本文主要从M3和M4的MPU、DSP能力、debug调试和电源管理4个方面说明两者的区别。
1.内存保护单元MPU
与Cortex – M3的相同,MPU是一个Cortex – M4中用于内存保护的可选组件。处理器支持标准ARMv7内存保护系统结构模型。您可以使用在MPU执行 特权/访问 规则,或者独立的进程。这个MPU提供全面支持:
保护区
重叠保护区域,提升区域优先级(7 =最高优先级,0 =最低优先级)
访问权限
将存储器属性输出至系统
2 .DSP能力
下图展示了处理器运行在相同的速度下Cortex – M3和Cortex – M4在数字信号处理能力方面的相对性能比较。
在下面的数字,Y轴代表执行给出的计算用的相对的周期数。 因此,循环数越小,性能越好。以Cortex – M3作为参考,Cortex – M4的性能计算,性能比大概为其周期计数的倒数。举例说明,PID功能,Cortex – M4的周期数是与Cortex – M3的约0.7倍,因此相对性能是1/0.7,即1.4倍。
Cortex – M系列16位循环计数功能
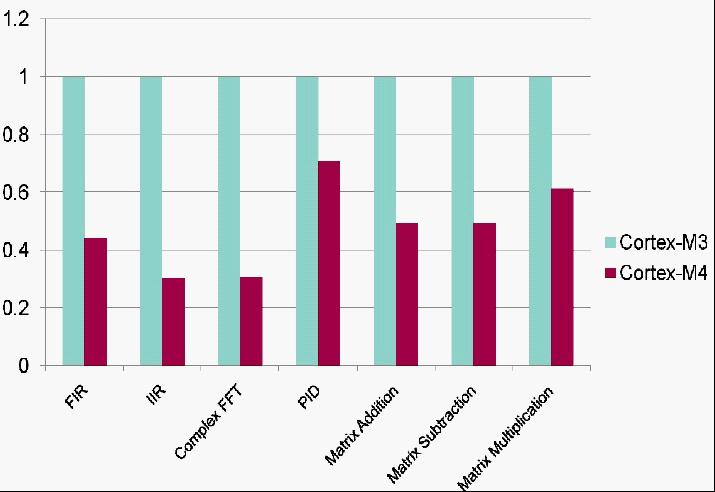
Cortex – M系列32位循环计数功能
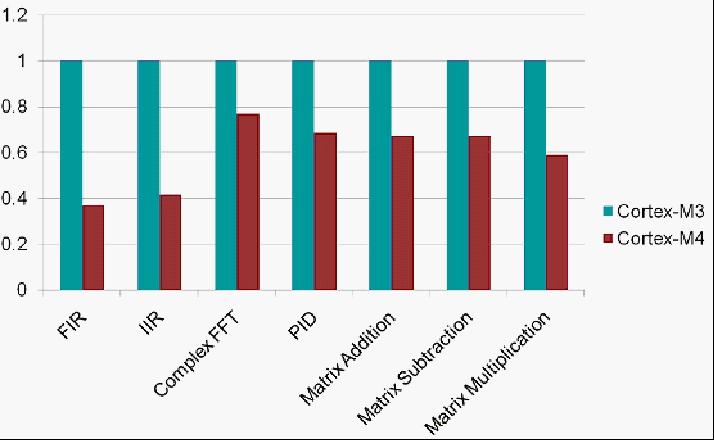
这很清楚的表明,Cortex – M4在数字信号处理方面对比Cortex – M3的16位或32位操作有着很大的优势。
Cortex-M4执行的所有的DSP指令集都可以在一个周期完成,Cortex – M3需要多个指令和多个周期才能完成的等效功能。即使是PID算法——通用DSP运算中最耗费资源的工作,Cortex – M4也能提供了一个1.4倍的性能得改善 。另一个例子,MP3解码在Cortex-M3需要20-25Mhz,而在Cortex-M4只需要10-12MHz。
1). 32位乘法累加(MAC)
32位乘法累加(MAC)包括新的指令集和针对Cortex – M4硬件执行单元的优化它是能够在单周期内完成一个 32 × 32 + 64 – > 64 的操作 或 两个16 × 16 的操作。如下表列出了这个单元的计算能力。
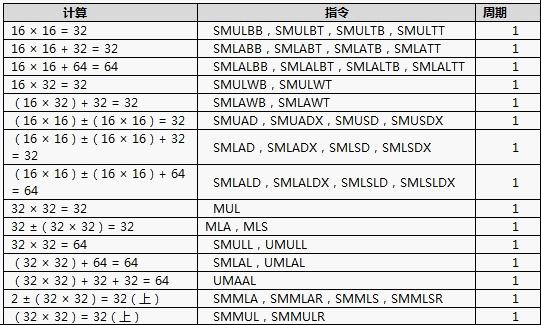
2). SIMD
Cortex – M4支持SIMD指令集,这在上一代的Cortex – M系列是不可用的。上述表中的指令,有的属于SIMD指令。与硬件乘法器一起工作(MAC),使所有这些指令都能在单个周期内执行。受益于SIMD指令的支持,Cortex – M4处理器是能在单周期完成高达32 × 32 + 64 – >64的运算,为其他任务释放处理器的带宽, 而不是被乘法和加法消耗运算资源。考虑以下复杂的算术运算,其中两个16 × 16乘法加上一个32位加法,被编译成由一个单一指令执行:SUM = SUM +(A* C)+(B *D)

3).FPU
FPU是Cortex – M4浮点运算的可选单元。因此它是一个专用于浮点任务的单元。这个单元通过硬件提升性能,能处理单精度浮点运算,并与IEEE 754标准 兼容。这完成了ARMv7 – M架构单精度变量的浮点扩展。FPU扩展了寄存器的程序模型与包含32个单精度寄存器的寄存器文件。这些可以被看作是:
-
16个64位双字寄存器,D0 – D15
-
32个32位单字寄存器,S0 – S31 该FPU提供了三种模式运作,以适应各种应用
-
全兼容模式(在全兼容模式,FPU处理所有的操作都遵循IEEE754的硬件标准)
-
Flush-to-zero 冲洗到零模式(设置FZ位浮点状态和控制寄存器FPSCR [24]到flush-to-zero 模式。在此模式下,FPU 在运算中将所有不正常的输入操作数的算术CDP操作当做0.除了当从零操作数的结果是合适的情况。VABS,VNEG,VMOV 不会被当做算术CDP的运算,而且不受flush-to-zero 模式影响。结果是微小的,就像在IEEE 754 标准的描述的那样,在目标精度增加的幅度小于四舍五入后最低正常值,被零取代。IDC的标志位,FPSCR [7],表示当输入Flush时变化。UFC标志位,FPSCR [3],表示当Flush结束时变化)
-
默认的NaN模式(DN位的设置,FPSCR [25],会进入NaN的默认模式。在这种模式下,如对任何算术数据处理操作的结果,涉及一个输入NaN,或产生一个NaN结果,会返回默认的NaN。仅当VABS,VNEG,VMOV运算时,分数位增加保持。所有其他的CDP运算会忽略所有输入NaN的小数位的信息)
下表显示的是FPU指令集
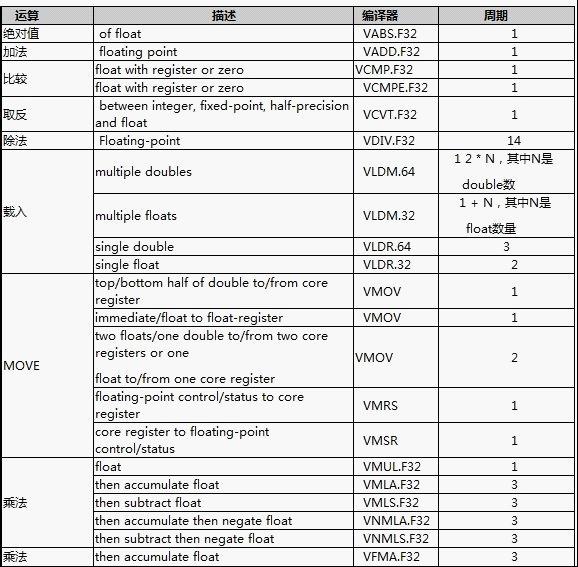

3.debug调试
与Cortex – M3的相同, Cortex – M4的设备是通过标准JTAG或串行线调试连接器调试。要连接到主机的接口,一个简单,标准化外部连接器是必要的。
4. 电源
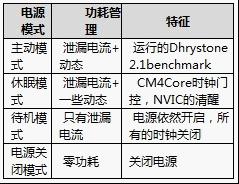
1).电源管理
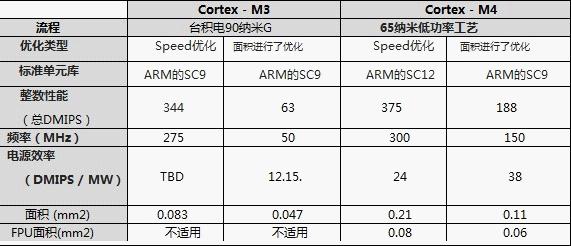
2).功耗比较
从图所示,很明显在功率效率方面Cortex – M4的性能大大优于表Cortex – M3。
转载请注明:徐自远的乱七八糟小站 » Cortex – M3与Cortex – M4对比