机器学习将越来越依赖FPGA和SoC
本文由EETOP翻译自 semiengineering,作者:KEVIN FOGARTY
一系列机器学习优化芯片预计将在未来几个月内开始出货,但数据中心需要一段时间才能决定这些新的加速器是否值得采用,以及它们是否真的能在性能上获得大幅提升。
有大量的报道称,为机器学习设计的定制芯片将提供100倍于现有选择的性能,但它们在要求严格的商业用途的实际测试中的功能尚未得到证实,数据中心是新技术最保守的采用者之一。不过,Graphcore、Habana、ThinCI和Wave Computing等知名初创公司表示,它们已经将早期芯片提供给客户进行测试。但还没有一家公司开始发货,甚至没有展示这些芯片。
这些新设备有两个主要市场。机器学习中的神经网络将数据分为两个主要阶段:训练和推理,并且在每个阶段中使用不同的芯片。虽然神经网络本身通常驻留在训练阶段的数据中心中,但它可能具有用于推理阶段的边缘组件。现在的问题是什么类型的芯片以及哪种配置能够产生最快、最高效的深度学习。
看来FPGAs和SoCs正在获得更多的吸引力。Tirias Research总裁吉姆·麦格雷戈(Jim McGregor)说,这些数据中心需要可编程芯片的灵活性和高I/O能力,这有助于FPGA在训练和推理的高数据量、低处理能力需求中发挥作用。
与几年前相比,FPGA的设置现在用于训练的频率更低了,但它们在其他任何事情上的使用频率都要高得多,而且它们很可能在明年继续增长。即使大约50家致力于神经网络优化处理器迭代开发的初创公司今天都交付了成品,在任何规模可观的数据中心的生产流程中,也需要9到18个月的时间。
McGregor说:“没有人会买现成的数据中心,然后把它放到生产机器上。”“您必须确保它满足可靠性和性能要求,然后才能将其全部部署。”
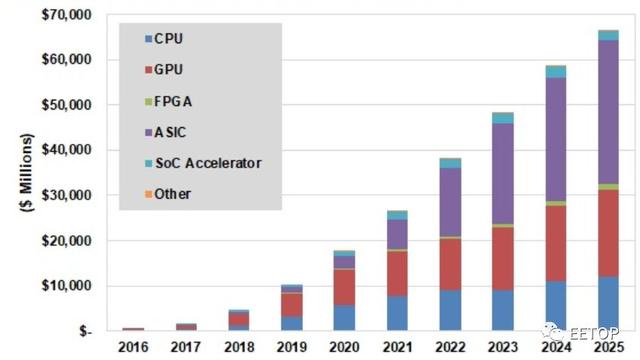 图1:不同类型深度学习芯片占比
图1:不同类型深度学习芯片占比
对于新的架构和微体系架构,仍然有机会。ML工作负载正在迅速扩展。OpenAI 5月份的一份报告显示,用于最大AI/ML训练的计算能力每3.5个月就增加一倍,自2012年以来,计算能力的总量增加了30万倍。相比之下,按照摩尔定律,可用资源每18个月增加一倍,最终总容量仅增加12倍。
Open.AI指出,用于最大规模训练的系统(其中一些需要几天或几周的时间才能完成)需要花费数百万美元购买,但它预计,用于机器学习硬件的大部分资金将用于推理。
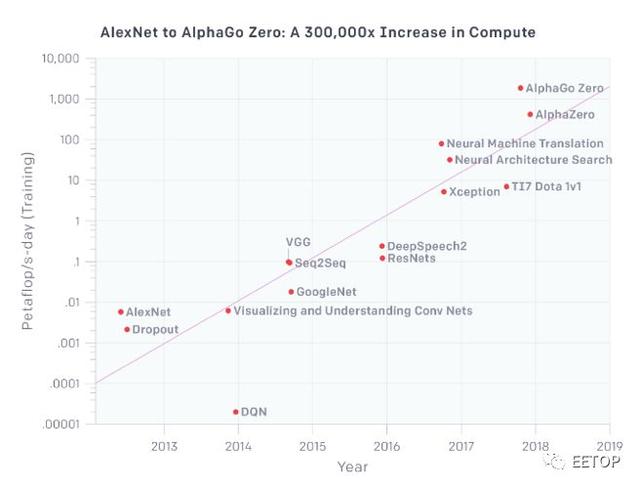 图2:计算需求正在增加
图2:计算需求正在增加
这是一个巨大的全新的机遇。Tractica在5月30日的一份报告中预测,到2025年,深度学习芯片组的市场规模将从2017年的16亿美元增至663亿美元,其中包括CPU,GPU,FPGA,ASIC,SoC加速器和其他芯片组。其中很大一部分将来自于非芯片公司,它们正在发布自己的深度学习加速器芯片组。谷歌的TPU就是这么做的,业内人士表示,亚马逊和Facebook正在走同样的道路。
McGregor说,现在主要转向SoC而不是独立的组件,并且SoC、ASIC和FPGA供应商的策略和封装的多样性日益增加。
Xilinx、Inetel和其他公司正试图通过向FPGA阵列添加处理器和其他组件来扩大FPGA的规模。其他的,如Flex Logix、Achronix和Menta,将FPGA资源嵌入到靠近SoC特定功能区域的小块中,并依赖高带宽互连来保持数据的移动和高性能。
McGregor说:“你可以在任何你想要可编程I/O的地方使用FPGA,人们会将它们用于推理,有时还会进行训练,但是你会发现它们会更多地用于处理大数据任务而不是训练,这需要大量的矩阵乘法,更适合于GPU。”
然而,GPU并不是濒临灭绝的物种。根据MoorInsights & Strategy分析师Karl Freund在一篇博客文章中所说。
英伟达本月早些时候公布了NVIDIA TensorRT超大尺寸推理平台的声明,其中包括提供65TFLOPS用于训练的Tesla T4 GPU和每秒260万亿次4位整数运算(TOPS)的推理 – 足以同时处理60个视频流速度为每秒30帧。它包括320“Turing Tensorcores”,针对推理所需的整数计算进行了优化。
新的架构
Graphcore是最著名的初创公司之一,正在开发一款236亿晶体管的“智能处理单元”(IPU),具有300MB的片上存储器,1216个核心,每个核心可以达到11GFlops,内部存储器带宽为30TB/s。其中两个采用单个PCIe卡,每个卡都设计用于在单个芯片上保存整个神经网络模型。
GraphCore即将推出的芯片基于图形架构,该架构依赖于其软件将数据转换为顶点,其中数字输入,应用于它们的函数(加,减,乘,除)和结果是单独定义的,可以是并行处理。其他几家ML初创公司也使用类似的方法。
Wave Computing没有透露何时发货,但在上周的人工智能硬件会议上透露了更多关于其架构的信息。该公司计划销售系统而不是芯片或电路板,使用带有15 Gbyte /秒端口的16nm处理器和HMC存储器和互连,这种选择旨在快速推送图形通过处理器集群而无需通过处理器发送数据超过瓶颈一个PCIe总线。该公司正在探索转向HBM内存以获得更快的吞吐量。
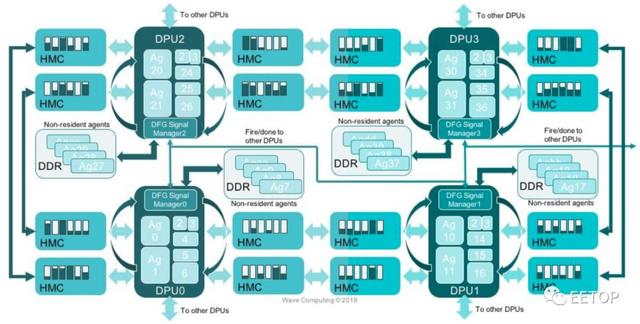 图3:Wave计算的第一代数据流处理单元
图3:Wave计算的第一代数据流处理单元
机器学习的异构未来和支持的硅片的最佳指标之一来自微软 – 这是FPGA,GPU和其他深度学习的巨大买家。
“虽然面向吞吐量的架构,如GPGPUs和面向批处理的NPU,在离线训练和服务中很受欢迎,但对于DNN模型的在线、低延迟的服务,它们的效率并不高,”2018年5月发表的一篇论文描述了Brainwave 项目,这是微软在deep neural networking (DNN)中高效FPGA的最新版本。
微软率先将FPGA广泛用作大规模数据中心DNN推理的神经网络推理加速器。 Rambus的杰出发明人兼企业解决方案技术副总裁Steven Woo表示,该公司不是将它们用作简单的协处理器,而是“更灵活,一流的计算引擎”。
根据微软的说法,Brainwave项目可以使用英特尔Stratix 10 FPGA池提供39.5 TFLOPS的有效性能,这些FPGA可以被共享网络上的任何CPU软件调用。框架无关系统导出深度神经网络模型,将它们转换为微服务,为Bing搜索和其他Azure服务提供“实时”推理。
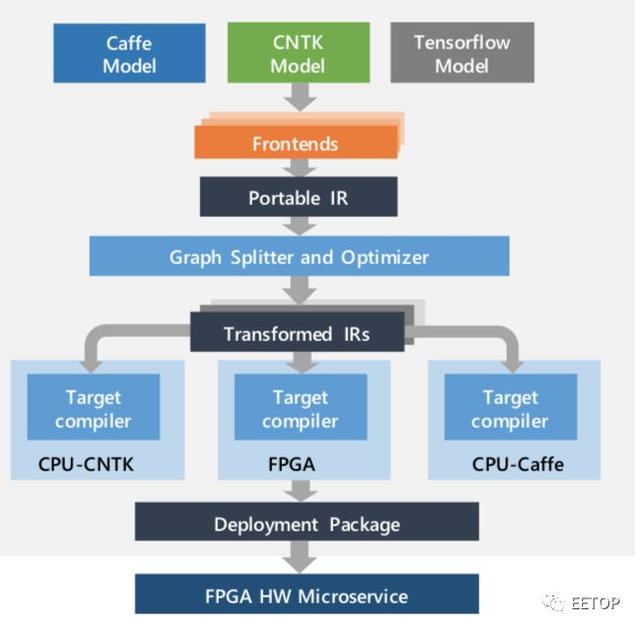 图4:微软的Brainwave项目将DNN模型转换为可部署硬件微服务,将任何DNN框架导出为通用图形表示,并将子图分配给CPU或FPGA
图4:微软的Brainwave项目将DNN模型转换为可部署硬件微服务,将任何DNN框架导出为通用图形表示,并将子图分配给CPU或FPGA
Brainwave是德勤全球(DeloitteGlobal)所称的“戏剧性转变”的一部分,这一转变将强调FPGA和ASIC,到2018年,它们将占据机器学习加速器25%的市场份额。2016年,CPU和GPU占据了不到20万台的市场份额。德勤预测,到2018年,CPU和GPU将继续占据主导地位,销量将超过50万部,但随着ML项目数量在2017年至2018年翻一番、在2018年至2020年再翻一番,总市场将包括20万FPGA和10万ASIC。
德勤(Deloitte)表示,FPGA和ASIC的耗电量远低于GPU、CPU,甚至比谷歌每小时75瓦的TPU耗电量还要低。它们还可以提高客户选择的特定功能的性能,这可以随着编程的变化而改变。
Achronix的营销副总裁SteveMensor说:“如果人们有他们的选择,他们会在硬件层面上用ASIC构建东西,但是FPGA比GPU有更好的功耗/性能,而且他们在定点或可变精度架构方面非常擅长。”
ArterisIP的董事长兼首席执行官CharlieJanac说:“有很多很多的内存子系统,你必须考虑低功耗和物联网应用,网格和环路。”“所以你可以把所有这些都放到一个芯片中,这是你决策物联网芯片所需要的,或者你可以添加高吞吐量的HBM子系统。但是工作负载非常特殊,每个芯片有多个工作负载。因此,数据输入是巨大的,尤其是如果你要处理雷达和激光雷达之类的东西,而这些东西没有先进的互连是不可能存在的。
由于应用程序的特殊性,连接到该互连的处理器或加速器的类型可能会有很大的不同。
NetSpeed Systems负责营销和业务开发的副总裁阿努什•莫罕达斯(Anush Mohandass)表示:“在核心领域,迫切需要大规模提高效率。”““我们可以放置ASIC和FPGA以及SoC,我们的预算越多,我们就可以放入机架。”但最终你必须高效;你必须能够进行可配置或可编程的多任务处理。如果你能将多播应用到向量处理工作负载上,而向量处理工作负载是大部分训练阶段的内容,那么您能够做的事情就会大大扩展。“
FPGA并不是特别容易编程,也不像乐高积木那样容易插入设计,尽管它们正在朝着这个方向快速发展,SoC比FPGA更容易使用计算核心、DSP核心和其他IP模块。
但是,从类似SoC的嵌入式FPGA芯片转变为具有针对机器学习应用优化的数据背板的芯片上的完整系统并不像听起来那么容易。
Mohandass说:“性能环境是如此的极端,需求是如此的不同,以至于AI领域的SoC与传统的架构完全不同。”“现在有更多的点对点通信。你正在做这些向量处理工作,有成千上万的矩阵行,你有所有这些核心可用,但我们必须能够跨越几十万个核心,而不是几千个。
性能是至关重要的。设计、集成、可靠性和互操作性的便捷性也是如此——SoC供应商将重点放在底层框架和设计/开发环境上,而不仅仅是针对机器学习项目的特定需求的芯片组。
NetSpeed推出了专门为深度学习和其他人工智能应用程序设计的SoC集成平台的更新版本,该服务使集成NetSpeed IP变得更容易,该设计平台使用机器学习引擎推荐IP块来完成设计。该公司表示,其目标是在整个芯片上提供带宽,而不是传统设计的集中式处理和内存。
Mohandass说:“从ASIC到神经形态芯片,再到量子计算,一切都在进行中,但即使我们不需要改变我们当前架构的整体基础(以适应新的处理器),这些芯片的大规模生产仍遥遥无期。”但我们都在解决同样的问题。当他们从上到下进行工作时,我们也从下到上进行工作。
Flex Logix的CEOGeoff Tate认为,CPU仍然是数据中心中最常用的数据处理元素,其次是FPGA和GPU。但他指出,需求不太可能在短时间内下降,因为数据中心试图跟上对自己的机器学习应用程序的需求。
泰特说:“现在人们花了很多钱来设计出一种比GPU和FPGA更好的产品。”“总的趋势似乎是神经网络的硬件更加专业化,所以这就是我们可能会走向的地方。”例如,微软表示,他们使用所有东西——CPU、GPU、TPU和FPGA——根据这些,他们可以在特定的工作负载下获得最佳的性价比。
原文链接:https://semiengineering.com/machine-learning-shifts-more-work-to-fpgas-socs/
机器学习将越来越依赖FPGA和SoChttp://t.jinritoutiao.js.cn/d4g3rK/
转载请注明:徐自远的乱七八糟小站 » 机器学习将越来越依赖FPGA和SoC



