Python制作专属有声小说(调用百度语音合成接口)
嗨学python2020-05-21 13:52:03
前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者:merlin&

这一次的目标是使用百度云的人工智能接口,实现文字转语音的实时转换,将小说文字转换成语音朗读出来。
百度云接口调用
百度的这个接口对于我们普通用户非常友好,他的很多功能都是免费的,而且我们每天可以免费调用这个接口五千次,非常适合我们玩转这些功能。
注册百度云账号
首先打开百度云语音合成模块接口地址
打开网址后点击《立即使用》选项,然后会出现登录的选项界面。如果没有账号,需要先注册一个百度云账号,注册方法非常简单,我就不过多赘述了
登录账号之后,会自动进入控制台界面,因为现在我们还没有创建应用,这里显示的就是0个
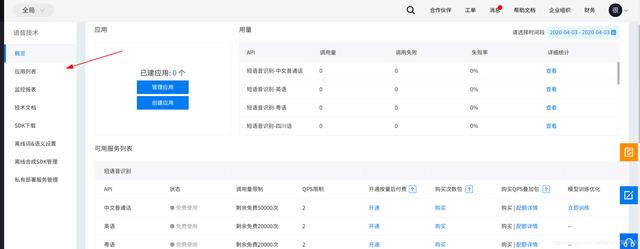
点击应用列表,创建应用,弹出的创建应用配置项,其中的内容随意填写即可

填写完成,点击立即创建,返回到应用列表,此时可发现我的应用下多出了一个应用项目

使用接口
- 安装模块
在python环境下使用该接口必须要安装模块
|
1 2 |
pip install baidu-aip |
安装成功可见如下提示

- 生成一段语音
通过查看百度语音合成的技术文档,可以发现如下的几个参数:

将这些参数传递到技术文档所给的框架中,就可以生成一段语音:
|
1 |
from aip import AipSpeech |
app_id = ‘你的Appid’
|
1 2 3 |
api_key = '你的API key' secret_key = '你的 screct key' |
client = AipSpeech(app_id,api_key,secret_key)
result = client.synthesis(‘人生得意须尽欢,莫使金樽空对月’,’zh’,’1′,
|
1 2 3 4 5 6 |
{"vol": 9, "spd": 4, "pit": 9, "per": 3, }) |
with open(“audio.mp3″,”wb”) as f:
|
1 2 3 |
f.write(result) |
运行完这一段代码之后,就会在当前文件夹下生成一个audio.mp3的音频文件,打开之后就是可以听到朗诵的诗句
- 小说文字转语音
在阅读了技术文档之后,可知这个模块最大的限制就是一次转换的语音不能超过1024字节(大约是512个汉字),所以我们要进行的第一步操作就是将一篇小说切割成若干个五百字数的文本文档。首先我先找到一篇小说,将它复制到文档中,命名为read.txt 接下来我准备使用代码来切割小说内容,一段的字数为500字
先将小说的内容提取出来,每隔1000个字节(500字)加上“—”的符号作为切割标志
|
1 2 |
with open('read.txt','r') as a: text = a.readlines() |
for cut in text:
|
1 2 3 4 5 6 7 8 9 |
#以1000个字节的长度进行分割 text_cut = re.findall('.{1000}', cut) text_cut.append(cut[(len(text_cut) * 1000):]) #在分割后的字符串中间插入"---" text_final = '---'.join(text_cut) #计算文本中有多少个"---"标志 times = text_final.count('---') |
之后将文本以—为标志进行分割,并分别将内容赋值到name变量中。正常来说,列表的起始位为第0位,但是为了满足我们的阅读习惯,所以将这些文本从1开始计数
|
1 2 3 |
for n in range(0,times+1): name = text_final.split('---')[n] |
最后一步,将提取出来的文本内容传入api接口,输出语音文件
完整代码
(将三个参数替换成之前申请的内容)
|
1 2 3 4 5 6 7 8 |
import re from aip import AipSpeech =========================== ||python学习群:695185429 || =========================== app_id = 'id' api_key = 'APIkey' secret_key = 'screctkey' |
client = AipSpeech(app_id,api_key,secret_key)
with open(‘read.txt’,’r’) as a:
|
1 2 |
text = a.readlines() |
for cut in text:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
#以1000个字节的长度进行分割 text_cut = re.findall('.{1000}', cut) text_cut.append(cut[(len(text_cut) * 1000):]) #在分割后的字符串中间插入"---" text_final = '---'.join(text_cut) #计算文本中有多少个"---"标志 times = text_final.count('---') for n in range(0,times+1): name = text_final.split('---')[n] result = client.synthesis(name, 'zh', '1', {"vol": 9, "spd": 4, "pit": 9, "per": 3, }) |
with open(‘test/’ + str(n + 1) + ‘.mp3’, “wb”) as d:
|
1 2 3 4 |
print('正在生成第' + str(n + 1) + '段语音......') d.write(result) |
实现结果:
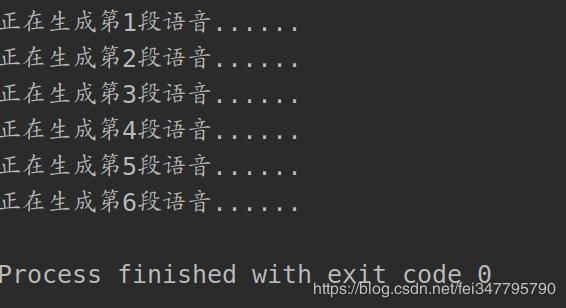
打开test文件夹,点击mp3文件就可以开始听小说了

有一说一,这个百度人工智能所装换的语音非常像有个人在你旁边给你读书,体验感远超pyttsx3模块,非常nice!
百度的人工智能接口还有非常多好用的功能,例如人脸识别、语音转文字、人脸对比…感兴趣的同学可以自己去探索一下


Python制作专属有声小说(调用百度语音合成接口)https://m.toutiaocdn.com/i6829171187168313868/?app=news_article×tamp=1590098834&use_new_style=0&req_id=2020052206071401001407020019B6EC87&group_id=6829171187168313868&tt_from=android_share&utm_medium=toutiao_android&utm_campaign=client_share
转载请注明:徐自远的乱七八糟小站 » Python制作专属有声小说(调用百度语音合成接口)



