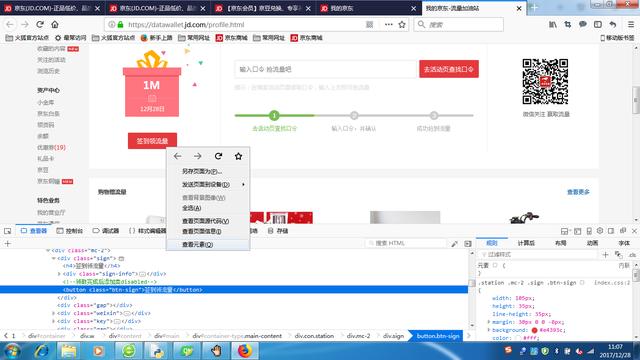
- 火狐浏览器有一个功能很方便,定位页面元素,鼠标放在要定位的元素上,右键单击,选择(查看元素),即可看到相应元素的网页源码,在相应的 网页代码上右键单击-复制-Xpath项可以直接获得元素的路径。
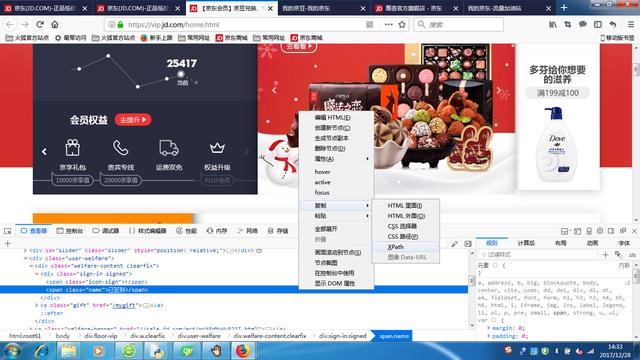
2.selenium模块在页面中寻找元素的方法browser.find_element_by_…;browser.find_elements_by_…
(此处自行搜索学习)。需要注意的一点是browser.find_elements_by_…返回的是一个列表,不能使用.click()进行点击。
第三步:
进入我的京东-我的京豆页面,browser.get(‘http://bean.jd.com/myJingBean/list’);
使用BeautifulSoup模块读取当前页面的网页源码,soup = BeautifulSoup(browser.page_source);
通过火狐浏览器的查看元素功能,仔细看寻找一下我们要点击进入的各个店铺的链接代码,我们发现,总共有9个店铺,在网页中的代码是9个<li>….</li>,我们的思路是从这9个<li>….</li>源码中获得店铺的链接地址,而后进入店铺页面,在店铺页面中,通过 寻找有“签到”两个字的元素进行点击(browser.find_element_by_link_text(‘签到’).click())。
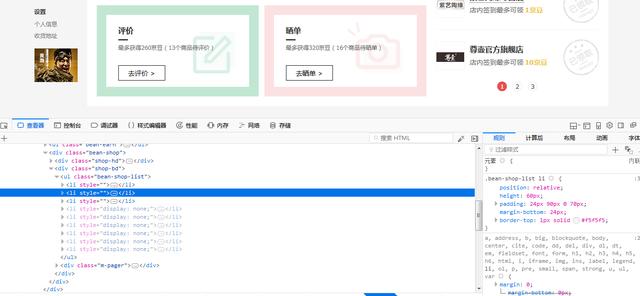
签到后的状态

ylink =soup.find_all(class_ = ‘s-btn’)
#print(ylink)
for link in ylink:
#print(link.get(‘href’))
browser.get(link.get(‘href’))#获得网址并直接打开
time.sleep(1)
browser.find_element_by_link_text(‘签到’).click()
time.sleep(1)
第四步:
进入我的京东-流量加油站页面,browser.get(‘http://datawallet.jd.com/profile.html’);
通过查看网页源代码,我们通过class name定位元素,browser.find_element_by_class_name(‘btn-sign’).click()。
最后退出浏览器。



