如何选择最佳机器学习算法?
讲完随机森林算法之后,小冰开口问道 :“咖哥,上面的这几种经典算法,你讲得简明扼要,感觉都挺好。不过,现在的问题来了,算法一多,我反而不知道如何选择了。你能不能给我们说说,什么样的算法适合解决什么样的问题?”
咖哥回答 :“这很值得说一说。没有任何一种机器学习算法,能够做到针对任何数据集都是最佳的。通常,拿到一个具体的数据集后,会根据一系列的考量因素进行评估。这些因素包括 :要解决的问题的性质、数据集大小、数据集特征、有无标签等。有了这些信息后,再来寻找适宜的算法。”
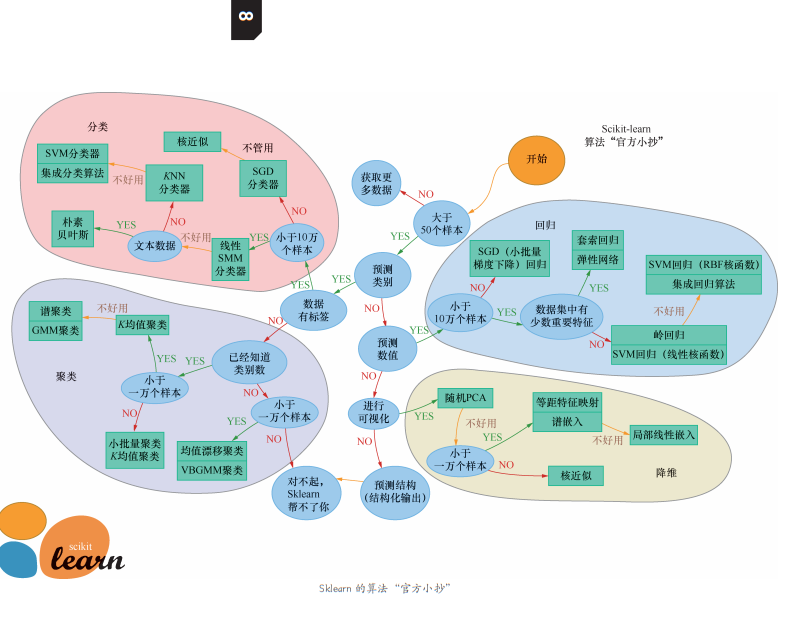
让我们从下页这张 Sklearn 的算法“官方小抄”图入手来简单说说机器学习算法的选择。顺着这张图过一遍各种机器学习算法,也是一个令我们将所学知识融会贯通的过程。
在开始选择 Sklearn 算法之前,先额外加一个 IF 语句 :
IF 机器学习问题 = 感知类问题 ( 也就是图像、语言、文本等非结构化问题 )THEN 深度学习算法 ( 例如使用 Keras 深度学习库 )
因为适合深度学习的问题通常不用 Sklearn 库来解决,而对于浅层的机器学习问题,Sklearn就可以大显身手了。Sklearn 库中的算法选择流程如下 :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
<span class="hljs-attr">IF</span> <span class="hljs-string">数据量小于 50 个</span> <span class="hljs-meta">数据样本太少了</span> <span class="hljs-string">, 先获取更多数据</span> <span class="hljs-attr">ELSE</span> <span class="hljs-string">数据量大于 50 个</span> <span class="hljs-attr">IF</span> <span class="hljs-string">是分类问题</span> <span class="hljs-attr">IF</span> <span class="hljs-string">数据有标签</span> <span class="hljs-attr">IF</span> <span class="hljs-string">数据量小于 10 万个</span> <span class="hljs-meta">选择</span> <span class="hljs-string">SGD 分类器</span> <span class="hljs-attr">ELSE</span> <span class="hljs-string">数据量大于 10 万个</span> <span class="hljs-meta">先尝试线性</span> <span class="hljs-string">SVM 分类器 , 如果不好用 , 再继续尝试其他算法</span> <span class="hljs-attr">IF</span> <span class="hljs-string">特征为文本数据</span> <span class="hljs-attr">选择朴素贝叶斯</span> <span class="hljs-attr">ELSE</span> <span class="hljs-meta">先尝试</span> <span class="hljs-string">KNN 分类器 , 如果不好用 , 再尝试 SVM 分类器加集成分类算法 ( 参见第 9 课内容 )</span> <span class="hljs-attr">ELSE</span> <span class="hljs-string">数据没有标签</span> <span class="hljs-meta">选择各种聚类算法</span> <span class="hljs-string">( 参见第 10 课内容 )</span> <span class="hljs-attr">ELSE</span> <span class="hljs-string">不是分类问题</span> <span class="hljs-attr">IF</span> <span class="hljs-string">需要预测数值 , 就是回归问题</span> <span class="hljs-attr">IF</span> <span class="hljs-string">数据量大于 10 万个</span> <span class="hljs-meta">选择</span> <span class="hljs-string">SGD 回归</span> <span class="hljs-attr">ELSE</span> <span class="hljs-string">数据量小于 10 万个</span> <span class="hljs-meta">根据数据集特征的特点</span> <span class="hljs-string">, 有套索回归和岭回归、集成回归算法、SVM 回归等几种选择</span> <span class="hljs-attr">ELSE</span> <span class="hljs-string">进行可视化 ,</span> <span class="hljs-meta">则考虑几种降维算法</span> <span class="hljs-string">( 参见第 10 课内容 )</span> <span class="hljs-attr">ELSE</span> <span class="hljs-string">预测结构</span> <span class="hljs-meta">对不起</span> <span class="hljs-string">, Sklearn 帮不了你</span> |
选择机器学习算法的思路大致如此。此外,经验和直觉在机器学习领域的重要性当然是不言而喻。其实,不光机器学习,经验和直觉无论在什么领域也都是关键。当然,选取多种算法去解决同一个问题,然后将各种算法的效率进行比较,也不失为一个好的方案。
刚才,我们已经应用了好几个机器学习算法处理同一个数据集。再加上以前讲过的逻辑回归,现在就可以对各种算法的性能进行一个横向比较。下面是用逻辑回归算法解决心脏病的预测问题的示例代码。
|
1 2 3 4 5 6 7 8 9 |
<span class="hljs-keyword">from</span> sklearn.linear_model <span class="hljs-keyword">import</span> LogisticRegression lr = LogisticRegression() lr.fifit(X_train, y_train) y_pred = lr.predict(X_test) lr_acc = lr.score(X_test, y_test)*<span class="hljs-number">100</span> lr_f1 = f1_score(y_test, y_pred)*<span class="hljs-number">100</span> <span class="hljs-built_in">print</span>(<span class="hljs-string">" 逻辑回归预测准确率 :{:.2f}%"</span>.format(lr_acc)) <span class="hljs-built_in">print</span>(<span class="hljs-string">" 逻辑回归预测 F1 分数 : {:.2f}%"</span>.format(lr_f1)) <span class="hljs-built_in">print</span>(<span class="hljs-string">' 逻辑回归混淆矩阵 :\n'</span>, confusion_matrix(y_test, y_pred)) |
下面就输出所有这些算法针对心脏病预测的准确率直方图 :
|
1 2 3 4 5 6 7 8 9 10 11 12 |
methods = [<span class="hljs-string">"Logistic Regression"</span>, <span class="hljs-string">"KNN"</span>, <span class="hljs-string">"SVM"</span>, <span class="hljs-string">"Naive Bayes"</span>, <span class="hljs-string">"Decision Tree"</span>, <span class="hljs-string">"Random Forest"</span>] accuracy = [lr_acc, KNN_acc, svm_acc, nb_acc, dtc_acc, rf_acc] colors = [<span class="hljs-string">"orange"</span>, <span class="hljs-string">"red"</span>, <span class="hljs-string">"purple"</span>, <span class="hljs-string">"magenta"</span>, <span class="hljs-string">"green"</span>, <span class="hljs-string">"blue"</span>] sns.set_style(<span class="hljs-string">"whitegrid"</span>) plt.fifigure(fifigsize=(16, 5)) plt.yticks(np.arange(0, 100, 10)) plt.ylabel(<span class="hljs-string">"Accuracy %"</span>) plt.xlabel(<span class="hljs-string">"Algorithms"</span>) sns.barplot(x=methods, y=accuracy, palette=colors) plt.grid(b=None) plt.show() |
各种算法的准确率比较如下图所示。
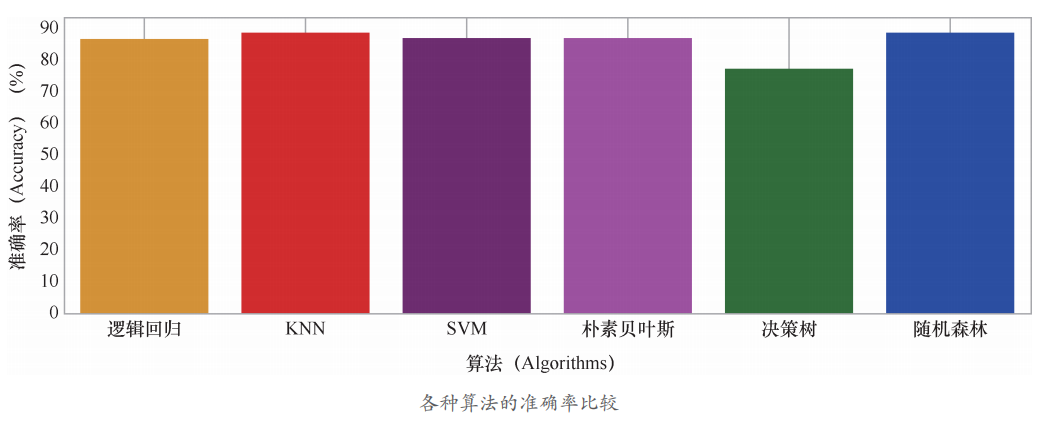
从结果上看,KNN 和随机森林等算法对于这个问题来说是较好的算法。

再绘制出各种算法的混淆矩阵 :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
<span class="hljs-keyword">from</span> sklearn.metrics <span class="hljs-keyword">import</span> confusion_matrix y_pred_lr = lr.predict(X_test) KNN3 = KNeighborsClassififier(n_neighbors = <span class="hljs-number">3</span>) KNN3.fifit(X_train, y_train) y_pred_KNN = KNN3.predict(X_test) y_pred_svm = svm.predict(X_test) y_pred_nb = nb.predict(X_test) y_pred_dtc = dtc.predict(X_test) y_pred_rf = rf.predict(X_test) cm_lr = confusion_matrix(y_test, y_pred_lr) cm_KNN = confusion_matrix(y_test, y_pred_KNN) cm_svm = confusion_matrix(y_test, y_pred_svm) cm_nb = confusion_matrix(y_test, y_pred_nb) cm_dtc = confusion_matrix(y_test, y_pred_dtc) cm_rf = confusion_matrix(y_test, y_pred_rf) plt.figure(figsize=(<span class="hljs-number">24</span>, <span class="hljs-number">12</span>)) plt.suptitle(<span class="hljs-string">"Confusion Matrixes"</span>, fontsize=<span class="hljs-number">24</span>) plt.subplots_adjust(wspace = <span class="hljs-number">0.4</span>, hspace= <span class="hljs-number">0.4</span>) plt.subplot(<span class="hljs-number">2</span>, <span class="hljs-number">3</span>, <span class="hljs-number">1</span>) plt.title(<span class="hljs-string">"Logistic Regression Confusion Matrix"</span>) sns.heatmap(cm_lr, annot=<span class="hljs-literal">True</span>, cmap=<span class="hljs-string">"Blues"</span>, fmt=<span class="hljs-string">"d"</span>, cbar=<span class="hljs-literal">False</span>) plt.subplot(<span class="hljs-number">2</span>, <span class="hljs-number">3</span>, <span class="hljs-number">2</span>) plt.title(<span class="hljs-string">"K Nearest Neighbors Confusion Matrix"</span>) sns.heatmap(cm_KNN, annot=<span class="hljs-literal">True</span>, cmap=<span class="hljs-string">"Blues"</span>, fmt=<span class="hljs-string">"d"</span>, cbar=<span class="hljs-literal">False</span>) plt.subplot(<span class="hljs-number">2</span>, <span class="hljs-number">3</span>, <span class="hljs-number">3</span>) plt.title(<span class="hljs-string">"Support Vector Machine Confusion Matrix"</span>) sns.heatmap(cm_svm, annot=<span class="hljs-literal">True</span>, cmap=<span class="hljs-string">"Blues"</span>, fmt=<span class="hljs-string">"d"</span>, cbar=<span class="hljs-literal">False</span>) plt.subplot(<span class="hljs-number">2</span>, <span class="hljs-number">3</span>, <span class="hljs-number">4</span>) plt.title(<span class="hljs-string">"Naive Bayes Confusion Matrix"</span>) sns.heatmap(cm_nb, annot=<span class="hljs-literal">True</span>, cmap=<span class="hljs-string">"Blues"</span>, fmt=<span class="hljs-string">"d"</span>, cbar=<span class="hljs-literal">False</span>) plt.subplot(<span class="hljs-number">2</span>, <span class="hljs-number">3</span>, <span class="hljs-number">5</span>) plt.title(<span class="hljs-string">"Decision Tree Classifier Confusion Matrix"</span>) sns.heatmap(cm_dtc, annot=<span class="hljs-literal">True</span>, cmap=<span class="hljs-string">"Blues"</span>, fmt=<span class="hljs-string">"d"</span>, cbar=<span class="hljs-literal">False</span>) plt.subplot(<span class="hljs-number">2</span>, <span class="hljs-number">3</span>, <span class="hljs-number">6</span>) plt.title(<span class="hljs-string">"Random Forest Confusion Matrix"</span>) sns.heatmap(cm_rf, annot=<span class="hljs-literal">True</span>, cmap=<span class="hljs-string">"Blues"</span>, fmt=<span class="hljs-string">"d"</span>, cbar=<span class="hljs-literal">False</span>) plt.show() |
各种算法的混淆矩阵如下图所示。
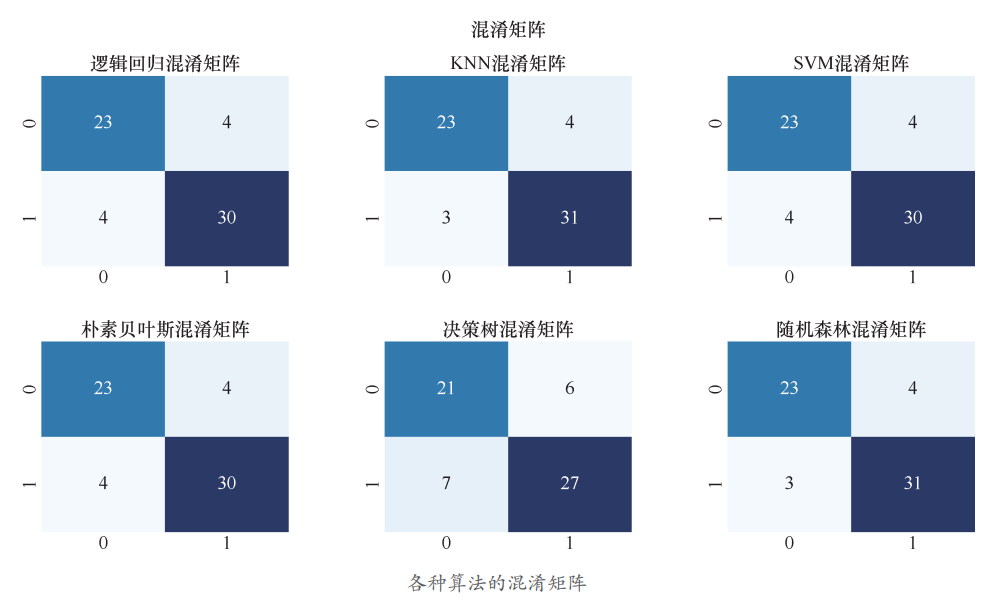
从图中可以看出,KNN 和随机森林这两种算法中“假负”的数目为 3,也就是说本来没有心脏病,却判定为有心脏病的客户有 3 人 ;而“假正”的数目为 4,也就是说本来有心脏病,判定为没有心脏病的客户有 4 人。
本文摘自《零基础学机器学习》

机器学习,就是在已知数据集的基础上,通过反复的计算,选择最贴切的函数(function)去描述数据集中自变量x1, x 2, x 3, …, xn 和因变量y 之间的关系。如果机器通过所谓的训练(training)找到了一个函数,对于已有的 1000 组钻石数据,它都能够根据钻石的各种特征,大致推断出其价格。那么,再给另一批同类钻石的大小、重量、颜色、密度等数据,就很有希望用同样的函数(模型)推断出这另一批钻石的价格。此时,已有的 1000 组有价格的钻石数据,就叫作训练数据集(trainingdataset)。另一批钻石数据,就叫作测试数据集(test dataset)。
因此,正如下图所示,通过机器学习模型不仅可以推测孩子身高和钻石价格,还可以实现影片票房预测、人脸识别、根据当前场景控制游戏角色的动作等诸多功能。

机器学习就是从数据中发现关系,归纳成函数,以实现从 A 到 B 的推断
其实所谓机器学习,的确是一个统计建模的过程。但是当特征数目和数据量大到百万、千万,甚至上亿时,原本属于数学家的工作当然只能通过机器来完成喽。而且,机器学习没有抽样的习惯,对于机器来说,数据是多多益善,有多少就用多少。
下面的图展示了机器从数据中训练模型的过程,而人类的学习,是从经验中归纳规律,两者何其相似!越是与人类学习方式相似的 AI,才是越高级的 AI !这种从已知到未知的学习能力是机器学习和以前的符号式 AI 最本质的区别。

机器 :从数据中学习 ;人类 :从经验中学习。两者何其相似
机器学习的另外一个特质是从错误中学习,这一点也与人类的学习方式非常相似。你们看一个婴儿,他总想吞掉他能够拿到的任何东西,包括硬币和纽扣,但是真的吃到嘴里,会发生不好的结果。慢慢地,他就从这些错误经验中学习到什么能吃,什么不能吃。这是通过试错来积累经验。机器学习的训练、建模的过程和人类的这个试错式学习过程有些相似。机器找到一个函数去拟合(fit)它要解决的问题,如果错误比较严重,它就放弃,再找到一个函数,
如果错误还是比较严重,就再找,一直到找到相对最为合适的函数为止,此时犯错误的概率最小。这个寻找的过程,绝大多数情况不是在人类的“指导”下进行的,而是机器通过机器学习算法自己摸索出来的。
因此,机器学习是突破传统的学习范式,它与专家系统(属于符号式 AI)中的规则定义不同。如下图所示,它不是由人类把已知的规则定义好之后输入给机器的,而是机器从已知数据中不断试错之后,归纳出来规则。
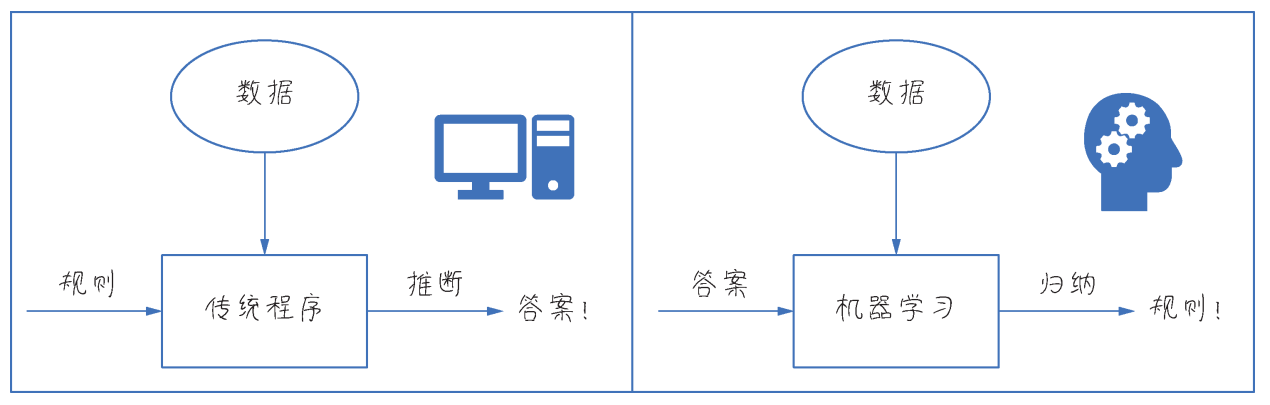
机器学习是突破传统的学习范式,是从数据中发现规则,而不是接受人类为它设定的规则
如果你想学习机器学习,以上内容您很感兴趣。那么推荐您阅读《零基础学机器学习》

本书的目标,是让非机器学习领域甚至非计算机专业出身但有学习需求的人,轻松地掌握机器学习的基本知识,从而拥有相关的实战能力。
本书通过AI“小白”小冰拜师程序员咖哥学习机器学习的对话展开,内容轻松,实战性强,主要包括机器学习快速上手路径、数学和Python 基础知识、机器学习基础算法(线性回归和逻辑回归)、深度神经网络、卷积神经网络、循环神经网络、经典算法、集成学习、无监督和半监督等非监督学习类型、强化学习实战等内容,以及相关实战案例。本书所有案例均通过Python及Scikit-learn 机器学习库和Keras 深度学习框架实现,同时还包含丰富的数据分析和数据可视化内容。
本书适合对AI 感兴趣的程序员、项目经理、在校大学生以及任何想以零基础学机器学习的人,用以入门机器学习领域,建立从理论到实战的知识通道。
如何选择最佳机器学习算法?https://m.toutiaocdn.com/i6920000377223954951/?app=news_article×tamp=1611367054&use_new_style=1&req_id=2021012309573401013107422311401ECF&group_id=6920000377223954951&tt_from=android_share&utm_medium=toutiao_android&utm_campaign=client_share&share_token=c4dac295-67e6-40aa-98b5-78741bc4479e
转载请注明:徐自远的乱七八糟小站 » 如何选择最佳机器学习算法?



