神经网络和人工智能是目前最炙手可热的科技,它们应用广泛,在各种你喜欢或者不喜欢的社交平台上助力识别图像,在智能音箱上语音识别,在智能手机里担任数字语音助理,神经网络比人类有更好的识别模式能力。不久,它们会很快应用到注入安全摄像头这样的嵌入式设备中,带来更多意想不到的体验。
近日,人工智能处理器开发商Habana Labs在京召开发布会为我们隆重介绍了最新研制的两款AI芯片及解决方案,分别用于推理和训练,适合数据中心、自动驾驶等应用,竞争目标直指用于AI领域最高性能的CPU和英伟达GPU。
Goya—三倍性能,架构创新
Goya产品是一款基于PCIE的产品,主要是用于传统服务器,主要是未来插在服务器当中提供推理和预测的。据介绍,Goya的性能比目前最好的用于推理和训练GPU产品高三倍。从能耗比来讲,也比GPU有两倍的优势。在实时处理上,Goya的延迟也比GPU要低很多,几乎可以做到实时处理图片。
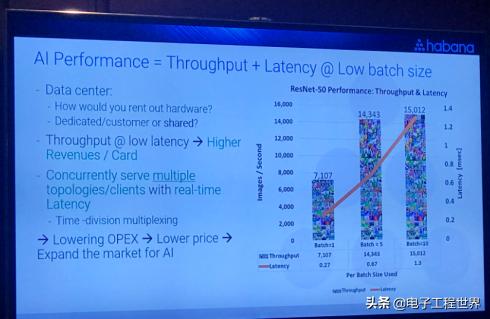
Goya之所以能有着如此出众的性能,是得益于Habana对芯片的架构进行了独有的设计。Habana Labs的首席商务官Medina说到:“GPU和CPU他们各自是面对于通用计算或者是常用的图形处理,所以他们从架构上来讲并不适合于做人工智能这方面的计算工作。但是Goya是完全针对于人工智能的需求来设计的。”而在传统运行当中,为了实现处理性能的优越性就会把Batch Size最大化,必须把很多内容加载进去,所以无形当中就会增加计算当中的延迟。但Goya凭借着自身低延迟特性,可以实现在Batch Size等于1的情况下,一次可以处理单张图片的能力,甚至实现到一秒钟处理7000多张的性能。
与英伟达的V100 GPU相比,HL-1000驱动的Goya在ResNet-50上进行推理时,提供了超过4倍的吞吐量,2倍的能源效率,以及一半的延迟。作为代表Habana第二次进军AI市场的武器,它可以达到每秒1,650张图像,批量大小为64。对于V100每秒1,360张图像的最佳训练结果显然有所突破。据了解,Goya已可支持Facebook的机器学习编译器Glow,其驱动业已集成在Linux中,并可无缝从CPU或GPU中迁移。
Medina介绍,精度是推理的一个重要指标,在整形化(quantization)过程中必然会造成一些信息的丢失,Goya有着很强的算法团队,即使做了这样的量化,整个精度损失也是非常小的。此外,通过Habana的软件站—Synapse AI可以直接支持各种各样的框架结构,客户可在框架上实现的工作可以直接简单部署到Goya处理器当中。
与RDMA的完美融合—Gaudi

Habana Gaudi™人工智能训练处理器,基于Gaudi的训练系统实现了比拥有相同数量的GPU系统高四倍的处理能力。此外,Gaudi™处理器的创新架构可实现训练系统性能的近线性扩展,即使是在较小Batch Size的情况下,也能保持高计算力。因此,基于Gaudi™处理器的训练性能可实现从单一设备扩展至由数百个处理器搭建的大型系统的线性扩展。
核心架构
Gaudi拥有8个VLIW SIMD(超长指令字,单指令多数据)张量处理器(TPC),专门为AI工作负载设计。不同之处包括所支持的数据类型——虽然两者都是混合精度,但Goya侧重于整数乘法器,而Gaudi 更侧重于更精确的数据格式,如BF16和FP32。
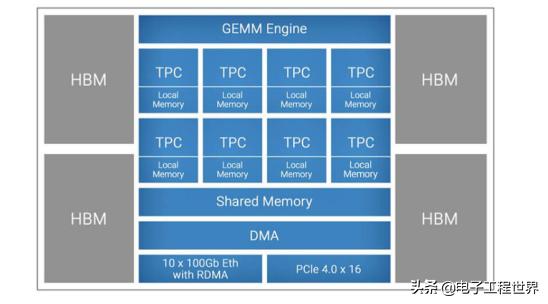
在推理处理器Goya上,Habana有着有DDR4内存,在Gaudi上,Habana配备了四个HBM2(高带宽内存,第二代)内存。因此,与Goya相比,它在吞吐量和片上内存方面实现了不同的平衡。而且Gaudi采用了OCP (Open Computer Project)加速器模型兼容的夹层加速卡,带有32GB的HBM2内存(HL-205),用于数据中心的8卡超级计算机盒(HLS-1)。Medina介绍:“训练解决方案对HBM2s的吞吐量非常大,所以我们对芯片内存大小不那么敏感,我们设计了专门的内存控制器来提供1 TB/s的吞吐量,这对于任何规模的处理器来说都是非常高的吞吐量。”

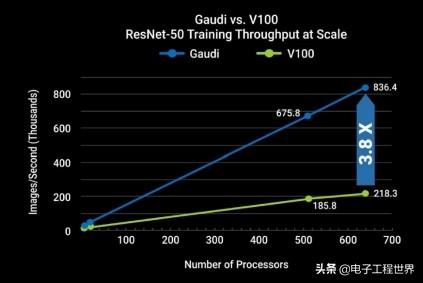
Gaudi最大的潜在优势将是提供大规模性能的能力,这对于构建更大、更复杂的神经网络一直是一个挑战。对于大多数训练设置,一旦超过8个或16个加速器,也就是说,一旦离开服务器机箱,性能就趋于平稳。Medina说,Gaudi的技术并非如此。他指出,同样的ResNet-50训练扩展到数百个HL-2000处理器,其性能接近线性增长。与V100相比,Habana技术能够在650处理器的水平上提供3.8倍的吞吐量优势。
Roce RDMA—促进深度学习的催化剂
先科普一下,RoCE(RDMA over Converged Ethernet)是一种允许通过以太网使用远程直接内存访问(RDMA)的网络协议。通俗的说可以看成是远程的DMA技术,为了解决网络传输中服务器端数据处理的延迟而产生的。RDMA允许用户态的应用程序直接读取或写入远程内存,而无内核干预和内存拷贝发生。起初,只应用在高性能计算领域,最近,由于在大规模分布式系统和数据中心中网络瓶颈越来越突出,逐渐走进越来越多人的视野。
在今年的GTC大会上,英伟达首席执行官Jensen Huang将RoCE作为一种大大提高深度学习工作可扩展性的方法。RDMA 协议来自于高性能计算领域,它改进了传统的 TCP/IP 协议栈在高速网络下的诸多缺点,使得网络通信数据传输不再经过内核或 CPU,取而代之的则是直接通过网卡读写内存来进行,从而在应用上能够充分利用万兆以上的网络带宽。显然英伟达看到了这一走势,以69亿美元高价收购数据中心InfiniBand网络的绝对王者——以色列创企Mellanox。
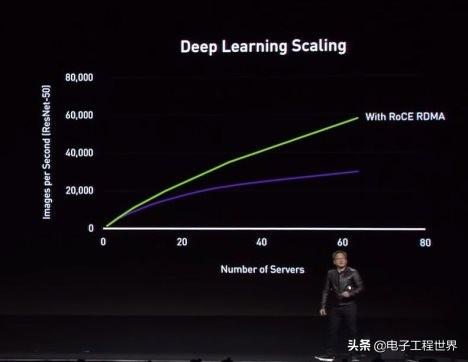
Habana的思路也和Jensen Huang观点不谋而合,并坚信RoCE是扩展人工智能的完美解决方案。Gaudi集成了芯片上的RoCE,配备10个100千兆以太网端口。在类似于HLS-1的系统中,这10个片上端口中的一些可以分配给各个Gaudi 处理器之间的非阻塞all-to-all连接。因此,通过提供这种级别的RoCE集成,释放了客户设计无限规模系统的能力,从小系统到大的系统,真正给予他们投资于人工智能培训加速的空间。另外,夹层卡是Habana的HLS-1服务器的基础,这是一种开放硬件计算加速器模块形式。
数据并行化、层级化保证计算效率
Medina描述了如何将端口配置为20 50GB端口,与16个Gaudi芯片并用,而不使用额外组件,或者使用现成的以太网交换机创建用于大规模数据并行的层次结构。以太网交换机也可以将64个Gaudi连接到一个网络跃点中,适合于模型并行训练的新兴技术,这需要巨大的带宽。因此通过这种数据并行化和层级化处理提高处理效率的方法,可以建立1千片Gaudi芯片的系统。在AI中,除了数据的并行化处理之外,还有模型的并行化处理:把大模型分成多个小模型,在每个处理器当中处理其中的一部分,这样实现一个模型的并行化。然而最大的挑战就是每个处理器之间的通讯的带宽,由于Gaudi有很多通讯接口,因此保证了通讯带宽。而英伟达GDX-2没有这么强的能力,因为英伟达的通讯接口有限,且采用了私有的协议。
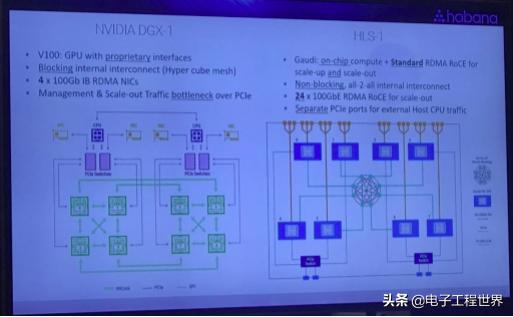
此外,Habana不支持跨多个处理器的缓存一致的全局内存空间。Gaudi设计师们认为缓存一致是一种性能杀手,无法有效扩展到少数加速器之外。从他们的角度来看,实现训练神经网络的可扩展性基本上是一个网络问题,使用RDMA可以非常有效地生成更大的模型。Habana通过在Gaudi芯片中插入大量网络带宽,以RDMA over Converted Ethernet(ROCE)的形式实现这一点。这样做能够使客户能够轻松地将Habana硬件放入现有的数据中心,以及使用各种网络提供商提供的标准以太网交换机构建AI集群。
就在此前,英伟达也推出了一款深度学习的超级计算机DGX2,相比而言Gaudi也有着自己的特色:在Gaudi系统当中,每片之间可以直接通讯,任何一个芯片之间都可以直接实现数据的交换;此外,与英伟达对NVLink所做的不同,Habana在单一芯片上集成了10个100GbE以太网端口,每个以太网端口均支持RDMA over Converged Ethernet (RoCE v2) 功能,省略了PCIE的交换,从而让AI系统通过标准以太网,在速度和端口数方面获得几乎无限的可扩展性;而且与DGX2在系统管理上有着明显的不同,对于DGX2而言数据通讯必须在PCIE一个总线上复用,因此在传输性能上会有一定的损失。Gaudi的数据传输和管理是分开的,在它的总线上没有任何复用,所以总线效率上也是最高的。

在模型并行处理方面,DGX2提供的NVLink端口有限,最大支持16个并行处理。这就在很大程度上限制了模型并行处理能力。而Gaudi整个系统当中有8片这样子Gaudi Cards,可以把80个100G的以太网口对外实现互联,可以做到几十个,甚至几百个Gaudi系统之间并行的模型化处理。
借势而行
Habana Labs中国区总经理于明扬乐观表示,云端市场尤其是推理市场还处在高速发展的蓝海市场阶段,而5G和边缘计算也对云端有了更强的需求,未来前景广阔。
有数字估计,云数据中心服务器中,AI训练芯片的渗透率将提高到2022 年的13%。而推理芯片在云服务器和企业本地服务器上的渗透率到2022 年分别达到20%和7%。在急剧扩大的市场中,将不断有选手斜刺里杀出,而最终极的拷问是如何在新老格局对抗中建立独树一帜的优势。
作为一家初创公司,Habana Labs去年年底完成超额认购的7500万美元B轮融资。此次融资由英特尔投资领投,WRV Capital等也加入其中。自2016年创立以来,该公司已筹集到1.2亿美元。Eitan Medina表示,这一资金将支持针对推理和训练解决方案的产品发展蓝图,包括下一代7nm处理器,同时扩展销售与客户支持团队。

而在当今格局下,采用“CPU+加速芯片”的异构计算模式恐将会被打破。在前有 Nvidia 的 GPU+CUDA,后GPU+OpenCL以及FPGA+OpenCL来对垒的情形下,持续的革新才是Habana的出路。从此次发不得两大解决方案来看:Gaudi为客户提供了更强的处理能力,更高的性能功耗,给予客户提供了一种原来根本就无法实现的这种可以扩展的能力。而Goya凭借高计算能力、高性价比、共享多个资源这三大优势,将会在未来闯出一片天空。
重装上阵!Habana携2款深度学习芯片叫板英伟达http://t.zijieimg.com/hPRhw5/
转载请注明:徐自远的乱七八糟小站 » 重装上阵!Habana携2款深度学习芯片叫板英伟达



