【如何用卷积神经网络从歌曲中提取纯人声?这里有教程+代码】
安妮 编译整理自 Madebyollin博客
量子位 报道 | 公众号 QbitAI
你应该对阿卡贝拉(Acapella)不陌生吧。这种无伴奏合唱的纯音乐起源于中世纪的教会音乐,虽曾一度濒临灭绝,但在今天人们又开始怀念起这种纯人声合唱。
这阵猝不及防“Acapella热”仿佛唤起人们对这种原始音乐形式的渴望。很多音乐人发现将纯人声清唱用来混音听觉效果很好,但无奈纯人声资源目前很难寻找。因此,音乐论坛中尝尝出现“一曲难求”的景象。
幸运的是,坐落于华盛顿大学的程序猿Ollin Boer Bohan(Twitter:@madebyollin)发布在GitHub上的代码可以解决这个问题。这个程序可以过滤掉一段音乐中的伴奏,将纯人声部分提取出来。比如,这首来自Vicetone的金曲《No Way Out》,纯人声部分就是这样的。
no_way_out_acapella
01:02
去原文听纯人声和带配乐版对比:
http://www.madebyollin.com/posts/cnn_acapella_extraction/
它是怎样实现的?
模型背后,其实隐藏着对程序猿对纯人声的理解——
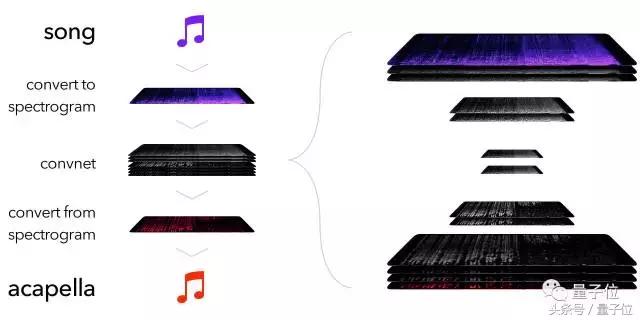
人声和乐器声,有着不同的特征,表现在声谱图上也不一样。Ollin Boer Bohan所做的,就是将一首歌曲先转化为声谱图,利用卷积神经网络(Convolutional Neural Network, CNN)进行图像识别,再将识别所得的新声谱图转化成音频,生成最后的纯人声部分。整个过程大致如下图所示:
这部分的实现代码:
|
1 |
mashup = Input(shape=(None, None, 1), name='input') |
这里的训练数据是基于人声和器乐伴奏的组合动态产生的,并且以每分钟128拍(Beat Per Minute, BMP)为标准,涵盖了男女两种音色。这样和用成对的人声/带伴奏歌曲来训练效果差不多,但获取数据的效率更高。
除了文章开头的No Way Out,原文中还给出了更多纯人声与原曲对照的例子。
在这些例子中,人声的过滤并不算完美。作者对模型的特点进行了一些总结:
这个模型在本地信息充足,或者人声音量相对较大的情况下,伴奏声会过滤得比较好。但真正的音乐还包含着更多、更微妙的情况需要模型去推断。很遗憾,这个模型目前还不能处理这么复杂的问题。
有待改进的地方
作者说,他还是神经网络和信号处理新手,这个模型可能还有改进的空间。以下是他希望有机会改进的方面:
完善频率信息:我试了多种方法,将更全面的频率信息整合到模型中,发现这些模型可以减少音质损失,但并不能在这个模式框架里改善性能。我不确定问题的原因是过拟合还是没选好损失函数,所以我并没有把这些频率信息增加到代码库。
更好的损失函数:我目前采用的是均方误差,但更强的模型试验表明均方误差与实际运行表现关联性并不是很好。
立体声信息:目前,该模型只输入/输出单声道数据。用立体声通道训练可能会提高模型从同频率其他声音中识别人声的性能。
更好的时频变换(Time-frequency Transforms):我目前使用短时傅里叶变换(STFT)来处理输入数据,但还不清楚这是不是最好的选择。
最后,对这个模型感兴趣的同学,记得去看原文和代码:
原文:http://www.madebyollin.com/posts/cnn_acapella_extraction/
代码:https://github.com/madebyollin/acapellabot
招聘
我们正在招募编辑记者、运营等岗位,工作地点在北京中关村,期待你的到来,一起体验人工智能的风起云涌。
相关细节,请在公众号对话界面,回复:“招聘”两个字。
One More Thing…
今天AI界还有哪些事值得关注?在量子位(QbitAI)公众号会话界面回复“今天”,看我们全网搜罗的AI行业和研究动态。笔芯~



