教程:用两种方法完成无人驾驶中的识别、跟踪车道
点击上方关注,All in AI中国
Waymo的自驾车出租车服务本月刚刚上路,但自动驾驶汽车究竟是如何运作的呢?在道路上绘制的线条向人类驾驶员指示车道所在的位置,并且相应地指导车辆引导车辆的方向以及车辆代理如何在道路上和谐地交互。同样,识别和跟踪车道的能力是开发无人驾驶车辆算法的基础。
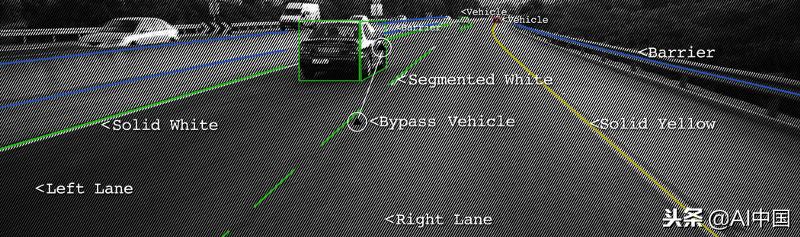
在本教程中,我们将学习如何使用计算机视觉技术构建用于跟踪道路通道的软件管道。我们将通过两种不同的方法来完成这项任务。
目录:
- 方法1:霍夫变换
- 方法2:空间CNN
方法1:霍夫变换
大多数车道设计得相对简单,不仅鼓励有序,而且使人类驾驶员更容易以一致的速度驾驶车辆。因此,我们的直观方法可能是首先通过边缘检测和特征提取技术检测相机馈送中的突出直线。我们将使用OpenCV,一个计算机视觉算法的开源库来实现。下图是我们的概述。

在开始之前,这是我们结果的演示:
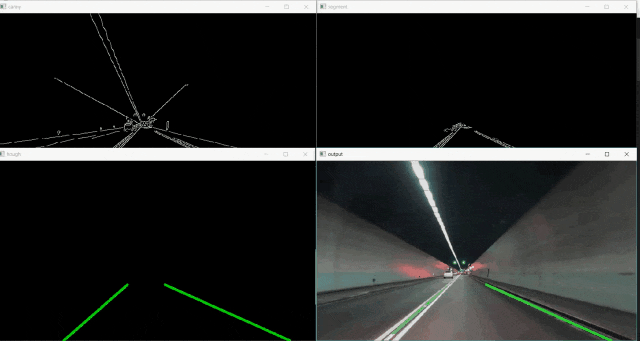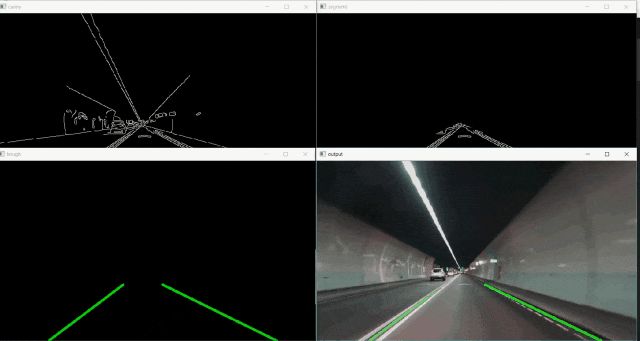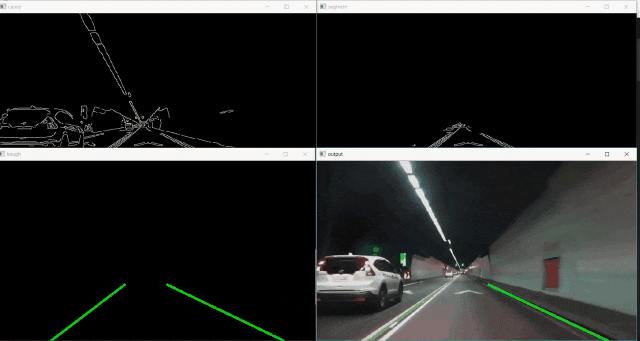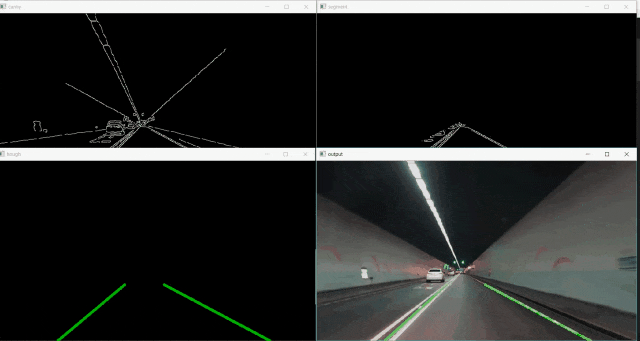
1.设置环境
如果您还没有安装OpenCV,请打开终端并运行:

现在,通过运行以下命令克隆教程存储库:

接下来,使用文本编辑器打开detector.py。我们将在此Python文件中编写本节的所有代码。
2.处理视频
我们将以10毫秒的间隔将我们的样本视频作为一系列连续帧(图像)提供给车道检测。我们也可以通过按“q”键随时退出程序。
3.应用Canny Detector
Canny Detector是一种针对快速实时边缘检测而优化的多阶段算法。该算法的基本目标是检测亮度(大梯度)的急剧变化,例如从白色到黑色的转换,并在给定一组阈值的情况下将它们定义为边缘。Canny算法有四个主要阶段:
A.降噪
与所有边缘检测算法一样,噪声是一个至关重要的问题,通常会导致错误检测。应用5×5高斯滤波器对图像进行卷积(平滑)以降低检测器对噪声的敏感度。这是通过使用正常分布数字的内核(在这种情况下,5×5内核)在整个图像上运行来完成的,将每个像素值设置为等于其相邻像素的加权平均值。
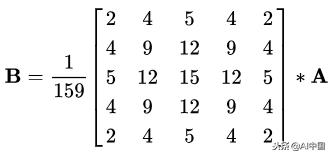
5×5高斯内核,星号表示卷积运算
B.强度梯度
然后沿着x轴和y轴使用Sobel、Roberts或Prewitt内核(Sobel在OpenCV中使用)来应用平滑图像以检测边缘是水平的、垂直的还是对角线的。
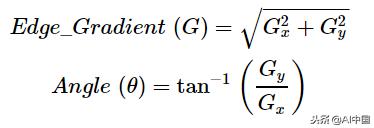
Sobel核用于计算水平和垂直方向的一阶导数
C.非极大值抑制
非极大值抑制应用于“薄”并有效锐化边缘。对于每个像素,如果它是先前计算的梯度方向上的局部最大值,则检查该值。
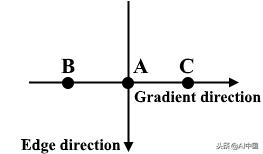
三点非极大值抑制
A位于边缘,具有垂直方向。由于梯度垂直于边缘方向,因此将B和C的像素值与A的像素值进行比较,以确定A是否是局部最大值。如果A是局部最大值,则测试下一个点的非最大抑制。否则,A的像素值被设置为零,并且A被抑制。
D.滞后阈值
在非极大值抑制之后,确认强像素位于边缘的最终映射中。但是,应进一步分析弱像素以确定其是否构成边缘或噪声。应用两个预定义的minVal和maxVal阈值,我们设置强度梯度高于maxVal的任何像素都是边缘,任何强度梯度低于minVal的像素设为边缘并丢弃。在minVal和maxVal之间有强度梯度的像素只有连接到maxVal以上有强度梯度的像素时才被认为是边缘。
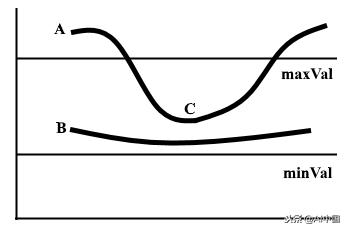
两行的滞后阈值示例
边缘A高于maxVal,因此被视为边缘。边缘B位于maxVal和minVal之间,但未连接到maxVal上方的任何边缘,因此被丢弃。边C位于maxVal和minVal之间,并连接到边缘A,即maxVal上方的边,因此被视为边。
对于我们的管道,我们的框架首先是灰度级的,因为我们只需要亮度通道来检测边缘,并且应用一个5乘5高斯模糊来减少噪声以减少假边缘。
4.分割车道区域
我们将手工制作一个三角形蒙版来划分车道区域,并丢弃框架中不相关的区域,以提高后期阶段的效率。
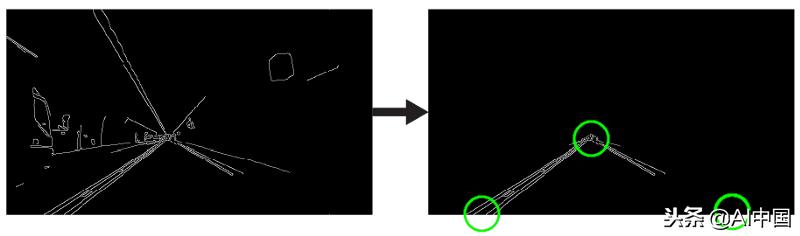
三角形蒙版将由三个坐标定义,由绿色圆圈表示

5.霍夫变换
在笛卡尔坐标系中,我们可以通过绘制y对x来表示y = mx + b的直线。但是,我们也可以通过绘制b对m来将此线表示为霍夫空间中的单个点。例如,具有等式y = 2x + 1的线可以在霍夫空间中表示为(2,1)。
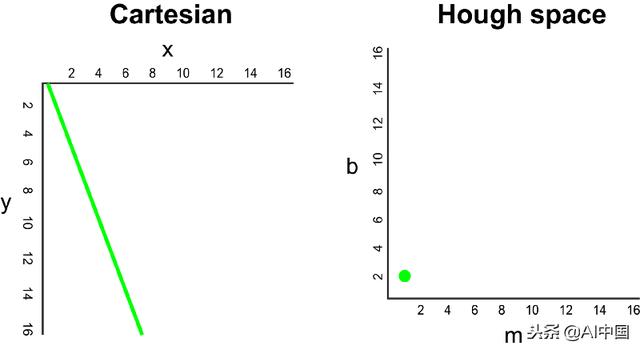
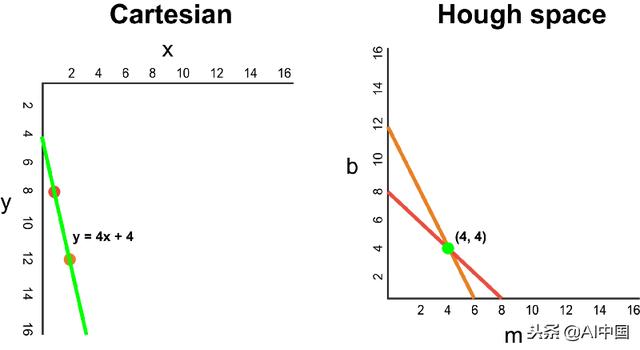
现在,如果不是一条线,我们必须在笛卡尔坐标系中绘制一个点。有许多可能的线可以通过这一点,每条线具有不同的参数m和b值。例如,(2,12)处的点可以通过y = 2x + 8,y = 3x + 6,y = 4x + 4,y = 5x + 2,y = 6x,依此类推。这些可能的线可以在霍夫空间中绘制为(2,8),(3,6),(4,4),(5,2),(6,0)。请注意,这会在霍夫空间中针对b坐标生成一条m行。
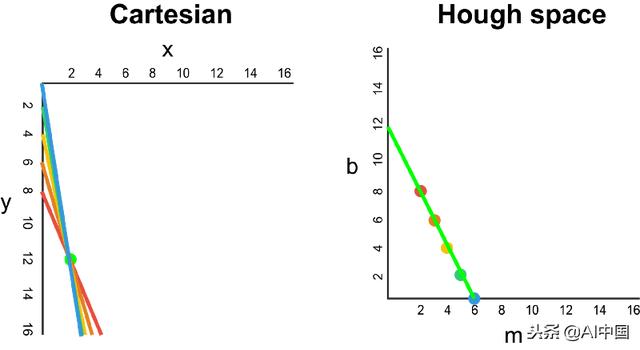
每当我们在笛卡尔坐标系中看到一系列点,并且知道这些点通过某条线连接时,我们可以通过首先将笛卡尔坐标系中的每个点绘制到霍夫空间中的相应线来找到该线的方程,然后找到霍夫空间的交点。霍夫空间中的交点表示贯穿系列中所有点的m和b值。
由于通过Canny Detector的帧可以简单地解释为表示图像空间中边缘的一系列白点,我们可以应用相同的技术来识别哪些点连接到同一条线,以及它们是否连接它的等式是什么,以便我们可以在我们的框架上绘制这条线。
为了简化说明,我们使用笛卡尔坐标来对应霍夫空间。然而,这种方法存在一个数学缺陷:当线是垂直的时,梯度是无穷大的,不能在霍夫空间中表示。要解决此问题,我们将使用Polar坐标。除了在Hough空间中绘制m对b之外,该过程仍然是相同的,我们将对θ绘制r。
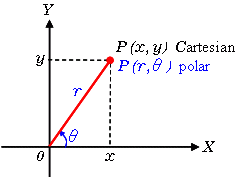
例如,对于极坐标系上x = 8和y = 6,x = 4和y = 9,x = 12和y = 3的点,我们可以绘制相应的霍夫空间。
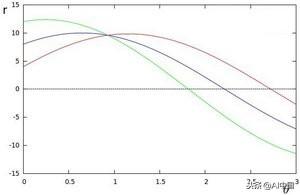
我们看到霍夫空间中的线在θ= 0.925和r = 9.6处相交。由于极坐标系中的线由r =xcosθ+ysinθ给出,我们可以诱导穿过所有这些点的单条线被定义为9.6 = xcos0.925 + ysin0.925。
通常,在霍夫空间中相交的曲线越多意味着由该交点表示的线对应于更多的点。对于我们的实现,我们将在霍夫空间中定义最小阈值交叉点数以检测线。因此,霍夫变换基本上跟踪帧中每个点的霍夫空间交叉点。如果交叉点的数量超过定义的阈值,我们将识别具有相应θ和r参数的线。
我们应用霍夫变换来识别两条直线- 这将是我们的左右车道边界

6.可视化
该通道可视化为两个浅绿色,线性拟合的多项式,它们将叠加在我们的输入框架上。
现在,打开终端并运行python detector.py来测试你的简单车道探测器!如果您遗漏了任何代码,以下是带注释的完整解决方案:
方法2:空间CNN
方法1中这种相当手工制作的传统方法似乎运行良好……至少对于清晰的直道而言。然而,很明显这种方法会在弯曲的车道或急转弯时立即破裂。此外,我们注意到在车道上存在由直线组成的标记,例如绘制的箭头标记,可能会不时地混淆车道探测器,这从演示渲染中的毛刺中可以看出。克服这种情况的一种方法可以是将三角形蒙版进一步细化为两个单独的、更精确的蒙版。尽管如此,这些相当随意的参数根本无法适应各种变化的道路环境。另一个缺点是,由于没有满足霍夫变换阈值的连续直线,所以车道检测器也会忽略带有点状标记或根本没有明显标记的车道。最后,影响线路可见度的天气和照明条件也可能是一个问题。
1.架构
虽然卷积神经网络(CNN)已被证明是有效的架构,既可以识别较低层图像的简单特征(例如边缘,颜色渐变),也可以识别更深层次的复杂特征和实体(例如物体识别),但它们往往很难表示这些特征和实体的“姿势” – 也就是说,CNN非常适合从原始像素中提取语义,但在捕获帧中像素的空间关系(例如旋转和平移关系)方面表现不佳。然而,这些空间关系对于形状先验强而外观相干性弱的车道检测任务是非常重要的。
例如,仅通过提取语义特征很难确定交通极点,因为它们缺乏明显且连贯的外观线索并且经常被遮挡。
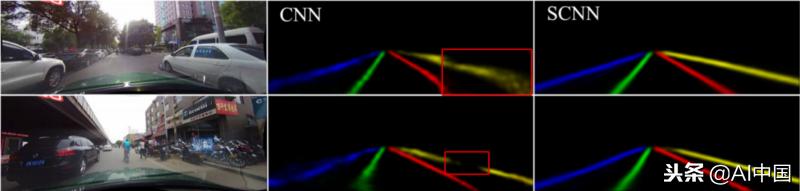
左上角图像右侧的汽车和左下角图像右侧的摩托车遮挡右侧车道标记,对CNN结果产生负面影响。
然而,由于我们知道交通杆通常表现出类似的空间关系,例如垂直站立并且放置在道路的左右两侧,我们看到了加强空间信息的重要性。类似的情况如下用于检测车道。
为了解决这个问题,Spatial CNN(SCNN)提出了一种架构,该架构“将传统的深层逐层卷积推广到特征映射中的逐片卷积”。这是什么意思?在传统的逐层CNN中,每个卷积层接收来自其前一层的输入,应用卷积和非线性激活,并将输出发送到后续层。SCNN通过将各个特征映射行和列视为“层”进一步采取这一步骤,顺序地应用相同的过程(其中顺序意味着切片仅在从前面的切片接收到信息之后才将信息传递给后续切片),允许在同一层内的神经元之间传递像素信息,有效地增加对空间信息的强调。
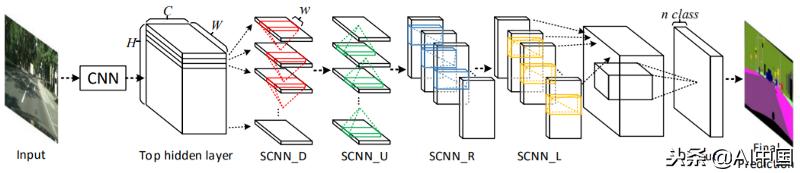
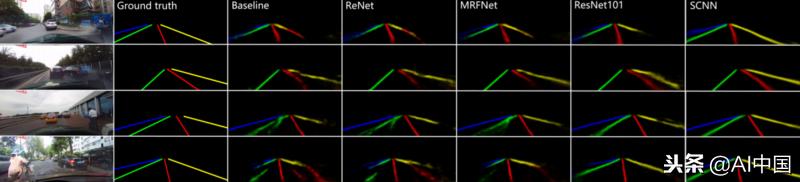
SCNN是相对较新的,仅在今年早些时候(2018年)发布,但已经超越了ReNet(RNN),MRFNet(MRF + CNN)等更深层次的ResNet架构,并以96.53%的准确率在TuSimple基准车道检测挑战中排名第一。
此外,除了SCNN的出版,作者还发布了CULane Dataset,这是一个带有立方体刺的交通车道注释的大型数据集。CULane数据集还包含许多具有挑战性的场景,包括遮挡和不同的照明条件。

2.模型
车道检测需要精确的像素识别和车道曲线预测。SCNN的作者将蓝色、绿色、红色和黄色车道标记视为四个单独的类别,而不是直接训练车道存在性,然后进行聚类。该模型输出每条曲线的概率图(probmaps),类似于语义分割任务,然后通过一个小网络传递probmaps来预测最终的cubic spines。该模型基于DeepLab-LargeFOV模型变体。
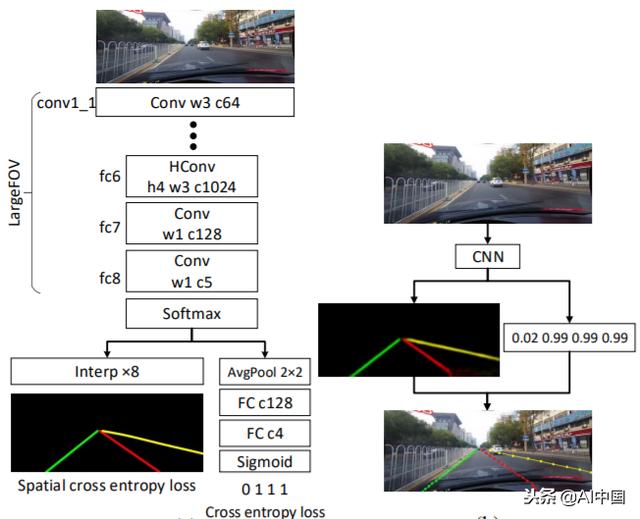
对于具有超过0.5存在值的每个车道标记,对应具有最高响应的位置以20行间隔搜索对应的概率映射。为了确定是否检测到车道标记,计算地面实况(正确标签)和预测之间的联合交叉(IoU),其中高于设定阈值的IoU被评估为真实正(TP)的正样本以计算精度和召回。
3.测试和训练
您可以按照此存储库在SCNN文件中重现结果,或使用CULane数据集测试您自己的模型。
就是这样!希望本教程可以向您展示如何使用传统方法构建一个简单的车道探测器,该方法涉及许多手工制作的特性和微调,并且还向您介绍了一种替代方法,该方法遵循最近解决任何类型的计算机视觉问题:你可以添加一个卷积神经网络!

教程:用两种方法完成无人驾驶中的识别、跟踪车道http://t.jinritoutiao.js.cn/89omxY/
转载请注明:徐自远的乱七八糟小站 » 教程:用两种方法完成无人驾驶中的识别、跟踪车道



