
深度神经网络
在学习或编程深度神经网络时,最重要的是以矩阵的形式排列数据。而使用Keras就像将数据以矩阵的形式排列并提供给它一样简单。没有必要定义权重和偏差。
本文是为那些想要使用numpy或低级TensorFlow来编写深度模型的人的指南。
这篇文章描述:
- 我们可以通过多少方式安排输入数据。
- 增加输入和权重的不同方法。
- 如何根据输入数据布局定义权重和偏差。
- 如何使尺寸正确。
- 推广上述尺寸问题,根据层计算权重和偏差的尺寸。
矩阵尺寸:
有两种类型我们可以在矩阵中排列数据:
- 1)将特征排列为列
- 2)将特征排列为行
作为列的特征:
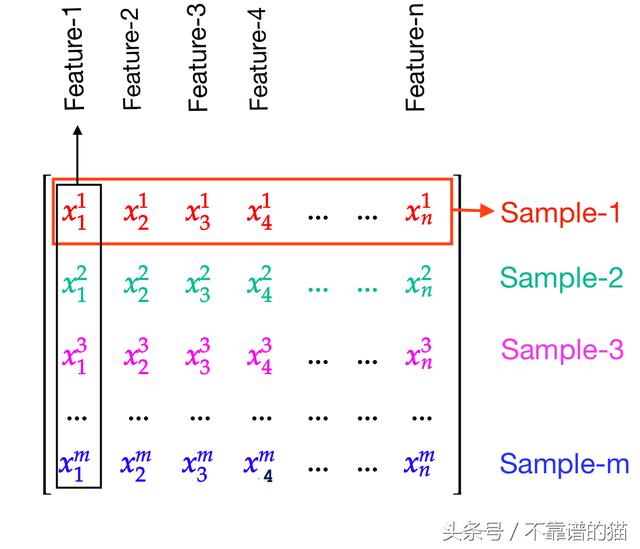
特征排列为列
在这种类型中,特征被排列为列,并且样本被排列为行。
例如,具有n特征和1样本的矩阵如下所示:
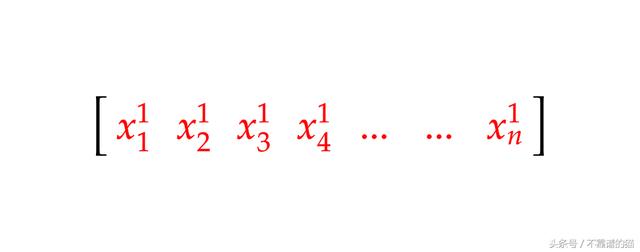
这得到了Keras和其他在线教程的支持。
行的特征:

特征排列为行
在这种类型中,特征排列为行,样本排列为列。
例如,具有n特征和1样本的矩阵如下所示:
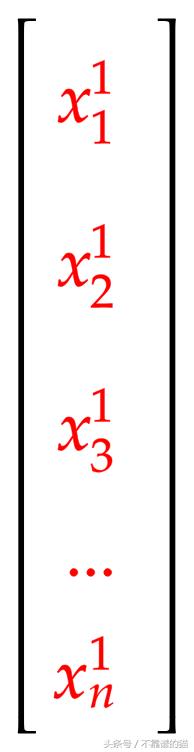
这是由Andrew Ng支持的。
矩阵运算:
操作顺序取决于我们如何安排数据。
- 如果数据按列排列的特征: X*W + B
- 如果数据按行排列的特征: W*X + B
其中,W =权重矩阵,X =输入矩阵,B =偏差矩阵
如果输入数据排列发生变化,为什么公式会发生变化?

Multi-perceptron
我们需要将输入乘以其相应的权重并将它们全部相加。
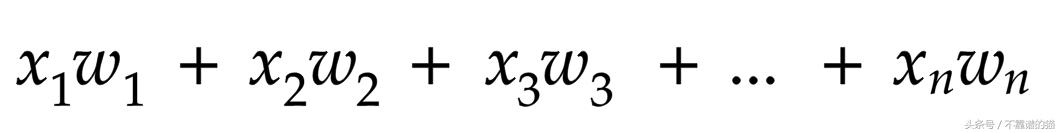
简化为
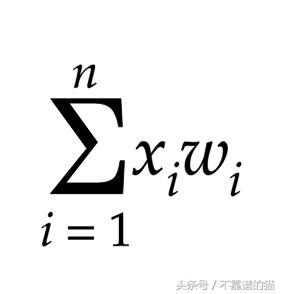
通常矩阵乘法如下:
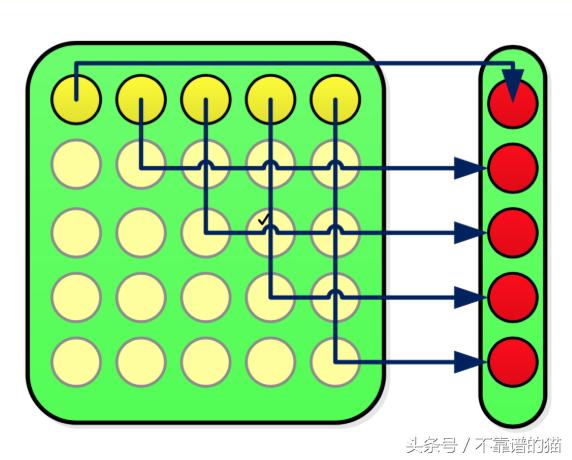
矩阵乘法
注意:为简单起见,请忽略上图中的淡黄色圆点。
想象一下,黄色 =输入,深黄色 =样品-1和红色 =权重。(这里我们按照列排列的特征)
上图代表我们的等式:
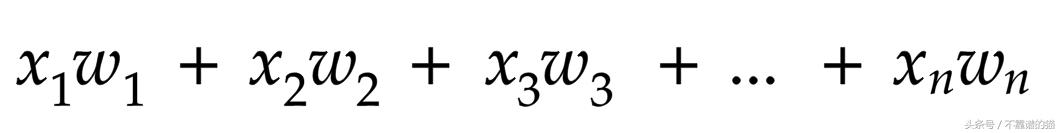
矩阵乘法
因此,如果我们将数据排列为列的特征,我们必须使用X*W+B
同样的事情适用于排列为行的特征(只需反转上述符号,如黄色 =权重,深黄色 =权重对应于样本-1,红色 =样本-1)。
所以,现在我们知道输入排列如何影响我们需要使用的公式。
矩阵的维数:
与Keras不同,在TensorFlow和Numpy中,我们需要定义每个权重和偏差。
现在,基于输入维数和输出维数,我们得到了偏置和权值矩阵的维数。
排列为行的特征:
首先,我们显然决定每层中的层数和节点数。

具有2个隐藏层的深度神经网络
所以,这里我们已经知道输入层和输出层的矩阵尺寸。
即
第0层有4个输入和6个输出
第1层有6个输入和6个输出
第2层有6个输入和2个输出
第3层有2个输入和2个输出
现在我们只需要计算权重和偏差的尺寸。
我们考虑作为输入和输出维度的排列为列的特征。
一次,计算机每个线程/核心只能使用1个样本。
因此,如果我们有1024个内核(GPU),那么它使用1个样本x 1024
这是我们的基本等式:我们不知道W&B的维度
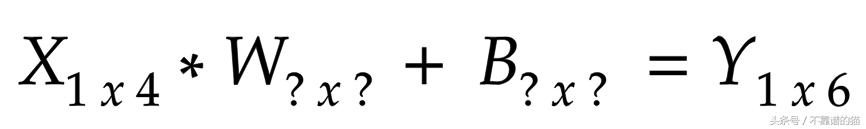
方程式我们开始
我们知道1st Matrix列应该等于2nd Matrix行以执行矩阵乘法。
所以,我们用X的列更新W的行。

更新W的行维度
接下来,我们更新偏差。我们知道Matrix Addition不会更改生成的Matrix维度。因此,B的维数必须等于得到的矩阵Y.

更新B的尺寸
现在,我们只剩下找到W的列。
我们知道矩阵相乘会改变输出矩阵的维数。
因此,当我们将X和W相乘时,结果尺寸必须等于B才能执行矩阵加法。

更新W的列维度
我们得到了Layer-1的尺寸。
对于Layer-2和Layer-3:
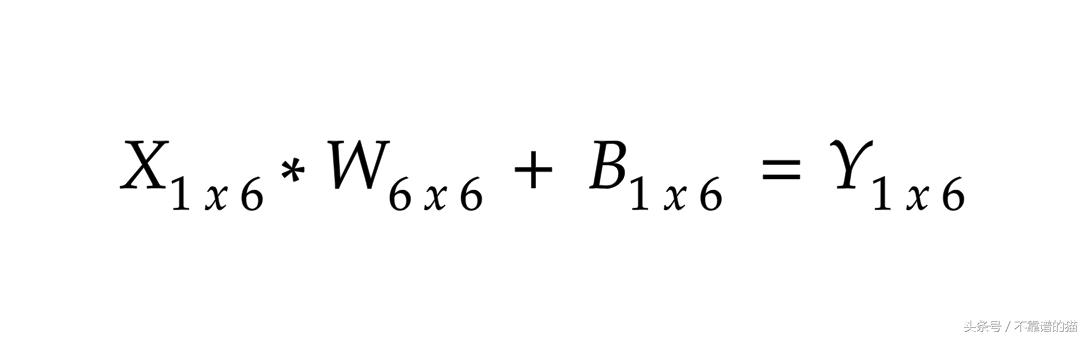
对于Layer – 2

对于Layer – 3
最后我们得到了带有1×2维的输出Y。
推广上述方法:
我们可以推广上述方程式来计算基于层的尺寸。
为此,我们只考虑计算的层和Layer-0不需要任何计算,因为它是输入层。
如果我们观察上面的3个方程,我们可以看到模式:
以列排列的特征:
基本方程式:
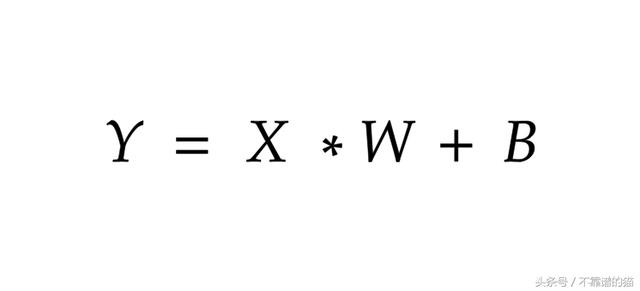
基本公式,用于乘以权重并为排列为列的特征添加偏差
对于权重:

用于确定W维数的广义方程
对于偏差:

广义方程决定B的维数
其中n = 1,2,3 ……,输出层数
排列为行的特征:
基本方程式:

基本公式,用于乘以权重并为排列为行的特征添加偏差
对于权重:

用于确定W维数的广义方程
对于偏差:

广义方程决定B的维数
其中n = 1,2,3 ……,输出层数。
我们可以看到“特征排列为行”的W&B维度只是“以列排列的特征”的W&B的转置。
那么,使用哪一个?功能排列为列或行?
使用按列排列的特征非常有意义。
因为,默认情况下,W是权重向量,在数学中,向量被视为列,而不是行。
要正确地将两者相乘并在正确的特征中使用正确的权重,您必须使用X * W + B :
通过X * W将每个特征乘以其相应的权重并添加B,您可以在每个预测中添加偏差项。
这就是像Keras这样的框架使用这种表示法的原因。因此,我们被迫遵循排列为输入列的特征。如果我们使用低级TensorFlow,那么我们可以使用我们想要的符号,因为我们执行计算并明确定义权重和偏差。
转载请注明:徐自远的乱七八糟小站 » 深度学习:所有矩阵尺寸和计算的深层指南!



