雷锋网 AI 开发者按:过去,让计算机区分猫和狗被认为是最先进的研究;而现在,图像分类就像是机器学习(ML)的「Hello World」,可以使用 TensorFlow 在几行代码中实现上。在短短的几年内,机器学习领域已经取得了很大的进展,以至于现在,开发者们可以轻松地构建潜在「造福」或「致命」的应用程序。
因此,一位好奇的学者 Tikeswar Naik,通过简单的实验和我们讨论了这项技术的某一潜在滥用情况——使用 ML 来破解密码,希望通过这一介绍能够让更多人保持警惕,并找到减轻或防止滥用的方法。雷锋网 AI 开发者将其具体研究内容编译如下。

敲键盘的,你已经暴露了!
在文章开头,作者提出了一个大胆的想法:我们能不能仅仅通过听键盘敲击就知道某人在输入什么?而如果这一操作真的可以实现,那它背后的潜在应用,例如:黑客密码破译,是否将是非常严重的安全隐患呢?(如图 1 所示)

图 1:聆听击键(图片来源:rawpixel.com;eacs.com)
因此,作者参与了一个名为 kido(击键解码)的项目,来探索这是否可能实现(https://github.com/tikeswar/kido)。
我们将这样做
作者提出可以将这个问题,作为一个监督的机器学习问题来处理,然后再逐一完成以下所有步骤:
- 数据收集和准备
- 训练与评估
- 测试和误差分析(提高模型精度)
- 结论;GitHub 链接
注:在这个项目中用到了 Python、Keras 和 TensorFlow。
1. 数据收集
有很多方法可以收集得到敲击键盘的音频数据,在这个实验中,作者为了更好的证明机器学习破译密码在日常生活中的可行性,使用了日常使用的键盘进行打字,并通过内置麦克风 QuickTime Player 录制了打字的音频(图 2)。

图 2:使用笔记本键盘制作训练数据
这种方法有两个优点:一是数据的可变性较小;而正因数据可变性小,它将有助于我们集中注意力去证明(或反证)这个想法,而无须考虑更多变量。
2. 数据准备
明确了数据来源后,下一步是准备数据,这样我们就可以把它输入神经网络(NN)进行训练。
QuickTime 将录制的音频保存为 MP4。首先我们需要将 mp4 转换为 wav,因为有很好的 Python 库可以处理 wav 文件。图 3 右上角子图中的每个峰值对应于一个击键)。

图 3:将 mp4 转换为 wav,然后拆分
然后我们使用静音检测将音频分割成单独的块,这样每个块只包含一个字母。这之后,我们就可以将这些单独的块输入到神经网络中。
但作者想到了一个更好的方法,他选择将单个色块转换成频谱图(图 4)。现在,我们有了使用卷积神经网络(CNN),则可以提供更多信息且更易于使用的图像。

图 4:将单个块转换为频谱图
为了训练网络,作者收集了上面描述的 16000 个样本,确保每个字母至少有 600 个样本(图 5)。
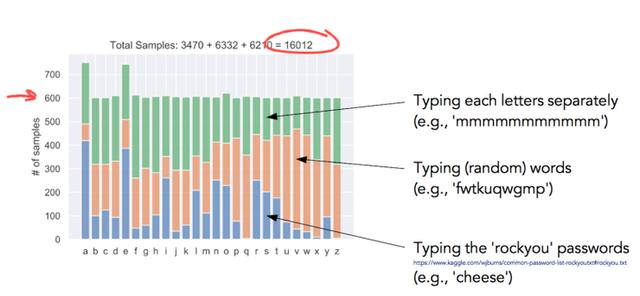
图 5:数据样本
然后将数据重新整理,并分成训练集和验证集。每个字母有大约 500 个训练样本以及 100 个验证样本(图 6)。

图 6:训练-验证拆分
简而言之,这就是我们遇到的最大似然比问题,见图 7。

图 7:机器学习问题表示
3. 训练和验证
作者使用了一个相当小的简单网络架构(基于 Laurence Moroney 的剪刀石头布示例,https://www.coursera.org/learn/convolutional-neural-networks-tensorflow/),参见图 8。
其中,输入图像被缩放到 150 x 150 像素,并且它有 3 个颜色通道。然后它经过一系列的卷积+合并层,变平(用于防止过度拟合的丢失),被馈送到完全连接的层,最后是输出层。输出层有 26 个类,对应于每个字母。
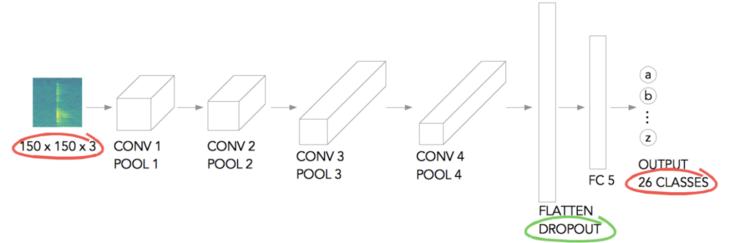
图 8:网络架构
在 TensorFlow 中,模型如下所示:
model = tf.keras.models.Sequential([
# 1st convolution
tf.keras.layers.Conv2D(64, (3,3), activation=’relu’, input_shape=(150, 150, 3)),
tf.keras.layers.MaxPooling2D(2, 2),
# 2nd convolution
tf.keras.layers.Conv2D(64, (3,3), activation=’relu’),
tf.keras.layers.MaxPooling2D(2,2),
# 3rd convolution
tf.keras.layers.Conv2D(128, (3,3), activation=’relu’),
tf.keras.layers.MaxPooling2D(2,2),
# 4th convolution
tf.keras.layers.Conv2D(128, (3,3), activation=’relu’),
tf.keras.layers.MaxPooling2D(2,2),
# Flatten the results to feed into a DNN
tf.keras.layers.Flatten(),
tf.keras.layers.Dropout(0.5),
# FC layer
tf.keras.layers.Dense(512, activation=’relu’),
# Output layer
tf.keras.layers.Dense(26, activation=’softmax’)
])
以及模型摘要:
___________________________________________________________
Layer (type) Output Shape Param #
====================================
conv2d_4 (Conv2D) (None, 148, 148, 64) 1792
___________________________________________________________
max_pooling2d_4 (MaxPooling2 (None, 74, 74, 64) 0
___________________________________________________________
conv2d_5 (Conv2D) (None, 72, 72, 64) 36928
___________________________________________________________
max_pooling2d_5 (MaxPooling2 (None, 36, 36, 64) 0
___________________________________________________________
conv2d_6 (Conv2D) (None, 34, 34, 128) 73856
___________________________________________________________
max_pooling2d_6 (MaxPooling2 (None, 17, 17, 128) 0
___________________________________________________________
conv2d_7 (Conv2D) (None, 15, 15, 128) 147584
___________________________________________________________
max_pooling2d_7 (MaxPooling2 (None, 7, 7, 128) 0
___________________________________________________________
flatten_1 (Flatten) (None, 6272) 0
___________________________________________________________
dropout_1 (Dropout) (None, 6272) 0
___________________________________________________________
dense_2 (Dense) (None, 512) 3211776
___________________________________________________________
dense_3 (Dense) (None, 26) 13338
====================================
Total params: 3,485,274
Trainable params: 3,485,274
Non-trainable params: 0
训练结果如图 9 所示。在大约 13 个 epochs 内,它收敛到 80% 的验证精度和 90% 的训练精度。考虑到问题的复杂性和所使用的简单网络架构,所得较高的准确性确实也令人感到惊讶。

图 9:训练和验证准确性
目前的结果看起来很有希望,但这只是字符级的准确性,而不是单词级的准确性。如要猜测密码,我们必须正确预测每个字符,而不仅仅是大多数字符!参见图 10。

图 10:猜测密码需预测每个字符
4. 测试
为了测试这个模型,作者从 rockyou.txt 列表中数字化了另外 200 个不同的密码,然后尝试使用我们刚刚训练的模型预测单词(图 11)。
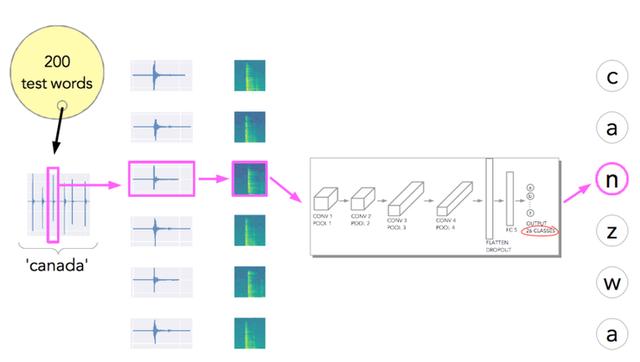
图 11:测试模型
图 12 显示了测试精度;其中,条形图显示了字符级精度(左边的图表显示正确和错误的数目,右边的图表显示相同的百分比)。
可以看到,字符级的测试准确率为 49%,而单词级的测试准确率为 1.5%(即神经网络在 200 个测试词中能完全预测正确 3 个单词)。
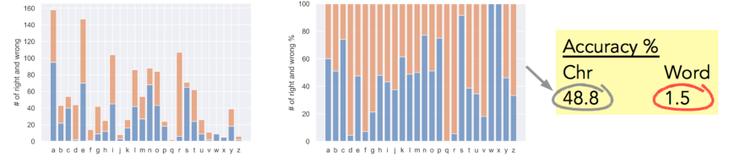
图 12:测试精度
不过鉴于任务的复杂性,1.5% 字级精度也不算差,不过作者也思考了提高精度的一些方法。
怎样提高预测精度呢?
首先,作者对测试结果中个别的误差进行了分析。图 13 显示了一些示例测试结果,其中:
- 第一列包含实际的测试单词;
- 第二列包含相应的预测单词,其中各个字符用颜色编码以显示正确(绿色)和错误(红色)预测;
- 第三列只显示正确预测的字符,错误预测的字符替换为下划线(以便于可视化)。

图 13:数据测试结果
对于「aaron」这个单词,所使用的模型只得到了一个正确字符;对于「canada」一词,预测结果有大多数字符是正确的;而对于「lokita」,它的所有字符预测均是正确的。正如图 12 所示,词级准确率仅为 1.5%。
但反观测试示例(图 14),特别是「canada」,我们意识到它可以正确处理大多数字符,并且非常接近实际单词。那么,如果我们把 CNN 的结果通过拼写检查呢?
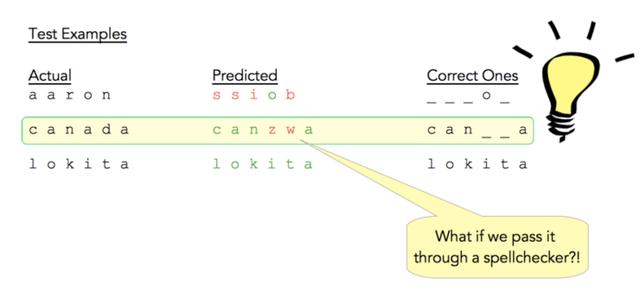
图 14:测试结果展示
这正是作者所做的(图 15),使用了拼写检查器之后,它确实将精确度从 1.5% 提高到了 8%。这也意味着,通过一个相当简单的模型架构+拼写检查器,我们可以正确预测 100 个密码中的 8 个!
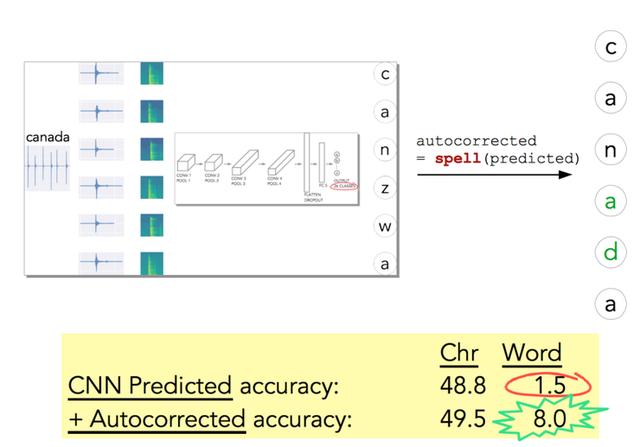
图 15:使用拼写检查器后,精确度提高
作者提出进一步假设,如果采用序列模型(RNN?Transformer?),而不是一个简单的拼写检查器,是否我们可以得到单词检测层面更高的准确性呢?
但通过仔细查看测试结果(图 16),可以注意到「a」被预测为「s」,「n」被预测为「b」,等等。

图 16:测试示例细节放大
这不禁让人想到我们在键盘上的映射误差,而且大部分映射误差(参见图 17)都与邻近度相关。

图 17:在键盘上映射误差
接下来,作者量化了这种相关性与邻近性的误差。图 18 显示了麦克风与键盘之间按一定比例绘制的按键位置。
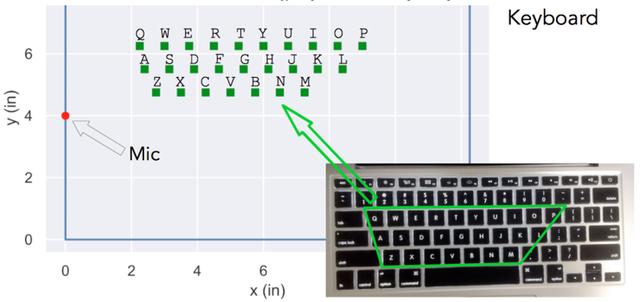
图 18:麦克风和按键位置按比例绘制的键盘
图 19 显示了一些示例字母在数字化键盘上的错误类比图。图中,左上角的图显示「a」被错误地预测为「z」、「x」、「y」、「k」、「s」、「w」或「q」。其他子图的解释类似。

图 19:样本字母的误差图
从图 19 中,我们可以清晰看到,该预测误差与临近度相关。然而,我们能否得到一个更为量化的衡量标准呢?
为了得到这一量化标准,作者将 d_ref 设为参考字母与 mic 的距离,d_predicted 为预测字母与 mic 的距离,d 为 d_ref 与 d_predicted 之差的绝对值(见图 20)。

图 20:一些参量定义
图 21 为所得误差直方图。我们可以看到一个非常明显的趋势,即大多数误差来自临近处。这也意味着我们可以通过更多的数据、更大的网络或能够更好地捕获这些数据的网络架构来提高模型的准确性。
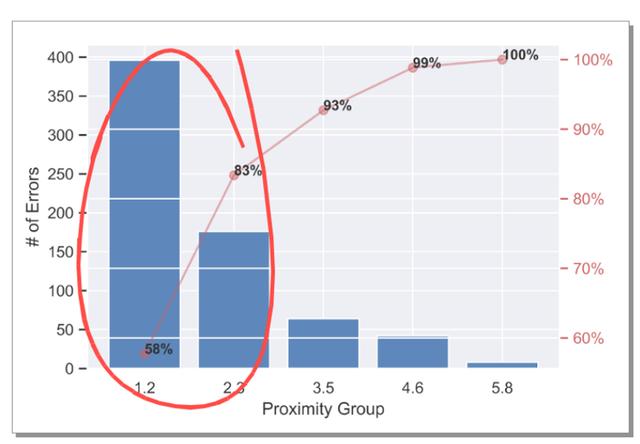
图 21:误差相关的直方图
但是麦克风的位置是否也是误差的来源之一呢?误差与按键离麦克风的距离有关吗?
为了研究这一点,作者也绘制了关于图 12 中的误差图,使得 X 轴上的字母与 MIC 的距离增加(参见图 22)。
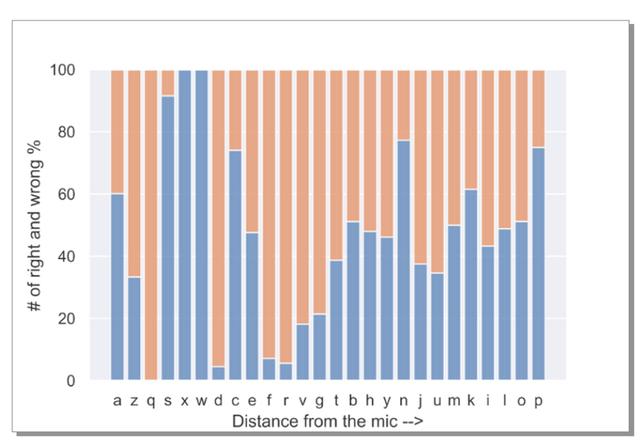
图 22:麦克风位置与误差之间关系的直方图
从图中,我们可以发现误差与按键离麦克风的位置之间并没有很强的相关性,这也可以证明误差与麦克风位置基本是无关的。
不过通过图 22 展示的结果,作者也发现一个非常重要信息,即一个人可以把麦克风放在任何地方监听击键,然后进行黑客攻击。这一发现确实令人毛骨悚然!
模型存在的一些小 BUG
在这项研究中,作者因为只是想验证是否能仅通过听键盘敲击声音,从而进行黑客攻击的想法,因此在具体实验中做了很多简化。
下面是作者提出的一些关于改进模型以处理更复杂和真实的场景的建议:
- 正常的打字速度→具有挑战性的信号处理(隔离单个击键)。因为在这项研究中,作者使用了较慢的速度敲写数据内容。
- 任何按键→具有挑战性的信号处理(大小写?Shift 功能键?…)。因为在这项研究中,作者只使用了小写字母(不包括大写字母、数字、特殊字符、特殊击键等)。
- 背景噪声→添加噪声。因为在本研究的记录数据时,只有一些车辆经过时会出现部分简单和轻微的背景噪声,但没有复杂的背景噪声(例如:餐厅背景噪声等)。
- 不同的键盘和麦克风设置+不同的人打字→更多的数据+数据增强+更大的网络+不同的网络架构可能有助于改进模型。
最后,作者还提出「我们是否能采用其他振动信号代替音频信号」一有趣的想法。

图 23:其它振动信号
最终我们得到这样的结论
考虑到这项研究的简化,作者得出了这样两个结论:
- 通过击键声音破解敲写内容是有可能实现的;
- 通过少量的数据和简单的 CNN 架构+拼写检查,我们可以获得不错的单词级准确率(本研究中为 8%);
误差来源:
- 简单的拼写检查可以提高单词级别的准确性(在本例中从 1.5% 提高到 8%);
- 误差与其他键的接近相关;
- 误差似乎与麦克风位置无关。

原文链接:
https://towardsdatascience.com/clear-and-creepy-danger-of-machine-learning-hacking-passwords-a01a7d6076d5
GitHub 链接:
https://github.com/tikeswar/kido
雷锋网 AI 开发者
机器学习的「反噬」:当 ML 用于密码破解,成功率竟然这么高http://t.zijieimg.com/QmsaJP/



