发表于 ECCV-2016 的 SSD 算法是继 Faster RCNN 和 YOLO 之后又一个杰出的物体检测算法。与 Faster RCNN 和 YOLO 相比,它的识别速度和性能都得到了显著的提高。
1. 物体检测
- 定位 (Localization): 检测器需要给出物体在图像中的位置 (bounding box)
- 分类 (Classification): 检测器需要给出物体的类别 (label)
 图片修改自斯坦福 CS231N 课件
图片修改自斯坦福 CS231N 课件
2. 相关的算法
- 基于区域的算法: RCNN, Fast RCNN, Faster RCNN, Mask RCNN 等
整个检测过程分为两个阶段。在第一个阶段,检测器需要找到一些假设的区域 (ROI);在第二个阶段,检测器需要在这些假设区域上进行分类 (classification) 和 位置回归 (bounding box regression)。 Faster RCNN
Faster RCNN - 基于回归的算法:YOLO 等
端到端 (end-to-end) 的检测过程,直接回归出物体的类别和位置。 YOLO
YOLO
3. SSD算法
SSD 算法是 Faster RCNN 和 YOLO 的结合:
- 采用了基于回归的模式(类似于YOLO),在一个网络中直接回归出物体的类别和位置,因此检测速度很快。
- 同时也利用了基于区域的概念(类似于Faster RCNN),在检测的过程中,使用了许多候选区域作为ROI。
骨干网络:
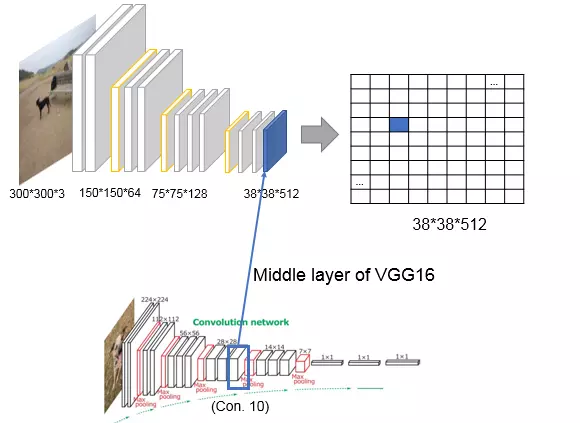
SSD的骨干网络是基于传统的图像分类网络,例如 VGG,ResNet 等。本文以 VGG16 为例进行分析。如下图所示,经过10个卷积层(con. layer) 和 3个池化层(max pooling) 的处理,我们可以得到一个尺寸为 38×38×512 的特征图 (feature map)。下一步,我们需要在这个特征图上进行回归,得到物体的位置和类别。
回归 (Regression):
和 YOLO 的回归操作相似,首先我们先考虑在特征图的每个位置上,有且只有一个候选框(default box)的情况。
- 位置回归:检测器需要给出框中心偏移量 (cx,cy),相对于图片尺寸的宽度和高度 (w,h),总计需要回归四个值。
- 分类: 对于每一个 bounding box,我们需要给出 20个类别+1个背景类 的得分(score)。
 回归
回归对于每一个位置,我们需要一个25维的向量来存储检测物体的位置和类别信息。对于我们的38×38的特征图,我们需要一个维度为 38×38×25 的空间来存储这些信息。因此,检测器需要学习特征图(38×38×512)到检测结果(38×38×25)的映射关系。这一步转换,使用的是卷积操作:使用25个3×3的卷积核,对特征图进行卷积。到这里,我们已经完成了在每个位置上回归一个框的操作。
- 多个候选框:SSD在每个位置上,希望回归k个基于不同尺寸的框。因此在每个位置上需要 25×k 维的空间,存储这些框的回归和分类信息,因而卷积操作变成了使用 25×k个3×3的卷积核,来获得 38×38×25k 维度的检测结果图(score map)。
- 多个特征图:对于神经网络,浅层的特征图包含了更较多的细节信息,更适合进行小物体的检测;而较深的特征图包含了更多的全局信息,更适合大物体的检测。因此,通过在不同的特征图上对不同尺寸的候选框进行回归,可以对不同尺寸的物体有更好的检测结果。
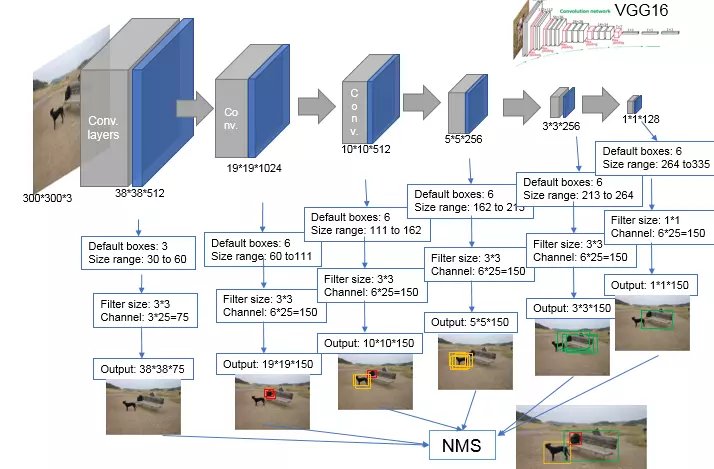 多个特征图
多个特征图
4. 实验结果

SSD的检测精度和速度都非常出色,76.8 mAP 和 22FPS 超过了Faster RCNN和YOLO。
作者:LevenWang
链接:https://www.jianshu.com/p/d9815cc57866
来源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。
转载请注明:徐自远的乱七八糟小站 » 简析物体识别SSD算法



