Word 神器 python-docx
Word 神器 python-docx-今日头条
前两天有个朋友向我求助,她在写毕业论文时,不小心将论文里的中文双引号替换为英文的了,各种原因导致无法回退,8万多字的论文,眼看就要交了,该怎么办?
首先想到 word 自身的替换功能,倒是能查到,但是没法动态替换,即只替换两边引号,而不换中间内容;
另外一种方案是,即用 VBA,通过编程来替换,虽说做过几个项目,可好久不用,拾起费劲,再加上 VBA 中各种概念和用法,学习成本太高,放弃;
还有一种方案,即用 Python 操作 word,首先对 Python 更熟悉,另外一定有别人造好的轮子。果然,没用多久找到了 python-docx Python 库,文档齐全,功能强大,用来解决替换问题不在话下。
开始之前,先简单了解下 python-docx
python-docx 是用于创建可修改 微软 Word 的一个 python 库,提供全套的 Word 操作,是最常用的 Word 工具
使用前,先了解几个概念:
- Document: 是一个 Word 文档 对象,不同于 VBA 中 Worksheet 的概念,Document 是独立的,打开不同的 Word 文档,就会有不同的 Document 对象,相互之间没有影响
- Paragraph: 是段落,一个 Word 文档由多个段落组成,当在文档中输入一个回车键,就会成为新的段落,输入 shift + 回车,不会分段
- Run 表示一个节段,每个段落由多个 节段 组成,一个段落中具有相同样式的连续文本,组成一个节段,所以一个 段落 对象有个 Run 列表
例如有一个 Word,内容是:
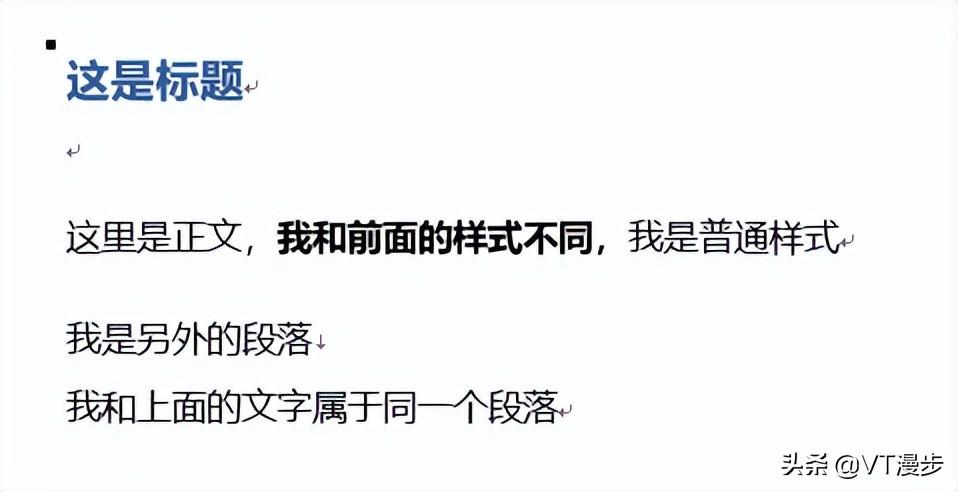
则 结构这样划分:

第二个 段落(paragraph),没有内容,所以 节段(run)为空
可以用 pip 来安装:
|
1 |
<span class="hljs-attribute">pip</span> install python-docx |
命令行中运行下面语句,如果没有报错,则说明安装成功
|
1 |
$ python -<span class="hljs-built_in">c</span> '<span class="hljs-keyword">import</span> docx' |
python-docx 安装后,测试一下:
|
1 |
<span class="hljs-keyword">from</span> docx <span class="hljs-keyword">import</span> Documentdocument = Document()paragraph = document.add_paragraph(<span class="hljs-string">'Lorem ipsum dolor sit amet.'</span>)prior_paragraph = paragraph.insert_paragraph_before(<span class="hljs-string">'Lorem ipsum'</span>)document.save(<span class="hljs-string">r"D:\test.docx"</span>) |
- 引入 Document 类
- 定义一个新文档对象 document
- 想文档中插入一个段落(paragraph)
- 再在这个段落(paragraph)前插入另一个段落
- 最后调用文档对象 document 的 save 保存文档
用 Word 打开保存的 test.docx 就可以看到:

了解了 python-docx 的基本概念,开始着手解决问题,大体思路是:
- 读取文档内容
- 查找 英文引号 之间的内容
- 将找到的内容的 英文引号 换成 中文引号,并将内容替换回去
- 完成处理后将文档另存
首先要解决的是如何找到 英文引号之间的内容?
例如文档内容有这么一段:
|
1 |
...对<span class="hljs-string">"基于需求的教育资源配置系统观"</span>的研究,尤其是对<span class="hljs-string">"以学习者为中心"</span>和从<span class="hljs-string">"个性化学习"</span>、<span class="hljs-string">"精准教学"</span>视角出发的教育资源配置问题提供了理论<span class="hljs-string">"支持\\以及"</span>方向指导... |
对于英文引号来说不区分前引号和后引号,怎么能保证配置到的不会是 “和从”、”、” 以及 “以学习者为中心”和从”个性化学习”、”精准教学” 或者 不会忽略两个引号出现在上下行的情况?
重温正则表达式,终于得到如下表达式:
|
1 |
<span class="hljs-string">'"(?:[^"])*"'</span> |
- ?::为了取消圆括号模式配置过程的缓存,即不需要遇到一个符合的就结束匹配
- [^”]:表示匹配的内容不能是 “,以避免贪婪匹配,即避免匹配成 从第一个 ” 开始一直到最后一个 “结束
- 整体的意思是 配置两个 ” 之间的内容,且内容中不包括 “
后来整理过程中,还发现另一种写法:
|
1 |
<span class="hljs-string">'".*?"'</span> |
不过 . 不能匹配换行符\n,坚持要用,需要使用 可选修饰符 re.S:
|
1 |
<span class="hljs-keyword">import</span> repattern = re.compile(<span class="hljs-string">'".*?"'</span>, re.S)re.findAll(pattern, text) |
- 引入 正则表达式模块 re
- re.S 为可选标识修饰符,使 . 匹配包括换行在内的所有字符
- 利用 findAll 查找所有匹配内容
关于 Python 正在表达式的更多用法参考文后参考链接
查找问题解决了,做替换就方便多了:
|
1 |
<span class="hljs-keyword">from</span> docx <span class="hljs-keyword">import</span> Documentimport redoc = Document(<span class="hljs-string">r"D:\论文.docx"</span>)restr = <span class="hljs-string">'"(?:[^"])*"'</span><span class="hljs-keyword">for</span> p <span class="hljs-keyword">in</span> doc.paragraphs: matchRet = re.findall(restr, p.text) <span class="hljs-keyword">for</span> r <span class="hljs-keyword">in</span> matchRet: p.text = p.text.replace(r, <span class="hljs-string">'“'</span> + r[<span class="hljs-number">1</span>:<span class="hljs-number">-1</span>] + <span class="hljs-string">'”'</span>)doc.save(<span class="hljs-string">r'D:\论文_修正.docx'</span>) |
- 引入 Document 类,和正则表达式模块
- 打开目标文档,字符串前的 r 表示取消字符串转义,即按原始字符产来解释
- 循环文档的 段落(paragraph),对每个段落,用正则表达式进行匹配
- 循环对于匹配到的结果,将前后引号,换成中文引号,并替换 段落(paragraph)的 text;其中 r[1:-1] 表示截取从第二个位置(第一个位置是 0)到倒数第二个位置截取字符串,刚好去掉前后引号
- 最后另存文档
注意:python-docx 保存文档时不会给出任何提示,会瞬间完成,所以另存是个稳妥的做法
完工,赶紧将替换好的文档发过去……
还没来得回味,她说:“非常感谢!那个~ 能不能再帮我生成个图表目录,这个必须要……”
好吧,能者多劳(神器在手),干就完了……
在上面小试牛刀中,介绍了插入段落(paragraph)的用法,下面在介绍一些 python-docx 的其他功能
为了简洁,下面例子中省略了 Document 类的引入和实例化代码,document 为 Document 的实例
默认情况下添加的标题是最高一级的,即一级标题,通过参数 level 设定,范围是 1 ~ 9,也有 0 级别,表示的是段落标题:
|
1 |
# 添加一级标题<span class="hljs-selector-tag">document</span><span class="hljs-selector-class">.add_heading</span>(<span class="hljs-string">'我是一级标题'</span>)<span class="hljs-selector-tag">decument</span><span class="hljs-selector-class">.add_heading</span>(<span class="hljs-string">'我是二级标题'</span>, level=<span class="hljs-number">2</span>)<span class="hljs-selector-tag">decument</span><span class="hljs-selector-class">.add_heading</span>(<span class="hljs-string">'我是段落标题'</span>, level=<span class="hljs-number">0</span>) |
如果一个段落不满一页,需要分页时,可以插入一个分页符,直接调用会将分页符插入到最后一个段落之后:
|
1 |
# 文档最后插入分页<span class="hljs-built_in">document</span>.add_page_break()# 特定段落分页<span class="hljs-keyword">from</span> docx.enum.text <span class="hljs-keyword">import</span> WD_BREAKparagraph = <span class="hljs-built_in">document</span>.add_paragraph(<span class="hljs-string">"独占一页"</span>) # 添加一个段落paragraph.runs[<span class="hljs-number">-1</span>].add_break(WD_BREAK.PAGE) # 在段落的最后一个节段后添加分页 |
Word 文档中经常会用到表格,python-docx 如何添加和操作表格呢?
|
1 |
# 添加一个 <span class="hljs-number">2</span>×<span class="hljs-number">2</span> 表格<span class="hljs-built_in">table</span> = document.add_table(rows=<span class="hljs-number">2</span>, cols=<span class="hljs-number">2</span>)# 获取第一行第二列单元格cell = <span class="hljs-built_in">table</span>.cell(<span class="hljs-number">0</span>, <span class="hljs-number">1</span>)# 设置单元格文本cell.text = <span class="hljs-string">'我是单元格文字'</span># 表格的行row = <span class="hljs-built_in">table</span>.rows[<span class="hljs-number">1</span>]row.cells[<span class="hljs-number">0</span>].text = <span class="hljs-string">'Foo bar to you.'</span>row.cells[<span class="hljs-number">1</span>].text = <span class="hljs-string">'And a hearty foo bar to you too sir!'</span># 增加行row = <span class="hljs-built_in">table</span>.add_row() |
更复杂点的例子:
|
1 |
# 表格数据items = ( (<span class="hljs-number">7</span>, <span class="hljs-string">'1024'</span>, <span class="hljs-string">'手机'</span>), (<span class="hljs-number">3</span>, <span class="hljs-string">'2042'</span>, <span class="hljs-string">'笔记本'</span>), (<span class="hljs-number">1</span>, <span class="hljs-string">'1288'</span>, <span class="hljs-string">'台式机'</span>),)# 添加一个表格<span class="hljs-built_in">table</span> = document.add_table(<span class="hljs-number">1</span>, <span class="hljs-number">3</span>)# 设置表格标题heading_cells = <span class="hljs-built_in">table</span>.rows[<span class="hljs-number">0</span>].cellsheading_cells[<span class="hljs-number">0</span>].text = <span class="hljs-string">'数量'</span>heading_cells[<span class="hljs-number">1</span>].text = <span class="hljs-string">'编码'</span>heading_cells[<span class="hljs-number">2</span>].text = <span class="hljs-string">'描述'</span># 将数据填入表格<span class="hljs-keyword">for</span> item <span class="hljs-keyword">in</span> items: cells = <span class="hljs-built_in">table</span>.add_row().cells cells[<span class="hljs-number">0</span>].text = str(item[<span class="hljs-number">0</span>]) cells[<span class="hljs-number">1</span>].text = item[<span class="hljs-number">1</span>] cells[<span class="hljs-number">2</span>].text = item[<span class="hljs-number">2</span>] |
添加图片,即,为 Word 里 菜单中 插入 > 图片 插入的功能,插入图片为原始大小:
|
1 |
<span class="hljs-built_in">document</span>.add_picture(<span class="hljs-string">'image-filename.png'</span>) |
插入时设置图片大小:
|
1 |
<span class="hljs-keyword">from</span> docx.shared <span class="hljs-keyword">import</span> Cm# 设置图片的跨度为 <span class="hljs-number">10</span> 厘米<span class="hljs-built_in">document</span>.add_picture(<span class="hljs-string">'image-filename.png'</span>, width=Cm(<span class="hljs-number">10</span>)) |
除了厘米,python-docx 还提供了 英寸(Inches),如设置 1英寸: Inches(1.0)
样式可以针对整体文档(document)、段落(paragraph)、节段(run),月具体,样式优先级越高
python-docx 样式功能配置多样,功能丰富,这里对段落样式和文字样式做简单介绍
段落样式包括:对齐、列表样式、行间距、缩进、背景色等,可以在添加段落时设定,也可以在添加之后设置:
|
1 |
# 添加一个段落,设置为无序列表样式<span class="hljs-built_in">document</span>.add_paragraph(<span class="hljs-string">'我是个无序列表段落'</span>, style=<span class="hljs-string">'List Bullet'</span>)# 添加段落后,通过 style 属性设置样式paragraph = <span class="hljs-built_in">document</span>.add_paragraph(<span class="hljs-string">'我也是个无序列表段落'</span>)paragraph.style = <span class="hljs-string">'List Bullet'</span> |
在前面 python-docx 文档结构图可以看到,段落中,不同样式的内容,被划分成多个 节段(Run),文字样式是通过 节段(Run)来设置的
|
1 |
<span class="hljs-attr">paragraph</span> = document.add_paragraph(<span class="hljs-string">'添加一个段落'</span>) |
设置字体稍微复杂些,例如设置一段文字为 宋体:
|
1 |
<span class="hljs-attr">paragraph</span> = document.add_paragraph(<span class="hljs-string">'我的字体是 宋体'</span>)run = paragraph.runs[<span class="hljs-number">0</span>]run.font.name = <span class="hljs-string">'宋体'</span>run._element.rPr.rFonts.set(qn(<span class="hljs-string">'w:eastAsia'</span>), <span class="hljs-string">'宋体'</span>) |
python-docx 是个功能强大的 Word 库,能实现几乎所有在 Word 中操作,今天通过一个实例,介绍了 python-docx 的一些基本用法,限于篇幅,没法展开讨论更多内容,如果有兴趣可以深入研究,说不定可以让 Word 像 Markdown 一样简单。
Word 神器 python-docxhttps://m.toutiao.com/article/7120526960677405223/?app=news_article×tamp=1658185541&use_new_style=1&req_id=2022071907054001013312615815232069&group_id=7120526960677405223&tt_from=android_share&utm_medium=toutiao_android&utm_campaign=client_share&share_token=ecf6ca94-7911-42f1-b727-642d93633b24
转载请注明:徐自远的乱七八糟小站 » Word 神器 python-docx