Google Coral Edge TPU与 英伟达 Jetson Nano:快速深入了解Edge AI 边缘人工智能的性能。
最近我一直在阅读,测试和写一些关于边缘计算的内容,主要关注边缘AI。 最近很酷的新硬件上架,我渴望比较新平台的性能,甚至测试它们与高性能系统的对比。

硬件
我感兴趣的主要设备是新的英伟达 Jetson Nano(128CUDA)和Google Coral Edge TPU(USB加速器),我还将测试i7-7700K + GTX1080(2560CUDA),Raspberry Pi 3B +,以及我自己的老主力,一个2014年的macbook pro,包含一个i7-4870HQ(没有支持CUDA的内核)。

软件
我将使用MobileNetV2作为分类器,在imagenet数据集上进行预训练。我直接从Keras使用这个模型,我使用TensorFlow后端。使用GPU的浮点权重,以及CPU和Coral Edge TPU的8位量化tflite版本。
首先,加载喜鹊的模型和图像。然后我执行1个预测作为预热(因为我注意到第一个预测总是比下一个预测慢很多)。我让它睡了1秒,所以所有线程肯定都完成了。然后脚本为它运行,并对同一图像进行250次分类。通过对所有分类使用相同的图像,我们确保在整个测试过程中它将保持接近数据总线。毕竟,我们对推理速度感兴趣,而不是更快地加载随机数据的能力。
使用CPU的量化tflite模型得分是不同的,但它似乎总是返回与其他人相同的预测,所以我想这在模型中是奇怪的,我很确定它不会影响性能。
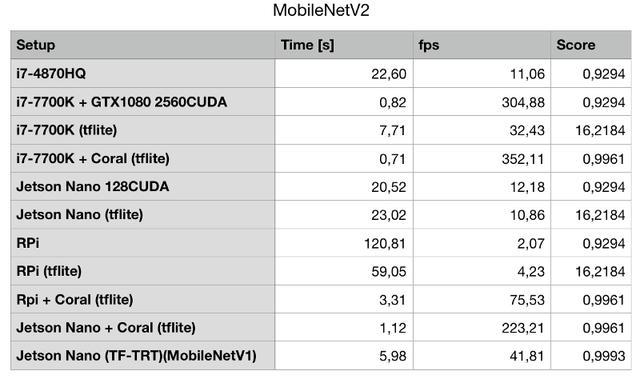
现在,因为不同平台的结果是如此不同,所以很难想象,所以这里有一些图表,选择你喜欢的…
分析
第一张图中有3个条形图跳入视图。 (是的,第一张图,线性刻度fps,是我最喜欢的,因为它显示了高性能结果的差异)在这3个柱中,其中2个是由Google Coral Edge TPU USB加速器实现的,第3个是由英特尔i7-7700K辅助的全面NVIDIA GTX1080。

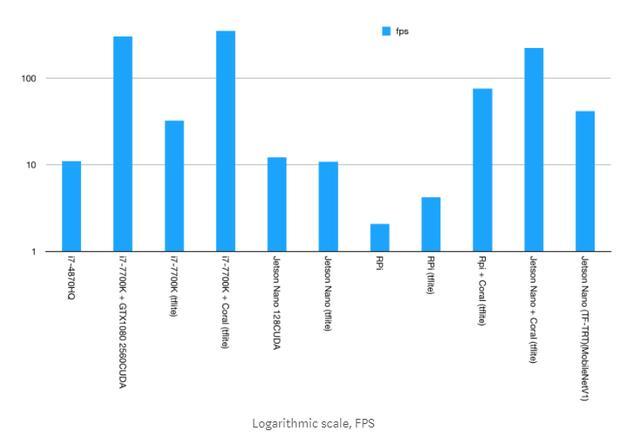
看得更近,你会看到GTX1080实际上被Coral击败了。让它下沉几秒钟,然后准备被吹走,因为GTX1080最大功率为180W,与Coral2.5W相比绝对是巨大的。
打击太大??好的,让我们继续:
接下来我们看到的是,英伟达 Jetson Nano的得分并不高。虽然它有一个支持CUDA的GPU,但实际上并不比我原来的i7-4870HQ快得多。但这是一个问题,“不是更快”,它仍然比50W,四核,超线程CPU更快。几年前,真的,但仍然。 Jetson Nano从来没有消耗过超过12.5W的短期平均值,因为这就是我的动力。功耗降低75%,性能提升10%。
很明显,它本身的Raspberry Pi并不是什么令人印象深刻的东西,不是浮点模型,对量化模型来说仍然没有任何用处。但是,嘿,无论如何我准备好了文件,它能够运行测试,所以更多的总是更好吗?并且仍然有点有趣,因为它显示了Pi中的ARM Cortex A53与Jetson Nano中的A57之间的差异。
英伟达 Jetson Nano
因此,Jetson Nano并没有使用MobileNetV2分类器提供令人印象深刻的FPS费率,但正如我已经说过的那样,这并不意味着它不是一个很有用的工程。 它很便宜,它不需要大量的能量来运行,也许最重要的属性是它运行TensorFlow-gpu(或任何其他ML平台),就像你以前一直使用的任何其他机器一样。

只要您的脚本没有深入到CPU体系结构中,您就可以运行与i7 + CUDA GPU完全相同的脚本,也可以进行培训! 我仍然觉得NVIDIA应该使用TensorFlow预加载L4T,但我会尽量不再愤怒。 毕竟,他们对如何安装它有一个很好的解释(不要被愚弄,不支持TensorFlow 1.12,只有1.13.1)。
Google Coral Edge TPU
好吧,我非常喜欢设计精良,效率高的电子设备,所以我可能不是很客观。 但是这件事……这是绝对美丽的事情!

Edge TPU就是我们所说的“ASIC”(专用集成电路),这意味着它具有FET等小型电子部件和直接在硅层上烧制的容量的组合,这样它就可以完全实现 它需要做的是加快推理。
推断,是的,Edge TPU无法执行向后传播。

这背后的逻辑听起来比现在更复杂。 (实际上创建硬件并使其工作,是完全不同的事情,而且非常非常复杂。但逻辑功能要简单得多)。 如果你真的对它的工作方式感兴趣,可以查看“数字电路”和“FPGA”,你可能会找到足够的信息让你在接下来的几个月里忙碌起来。 有时开始时比较复杂,但真的很有趣!
但这正是为什么Coral在比较性能/瓦特数时处于如此不同的原因,它是一堆电子设备,旨在完成所需的按位操作,基本上没有任何开销。
为什么GPU没有8位模型?
GPU本质上被设计为细粒度并行浮点计算器。因此,使用浮动正是它所创造的,以及它的优点。 Edge TPU设计用于执行8位操作,并且CPU具有比完全位宽浮点数更快的8位内容更快的方法,因为它们在很多情况下必须处理这个问题。
为何选择MobileNetV2?
我可以给你很多理由,为什么MobileNetV2是一个很好的模型,但主要原因是,它是谷歌为Edge TPU提供的预编译模型之一。
Edge TPU还有哪些其他产品?
它曾经是不同版本的MobileNet和Inception,但截至上周末,谷歌推出了一个更新,允许我们编译自定义TensorFlow Lite模型。但限制是,并且可能永远是TensorFlow Lite模型。这与Jetson Nano不同,那个东西可以运行任何你想象的东西。
Raspberry Pi + Coral与其他相比
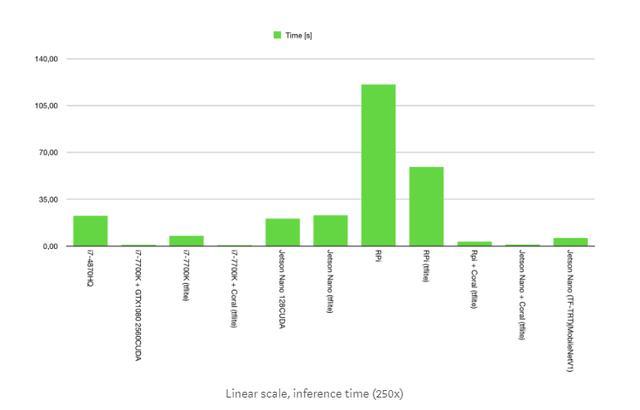
为什么连接到Raspberry Pi时Coral看起来要慢得多?答案很简单直接:Raspberry Pi只有USB 2.0端口,其余的都有USB 3.0端口。而且由于我们可以看到i7-7700K在Coral和Jetson Nano上的速度更快,但仍然没有得到Coral开发板在NVIDIA测试时的分数,我们可以得出结论,瓶颈是数据速率,不是Edge TPU。
我觉得这对我来说已经足够长了,也许对你来说也是如此。 我对Google Coral Edge TPU的强大功能感到非常震惊。 但对我来说,最有趣的设置是NVIDIA Jetson Nano与Coral USB加速器的结合。 我肯定会使用这种设置,感觉就像是一个梦想。
说到Google Coral的开发板Dev Board,以及Edge TPU,那就顺便提一下基于Coral Dev Board开发的Model Play。它由国内团队研发,是面向全球 AI 开发者的 AI 模型共享市场。Model Play 不仅为全球开发者提供了 AI 模型展示交流的平台,更能搭配含 Edge TPU 的 Coral Dev Board 进行使用,加速 ML 推理,通过手机实时预览模型运行效果,助力 AI 由原型向产品拓展。

开发者既能发布自己训练的 AI 模型,也可以订阅并下载自己感兴趣的模型,用于再训练和拓展自己的 AI 创意,实现想法-原型-产品的过程。Model Play 中还预置了各种常用 AI 模型,例如 MobileNetV1、InceptionV2 等,并支持可再训练模型的提交发布,方便用户在自己业务数据上优化微调。
就如谷歌在今年的I/O大会上,号召开发者们,共同为开发社区做出贡献。与此同时,Model Play团队也正在向全球开发者发出了AI模型召集令,征集基于 TensorFlow、可在 Google Coral Dev Board 上运行的深度学习模型,以鼓励更多开发者们参与活动,与全球千万 AI 开发者,分享创意和想法



