边缘AI硬件谁更胜一筹?测评:Google Coral USB加速器与Intel NCS 2

随着人工智能(AI)和机器学习(ML)逐渐从科幻小说中走向现实生活,我们现在需要一种快速便捷的方式来对这种类型的系统进行原型设计。尽管台式计算机也可以足以满足AI / ML的运行要求,甚至Raspberry Pi之类的单板计算机都能满足这些需求。但是,如果你只想要一个简单的插件设备让你的系统运行地更快、更强大,那该怎么办?
别担心,其实你有多种选择,包括 Google 旗下 Coral Edge TPU 系列硬件 USB Accelerator(Coral USB 加速器,下称CUA) 和 Intel 旗下的 Neural Compute Stick 2(神经计算棒 NCS2)。两个设备都是通过 USB 插入主机的计算设备。 NCS2 使用的是视觉处理单元(VPU),而 Coral USB Accelerator 使用张量处理单元(TPU),两者都是用于机器学习的专用处理设备。今天就来给大家测评比较一番:二者之间有什么区别?作为开发者的你,是选择 Coral 好还是 NCS2 呢?话不多说,请参见下文。
Coral USB Accelerator(Coral USB 加速器)
-ML 加速器:由 Google 设计的 Edge TPU ASIC(专用集成电路) 芯片。专为 TensorFlow Lite 模型提供高性能的 ML 推理(MobileNet V2 400 + fps,来自官方最新更新的数据)。
-支持 USB 3.1 端口和缆线(SuperSpeed,5GB / s传输速度)
-尺寸:30 x 65 x 8 mm
-官方价格:$ 74.99
Intel Neural Compute Stick 2 (英特尔神经计算棒2 )
-处理器:英特尔 Movidius Myriad X 视觉处理单元(VPU)
-USB 3.0 Type-A
-尺寸:72.5 x 27 x 14mm
-官方价格:$ 87.99

一、处理器与加速性能对比
和比较传统计算机 CPU 的方式不同,比较每个处理器/加速器的细节更加细微,主要取决于你打算如何使用它们。尽管输出格式略有不同(每次推理时间与每秒帧数),但是我们仍然可以将这两种设备进行一些总体性能模式的对比。
在评估用于实时部署的 AI 模型和硬件平台时,首先要看的是——它们的速度如何。在计算机视觉任务中,基准通常以每秒帧数(FPS)进行测量。较高的数字表示更好的性能,对于实时视频流,至少需要大约 10 fps才能使视频显得流畅。
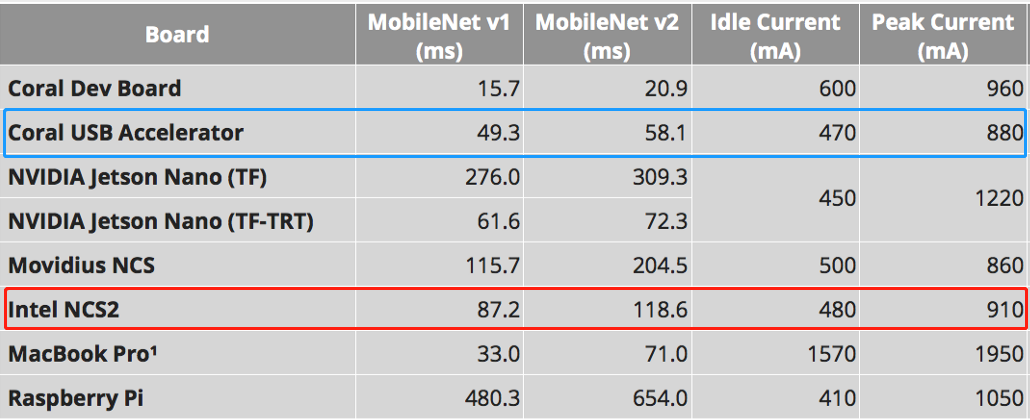
运行性能:首先,将 CUA 添加到台式机 CPU 时,可将性能提高大约10倍,运行性能较为不错。(根据选择的CPU型号不同,10倍性能略有上下浮动)NCS2与较旧的Atom处理器“合作”,可将处理速度提高近7倍。但是,与更强大的处理器搭配使用时,NCS2 呈现的结果却并不令人惊喜。
NCS2 理论上可以以 4 TOPS的速度执行推理。奇怪的是,CUA 也拥有完全相同的费率,虽然两者都使用不同的操作来执行 ML。此外,英特尔声称 NCS2 的性能是初代神经计算棒的 8 倍。(如果你乐意的话,你可以选择 NCS2,而非初代神经计算棒,虽然价格较低。)
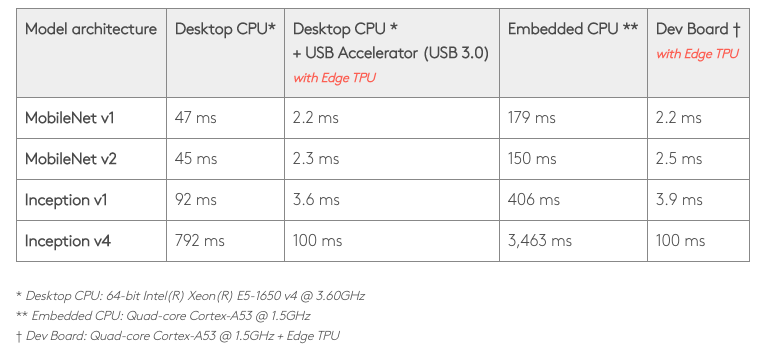
官方benchmark评测
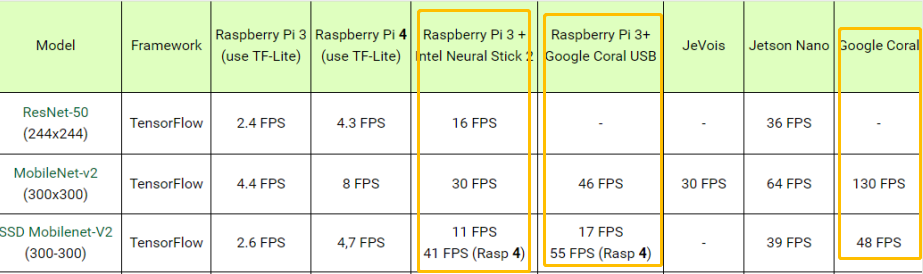
NCS2 可以使用 MobileNet-v2 运行 30 FPS 分类模型,这一点还不错。但是,以11 FPS的速度进行对象检测就有点困难了。大约 10 FPS 的帧速率可能不足以进行实时对象跟踪,特别是对于高速运动,并且可能会丢失许多对象,并且开发者需要非常好的跟踪算法来弥补这个“漏洞”。(当然,官方给出的基准测试结果并不完全可信。通常,这些公司会将其手动优化的软件与竞争对手的开箱即用模型进行比较。)
用户实操评测
功率消耗:NCS2 的功耗较低。就 CUA 而言,官方确实列出了每个TOPS所需0.5瓦。用户还可以根据需要将CUA设置为默认速度或最大(默认值的2倍)。
值得注意的是,Google 的官方文档确实明确提醒:设备以最大速度运行时的功率传输以及最高环境温度,可能会烫伤你的皮肤。所以个人认为,除非你确实需要额外的处理能力,否则最好以正常模式运行它。
同样重要的是,请记住,Python并非是让设备获得优秀性能的首选。这两种设备都支持C ++ API,这也是我在测试中让设备获得最佳性能的“窍门。
二、软件支持
NCS2 可以与 Ubuntu,CentOS,Windows 10 等其他操作系统一起使用。它可以通过开放神经网络转换来支持 TensorFlow,Caffe,ApacheMXNet,以及 PyTorch 和 PaddlePadle。
CUA 不支持 Windows,但可以在 Debian 6.0 或更高版本(或任何衍生版本,如Ubuntu 10.0+)下运行。值得一提的是,CUA 只能正式运行 TensorFlow Lite 模型。
三、尺寸、原型设计和其他细节对比
涵盖了软件支持、计算能力和功耗之后,二者在实际构建产品原型上的具体情况如何?
坦白说,这两种设备看起来都非常酷。 CUA 为略银白色纹格机身,具有部分透明的主体以及似乎是散热槽的地方。而NCS2 为光滑的蓝色设计,蓝色机身和集成的散热器看起来似乎更加时尚。


当然,外观只是次要的。重要的是,NCS2确实也会像CUA一样,运行时会变热。不过它的散热器设计,让你可以将其握在较凉的集成散热片上,而无需用手指在中间握住,这一点到是非常的巧妙。
NCS2的设计允许用户将多个计算棒一起使用以增强它的处理能力。你可以将它们整齐地排列在垂直的USB扩展坞中。同样的,一台主机也可以运行多个CUA,不过你可能需要找到另一种方式来保存每个CUA。值得一提的是,虽然二者都有相似的尺寸,但NCS2的厚度(14毫米)几乎是CUA的两倍。再加上它是通过USB插头(例如超大型拇指驱动器)插入的,而不是通过像CUA这样的柔性电缆插入的,这意味着在某些操作场景中,NCS2 会让你在处理空间问题上很艰难。你必须大量使用数据线缆和扩展坞,这一点是在你做出选择前,需要考虑到的事。

最后,NCS2 和CUA似乎都是为边缘计算应用程序设计的专属设备。如果你需要在Windows系统上运行,或者需要在 Tensorflow Lite 框架之外运行,那么 NCS2 具有较为明显的优势。就其本身而言,Coral USB Accelerator 的周边配套硬件,还有更加简单粗暴的开发板 Dev Board 和以 Coral Edge TPU 为核心设计的 PCI加速器、以及和开发板很像的 SoM 模块等等。如果你的需求是想将产品原型设计快速推向市场,那么Coral则是你的不二之选,它对开发者的吸引力更为强劲。


Coral USB Accelerator 开发环境要求:一台带有USB端口的Linux计算机;支持Debian 6.0或更高版本,或其衍生系统(如Ubuntu 10.0+);x86_64或具有ARMv8指令集的ARM64系统架构
所以,从上面这几点要求来看,Coral USB 加速器支持Raspberry Pi。但是,必须是Raspberry Pi 2/3 Model B/B+且运行Raspbian系统(或其它Debian衍生系统)。
在这一点上,两者之间的功能很是相似,如果要将AI / ML添加到Raspberry Pi或类似项目中,两种设备都可以正常工作。
许多预编译的网络模型让你可以轻松快速地获得更佳的结果。尽管如此,完全量化自己的网络仍然是一项高级任务。转换需要对网络以及操作方式有深入的了解。此外,当我从FP_32升级到FP_16,从FP_16升级到UINT时,关于准确性的损失也很大。有趣的是,Myriad 可处理其一半浮点,CUA 仅能处理8位浮点。这意味着Myriad可获得更高的准确性。

英特尔和 Google 显然采取了两种截然不同的“套路。 Google的优势在于产品可以帮助开发者们轻松构建prototype和推广Google Cloud Platform到edge-tpu的一整套解决方案。我个人就非常喜欢所有组件如何组合在一起工作。另一方面,英特尔提供了Openvino插件,开发人员可以使用它们来优化其网络,使其能够在各种硬件上运行。 OpenVINO当前支持英特尔CPU,GPU,FPGA和VPU。摆在英特尔面前的挑战是,这些”组合拳“始终难以利用每个组件的最优功能。
Google Coral USB Accelerator 能够在线训练网络模型,这对于进行迁移学习至关重要。显然,Google 相信他们的预训练网络和迁移学习为开发者们提供了高效的搭配。此外,英特尔 NCS2 具有三对内置的立体声深度硬件,在许多用例中(例如避障),它们是很有价值的。
应用场景:
英特尔 NCS2 还提供DNN的原型、验证和部署。对于无人驾驶和无人驾驶车辆以及物联网设备而言,低功耗是必不可少的。对于希望开发深度学习推理应用程序的人来说,NCS2 是最节能,成本最低的USB棒之一。
Google Coral 不仅仅是硬件。它轻松地结合了定制硬件,开放软件和先进的AI算法的功能并提供了高质量的AI解决方案。Coral在帮助工业发展领域有很多应用案例,包括预测性维护、异常检测、机器人技术、机器视觉和语音识别等。它对制造,医疗保健,零售,智能空间,内部监控和运输部门很有应用价值。

https://www.jianshu.com/p/7ec3c96fbc45
转载请注明:徐自远的乱七八糟小站 » 边缘AI硬件谁更胜一筹?测评:Google Coral USB加速器与Intel NCS 2



