“血洗”人类的AI登上Nature,你输明白了吗?|赛先生
AlphaStar最初从观看人类玩耍中学习,接着它通过自我对抗来磨练各方面的技能。一两个星期的培训结束后,AlphaStar相当于玩了200年的《星际争霸2》。

(图源:sc2.blizzard.cn)
撰文 | 李薇达
编辑 | 小赛
今年年初,由谷歌旗下的前沿人工智能企业DeepMind所研发的最新人工智能系统AlphaStar以两个5:0连续血洗《星际争霸2》德国职业选手TLO和波兰职业选手MaNa。在总共公开的11场对决中,人类仅在现场直播的一场表演赛中获胜。
今天,DeepMind的研究人员在Nature上发表了题为“Grandmaster level in StarCraft II using multi-agent reinforcement learning”的论文,详细介绍了这个把世界排名24和22的选手按在地上摩擦的系统是如何运作的。
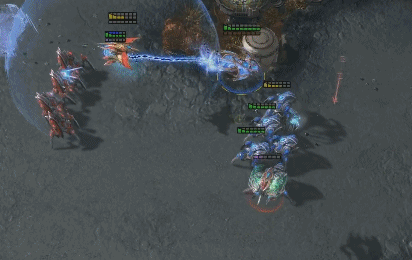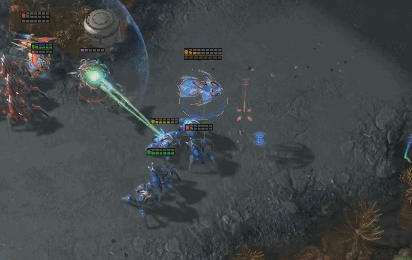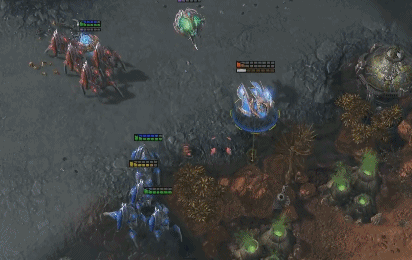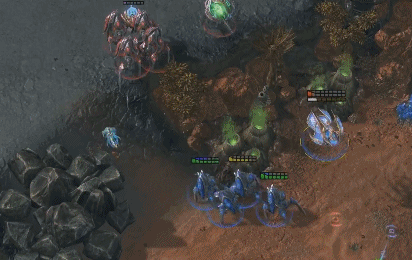
AlphaStar和人类职业选手一样华丽的操作。蓝色为AlphaStar,红色为人类职业选手。(图源:sc2.blizzard.cn)
为何选择《星际争霸2》
长久以来,游戏都被认为是评估人工智能策略性思维的一个理想载体。近几年,AI已经掌握了一些超级复杂的游戏,比如围棋,《超级马里奥》、《雷神之锤3竞技场》,以及《DOTA2》。那么这次AI挑战的这款游戏有何特别之处?
《星际争霸2》(以下简称星际2)是一款发生在科幻世界里的即时战略类游戏。通常情况下,玩家从三个种族(人族、虫族、神族)中选择一个和另一个玩家进行1V1。这三个种族都有不同的单位和建筑以及不同的机制,在对战时需要不同的策略。玩家从一个小基地和几个工人单位开始,收集资源来建造更多的单位和建筑,侦察对手,研究新技术。如果一个玩家失去了所有的建筑,他就输了。
星际2由于它的复杂性一直没有受到AI的挑战,而恰恰又因为它“足够难”, DeepMind和星际2的游戏公司暴雪于2016年达成合作协议,通过这款游戏进行人工智能研究。
这款游戏究竟有多复杂?
首先,游戏理论方面,就像石头剪刀布一样,星际2没有一个最佳致胜策略。因此,人工智能在培训过程中需要不断探索和拓展策略相关知识。
其次,因为战争迷雾的存在,星际2不像围棋那样可以让玩家纵览整个游戏局面。关键信息被隐藏了, AI需要学会使用不完善的信息以及主动“侦查”来进行操作。
再次,游戏大约需要1个小时才能完成。在此期间,玩家不断采取行动来执行整体策略。初期采取的行动可能要到后期才会看到回报。在给定的时间内,人工智能需要通过大量的学习来做出长远来看的最优选择,而不仅仅局限于采取能够立即产生收益的行动。
另外,游戏是实时的。回合制游戏或者下棋都是对方完成一步玩家再进行下一步,而星际玩家必须随着游戏时间的推移不断执行动作。
最后,星际2的操作空间比19X19格的围棋要大得多得多。玩家可以从超过 300 种行为中做选择。在此之上,游戏中的行为是层级的,能够进行调整、增强,有很多游戏单位需要点击屏幕控制。即使一个 84×84 的小屏幕,大概也存在 1 亿种可能的行为。
以上这些挑战在许多战略游戏中也有,但都不是星际2这样的量级。所以为了完全掌握这个游戏,DeepMind需要不同的策略。
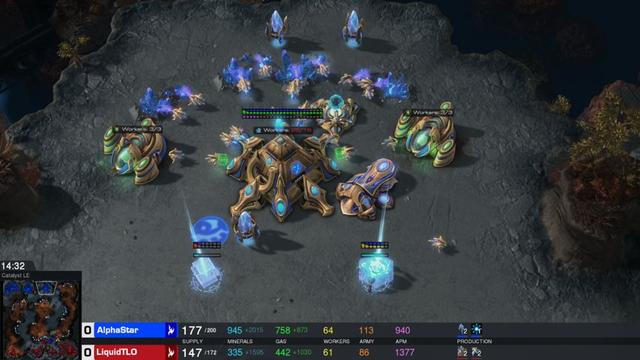
比赛截图(图源:DeepMind)
AlphaStar是如何学习的
根据DeepMind的论文,AlphaStar结合使用了新的技术与通用方法:比如神经内网络架构(neural network architectures)、模拟学习(imitation learning)、强化学习(reinforcement learning)和多智能体学习(multi-agent learning)等等。
总结起来就是:AlphaStar最初从观看人类玩耍中学习,接着它通过自我对抗来磨练各方面的技能。
AlphaStar通过观看玩家的游戏重播创建最初的迭代。暴雪刚开始时挑选出十万份匿名玩家的天梯比赛录像,以此来作为AI模仿训练的数据支撑。AI学习微观策略(比如有效控制单位)和宏观策略(比如搞经济运营和长期目标)。有了这些知识,即便是最困难的情况下,它也可以在95%的时间里击败游戏中的电脑对手。
不过研究人员会告诉你,这些都是小儿科,真正的工作才刚刚开始。
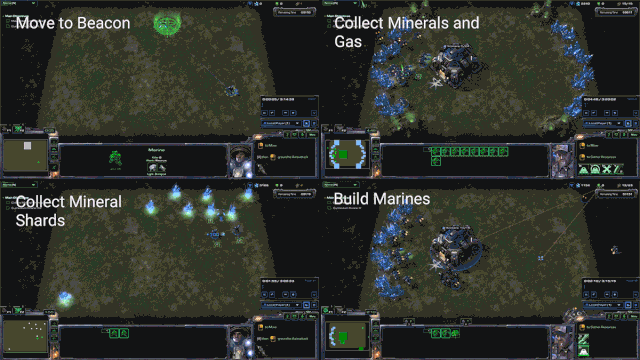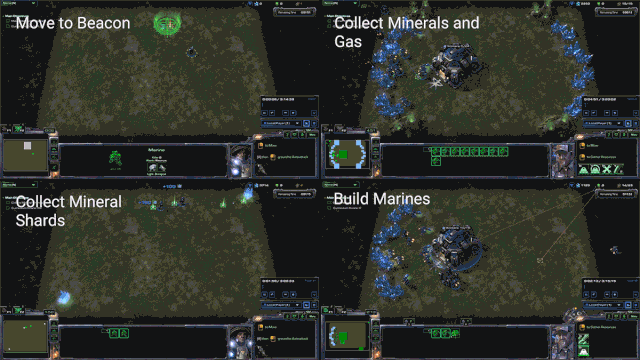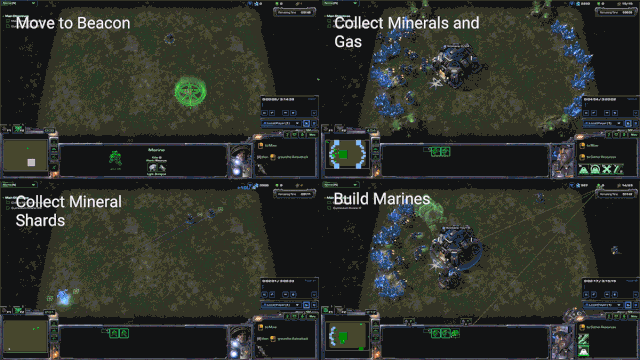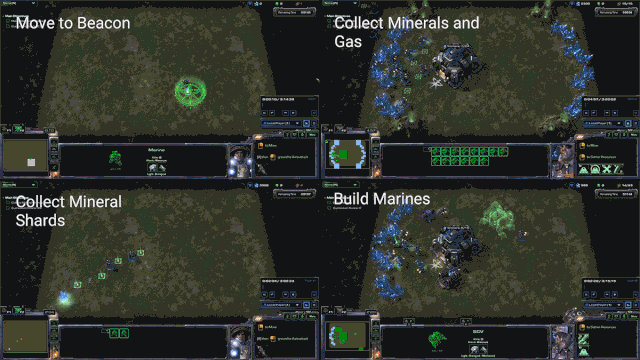
简单的实时迷你游戏可以让研究人员测试AI在特定任务上的性能(图源:DeepMind)
因为星际2不可能仅用一种策略就取胜,所以AlphaStar被分成数百个版本,每一个版本都有一个稍微不同的任务或策略。一种可能不惜一切代价要获得空中优势;另一种可能专注于技术升级;还有一种则像蓝军满广志一样,专门负责击败红军——那些已经成功的战略版本。这就是DeepMind所称的AlphaStar联赛。
这其实是一个神经网络训练程序,不同版本的AlphaStar会在一周内不停地跟彼此打来打去。
这是现代机器学习的核心。DeepMind为这些AI设置成功的参数,比如“赢得比赛”。然后这些AI就会各自做出决定来实现目标。最后获胜的AI继续进行比赛。DeepMind还通过设置某些条件,比如只能用某种种族或某个单位,来使训练更加深入。
最后DeepMind采用获胜最多的版本的特征。这个过程非常高效,因为AI 能够连续快速进行多场比赛。一两个星期的培训结束后,AlphaStar相当于玩了200年的《星际争霸2》。
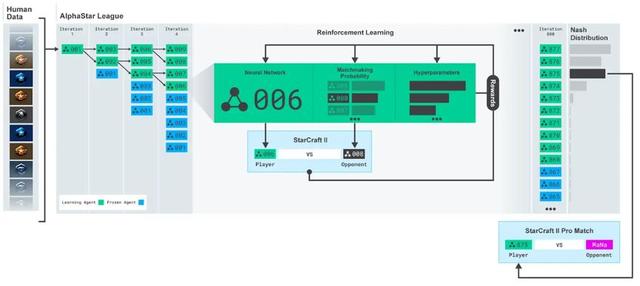
DeepMind研究出了多款AlphaStar,这些AlphaStar最先通过研究上百万份《星际争霸2》玩家天梯录像来学习,接着再通过一种“AlphaStar联赛”的互相训练方式来学习。(图源:DeepMind)
AlphaStar会作弊吗
很多玩家对电脑控制的对手会持怀疑态度。为了解除疑虑,DeepMind对一些大家关注的问题给出了解释。
AlphaStar不是通过代码,也不是像人类那样通过移动“视角”来看这个游戏世界。它看到的是一个放大的地图,不过它也看不透被战争迷雾遮挡的部分。它看到的只有地图上有单位的部分。

AlphaStar和MaNa的第二场比赛。从AlphaStar的角度来看游戏:对神经网络的原始观察输入,神经网络的内部激活,agent考虑采取的一些的行动,例如点击哪里和建造什么,以及预测的结果。(图源:DeepMind)
人类每分钟能执行的动作数量(APM,又称“手速”)在生理上是有限的。为了公平起见,DeepMind限制了AlphaStar的“手速”:在每5秒的时间窗口中,AI最多只能执行22个非重复操作。
AlphaStar也没有超人的反应时间。DeepMind测试了它对事物的反应速度。从它观察到发生了什么,然后开始处理,到把它选择的内容传达给游戏的时间接近350毫秒,其实比人还慢。
游戏之外
虽然《星际争霸》只是一个游戏,但研究人员认为AlphaStar背后的技术可以用来解决许多问题:例如,它的神经网络结构能够根据不完全的信息来模拟非常长的可能动作序列——游戏通常持续一个小时,动作数万次。这可以用于天气预测、气候建模、语言理解等等。
另外, AlphaStar的一些训练方法有助于研发安全可靠的AI。比如它创新的联赛培训流程有利于提高人工智能系统的安全性和鲁棒性,特别是在能源等十分强调安全的领域。

(图源:sc2.blizzard.cn)
DeepMind的研究人员表示,AlphaStar是第一个在《星际争霸》中达到顶级(grandmaster)水平的AI,也是第一个在不降低游戏难度的情况下,通过广泛的职业电子竞技达到人类玩家最高联赛等级的AI。
今年7月,暴雪公司宣布AlphaStar已匿名登陆欧服天梯。如果你想与这位大名鼎鼎的AlphaStar切磋一番,可前往欧服一战,为人族挽回点尊严。
参考资料
[1] https://www.nature.com/articles/s41586-019-1724-z
[2] https://liquipedia.net/starcraft2/2019_StarCraft_II_World_Championship_Series_Circuit/Standings
[3] http://sc2.blizzard.cn/articles/46042/78710
[4] https://deepmind.com/blog/article/alphastar-mastering-real-time-strategy-game-starcraft-ii
[5] https://deepmind.com/blog/announcements/deepmind-and-blizzard-open-starcraft-ii-ai-research-environment
[6] https://venturebeat.com/2019/01/24/alphastar-deepmind-beats-starcraft-pros/
https://news.blizzard.com/en-us/starcraft2/22933138/deepmind-research-on-ladder
“血洗”人类的AI登上Nature,你输明白了吗?|赛先生http://t.zijieimg.com/xaMgts/