
【新智元导读】ICLR 2019一篇论文指出:DNN解决ImageNet时的策略似乎比我们想象的要简单得多。这个发现使我们能够构建更具解释性和透明度的图像分类管道,同时也解释了现代CNN中观察到的一些现象。
全文约3300字6图,读完可能需要10分钟
CNN非常擅长对乱序图像进行分类,但人类并非如此。
在这篇文章中,作者展示了为什么最先进的深度神经网络仍能很好地识别乱码图像,探究其中原因有助于揭示DNN使用让人意想不到的简单策略,对自然图像进行分类。
在ICLR 2019一篇论文指出上述发现能够:
- 解决ImageNet比许多人想象的要简单得多
- 使我们能够构建更具解释性和透明度的图像分类pipeline
- 解释了现代CNN中观察到的一些现象,例如对纹理的偏见以及忽略了对象部分的空间排序
复古bag-of-features模型
在深度学习出现之前,自然图像中的对象识别过程相当粗暴简单:定义一组关键视觉特征(“单词”),识别每个视觉特征在图像中的存在频率(“包”),然后根据这些数字对图像进行分类。 这些模型被称为“特征包”模型(BoF模型)。
举个例子,给定一个人眼和一个羽毛,我们想把图像分类为“人”和“鸟”两类。最简单的BoF模型工作流程是这样的:对于图像中的每只眼睛,它将“人类”的证据增加+1。反之亦然;对于图像中的每个羽毛,它将增加“鸟”的证据+1;无论什么类积累,图像中的大多数证据都是预测的。
这个最简单的BoF模型有一个很好的特性,是它的可解释性和透明的决策制定。我们可以准确地检查哪个图像特征携带了给定的类的证据,证据的空间整合是非常简单的(与深度神经网络中的深度非线性特征整合相比),很容易理解模型如何做出决定。
传统的BoF模型在深度学习开始之前一直非常先进、非常流行。但由于其分类性能过低,而很快失宠。可是,我们怎么确定深度神经网络有没有使用与BoF模型截然不同的决策策略呢?
一个很深却可解释的BoF网络(BagNet)
为了测试这一点,研究人员将BoF模型的可解释性和透明度与DNN的性能结合起来。
- 将图像分割成小的q x q图像色块
- 通过DNN传递补丁以获取每个补丁的类证据(logits)
- 对所有补丁的证据求和,以达到图像级决策
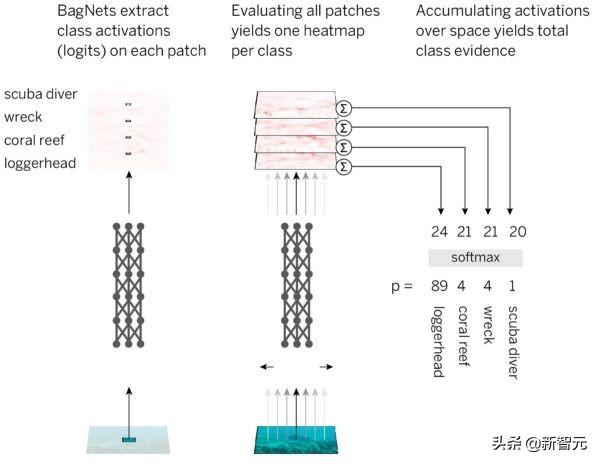
BagNets的分类策略:对于每个补丁,我们使用DNN提取类证据(logits)并总结所有补丁的总类证据
为了以最简单和最有效的方式实现这一策略,我们采用标准的ResNet-50架构,用1×1卷积替换大多数(但不是全部)3×3卷积。
在这种情况下,最后一个卷积层中的隐藏单元每个只“看到”图像的一小部分(即它们的感受野远小于图像的大小)。
这就避免了对图像的显式分区,并且尽可能接近标准CNN,同时仍然实现概述的策略,我们称之为模型结构BagNet-q:其中q代表最顶层的感受域大小(我们测试q=9,17和33)。BagNet-q的运行时间大约是ResNet-50的运行时间的2.5倍。
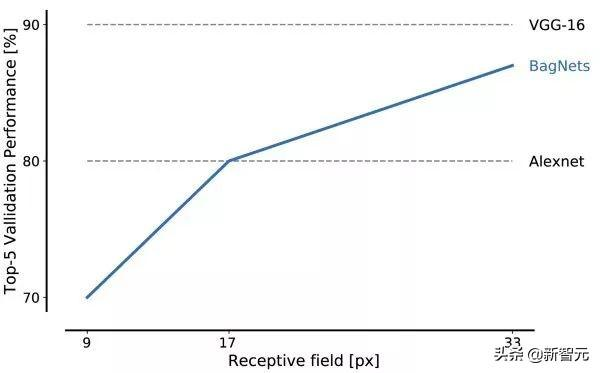
在ImageNet上具有不同贴片尺寸的BagNets的性能。
即使对于非常小的贴片尺寸,BagNet上的BagNets性能也令人印象深刻:尺寸为17 x 17像素的图像特征足以达到AlexNet级别的性能,而尺寸为33 x 33像素的特征足以达到约87%的前5精度。通过更仔细地放置3 x 3卷积和额外的超参数调整,可以实现更高的性能值。
这是我们得到的第一个重要结果:只需使用一组小图的特性即可解决ImageNet问题。对象形状或对象部分之间的关系等远程空间关系可以完全忽略,并且不需要解决任务。
BagNets的一大特色是他们透明的决策。例如,我们现在可以查看哪个图像特征对于给定的类最具预测性。

图像功能具有最多的类证据。 我们展示了正确预测类(顶行)的功能和预测错误类(底行)的分散注意力的功能。
上图中,最上面的手指图像被识别成tench(丁鱥guì,是淡水钓鱼的主要鱼种,也是鲈鱼等猎食性鱼类的饲料),因为这个类别中的大多数图像,都有一个渔民像举奖杯一样举起丁鱥。
同样,我们还得到一个精确定义的热图,显示图像的哪些部分促使神经网络做出某个决定。

来自BagNets的热图显示了确切的图像部分对决策的贡献。 热图不是近似的,而是显示每个图像部分的真实贡献。
ResNet-50与BagNets惊人相似
BagNets表明,基于本地图像特征和对象类别之间的弱统计相关性,可以在ImageNet上达到高精度。
如果这就够了,为什么像ResNet-50这样的标准深网会学到任何根本不同的东西? 如果丰富的本地图像特征足以解决任务,那为什么ResNet-50还需要了解复杂的大尺度关系(如对象的形状)?
为了验证现代DNN遵循与简单的特征包网络类似的策略的假设,我们在BagNets的以下“签名”上测试不同的ResNets,DenseNets和VGG:
- 决策对图像特征的空间改组是不变的(只能在VGG模型上测试)
- 不同图像部分的修改应该是独立的(就其对总类证据的影响而言)
- 标准CNN和BagNets产生的错误应该类似
- 标准CNN和BagNets应对类似功能敏感
在所有四个实验中,我们发现CNN和BagNets之间的行为非常相似。 例如,在上一个实验中,我们展示了BagNets最敏感的那些图像部分(例如,如果你遮挡那些部分)与CNN最敏感的那些基本相同。
实际上,BagNets的热图(灵敏度的空间图)比由DeepLift(直接为DenseNet-169计算热图)等归因方法生成的热图,更好地预测了DenseNet-169的灵敏度。
当然,DNN并不完全类似于特征包模型,但确实显示出一些偏差。特别是,我们发现网络越深入,功能越来越大,远程依赖性也越来越大。
因此,更深层的神经网络确实改进了更简单的特征包模型,但我认为核心分类策略并没有真正改变。
解释CNN几个奇怪的现象
将CNN的决策视为一种BoF策略,可以解释有关CNN的几个奇怪的观察。首先,它将解释为什么CNN具有如此强烈的纹理偏差;其次,它可以解释为什么CNN对图像部分的混乱如此不敏感;甚至可以解释一般的对抗性贴纸和对抗性扰动的存在,比如人们在图像中的任何地方放置误导信号,并且无论这些信号是否适合图像的其余部分,CNN仍然可以可靠地接收信号。
我们的成果显示,CNN利用自然图像中存在的许多弱统计规律进行分类,并且不会像人类一样跳向图像部分的对象级整合。其他任务和感官方式也是如此。
我们必须认真思考如何构建架构、任务和学习方法,以抵消这种弱统计相关性的趋势。一种方式,是将CNN的归纳偏差从小的局部特征改善为更全局的特征;另一种方式,是删除、或替换网络不应该依赖的那些特征。
然而,最大的问题之一当然是图像分类本身的任务:如果局部图像特征足以解决任务,也就不需要去学习自然界的真实“物理学”,这样我们就必须重构任务,推着模型去学习对象的物理本质。
这样就很可能需要跳出纯粹只通过观察学习,获得输入和输出特征之间相关性的方式,以便允许模型提取因果依赖性。
总结
总之,我们的结果表明CNN可能遵循极其简单的分类策略。科学家认为这个发现可能在2019继续成为关注的焦点,凸显了我们对深度神经网络的内部运作了解甚少。
缺乏理解使我们无法从根本上发展出更好的模型和架构,来缩小人与机器之间的差距。深化我们的理解,将使我们能够找到弥合这一差距的方法。
这将带来异常丰厚的回报:当我们试图将CNN偏向物体的更多物理特性时,我们突然达到了接近人类的噪声稳健性。
我们继续期待在2019年,在这一领域上会出现更多令人兴奋的结果,获得真正了解了真实世界中,物理和因果性质的卷积神经网络。
神经网络新发现:其实CNN的图像分类策略远比我们想象的简单!http://t.bytedance.com/YAC2dB/



