从零开始编写任意机器学习算法的6个步骤:关于感知器案例的研究
点击上方关注,All in AI中国
作者——John Sullivan
写一个机器学习算法是一次非常有意义的学习经历(https://www.dataoptimal.com/machine-learning-from-scratch/)。
它为你提供了”啊哈!原来是这样”的经历感受。只有你点击它的时候,你才会明白究竟发生了什么。
有些算法比其他算法复杂,所以我们从一些简单的开始,例如单层感知器(https://en.wikipedia.org/wiki/Perceptron)。
我将向你介绍以下6步过程,从零开始编写算法,使用感知器作为案例研究:
1.对算法有基本的了解
2.寻找不同的学习来源
3.将算法分解为块
4.从一个简单的例子开始
5.使用确信的案例进行验证
6.写下你探索的过程
基本了解
这可以追溯到我最初所说的。如果你不了解基本知识,就不要从头开始处理算法。
至少,你应该能够回答以下问题:
它是什么?
它通常用于什么?
我什么时候不能用这个?
对于感知器,让我们继续回答以下问题:
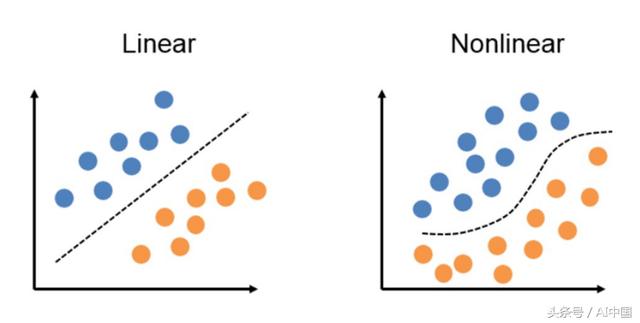
单层感知器是最基本的神经网络。它通常用于二进制分类问题(1或0,”是”或”否”)。
一些简单的用途可能是情绪分析(正面或负面反应)或贷款违约预测(“将违约”、”不会违约”)。对于这两种情况,决策边界都需要是线性的。
如果决策边界是非线性的,那么你不能使用(单层)感知器。对于非线性问题,你需要的是其他东西。
使用不同的学习来源
在你对模型有了基本的理解之后,就该开始做你的研究了。
有些人通过书本学得更好,有些人通过视频学得更好。
就我个人而言,我喜欢两者合用和使用各种资源。
关于数学细节,教科书做得很好(https://www.dataoptimal.com/data-science-books-2018/),但是对于更多的实际例子,我更喜欢博客文章和YouTube视频。
这里有一些很好的学习资源:
书籍方面
统计学习的要素(SEC)。4.5.1 链接:https://web.stanford.edu/~hastie/Papers/ESLII.pdf
理解机器学习:从理论到算法(SEC)。21.4 链接:https://www.cs.huji.ac.il/~shais/UnderstandingMachineLearning/understanding-machine-learning-theory-algorithms.pdf
博客
如何在Python中从无到有地实现感知器算法。作者:Jason Brownlee 链接:https://machinelearningmastery.com/implement-perceptron-algorithm-scratch-python/
单层神经网络与梯度下降。作者:Sebastian Raschka 链接:https://sebastianraschka.com/Articles/2015_singlelayer_neurons.html
视频
感知器训练(https://www.youtube.com/watch?v=5g0TPrxKK6o)。
感知器算法的工作原理(https://www.youtube.com/watch?v=1XkjVl-j8MM)。
将算法分解为块
既然我们已经收集了我们的资料,现在是开始学习的时候了。
与其一路上阅读文章或博客,不如从浏览章节标题和其他重要信息开始。
然后写下要点,并试图勾勒出算法。
在查看了众多资料后,我将感知器算法分解为以下5块:
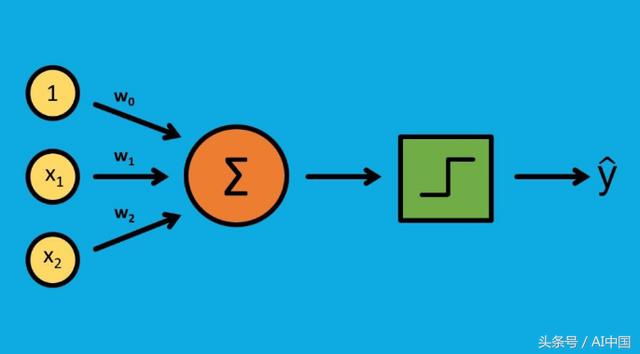
1.初始化权重
2.按输入乘以权重,并将它们加起来
3.将结果与阈值进行比较以计算输出(1或0)
4.更新权重
5.重复
让我们把每一个细节都看一遍。
1.初始化权重
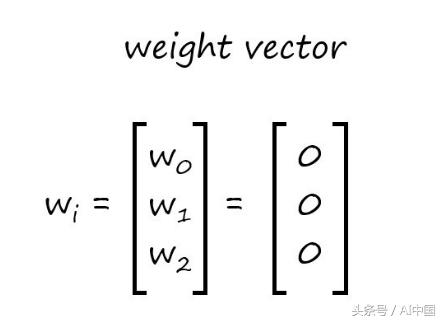
首先,我们将初始化权重向量。
权重的数量需要与特征的数量相匹配。假设我们有三个特性,下面是权重向量的样子
权重向量通常是用零初始化,所以我将继续在这个例子中坚持我的理念。
2.将权值乘以输入,并将它们加起来。
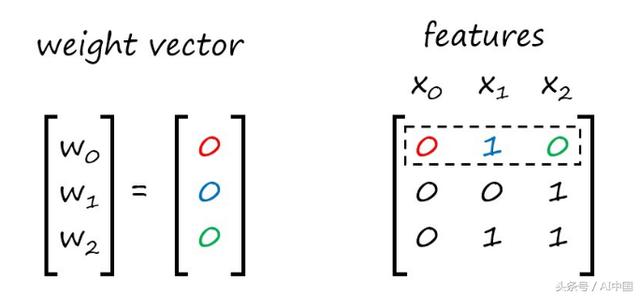
接下来,我们将把权重乘以输入,然后把它们加起来。
为了便于跟踪,我在第一行中对权重和它们的相应特性进行了着色。
在我们把权重乘以特征后,我们把它们加起来。这也被称为点积。
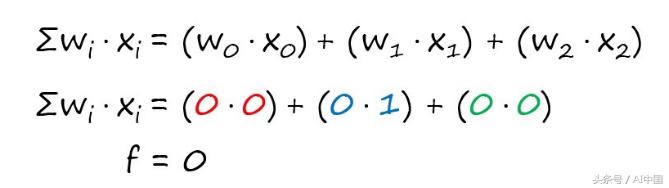
最终结果是0。我将这个临时结果称为”f”。
3.与阈值比较
在计算了点积之后,我们需要将它与阈值进行比较。
我选择了使用0作为我的阈值,但是你可以使用这个,或尝试一些不同的数字。
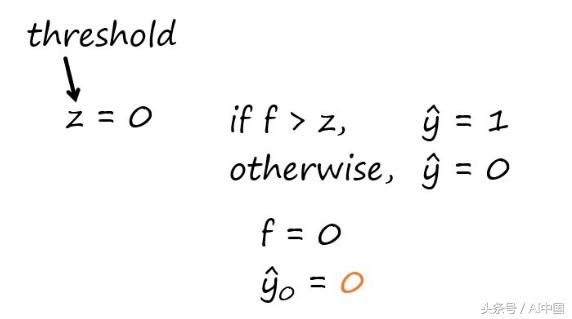
由于我们计算的点积”f”不大于我们的阈值(0),所以我们的估计等于零。
我将估计值表示为”y hat”,带有0下标,以对应于第一行。你可以用1代替第一行,但这并不重要。我只是选择从0开始。
如果我们将这一结果与实际值进行比较,我们可以看到,我们当前的权重并没有做出正确的预测。
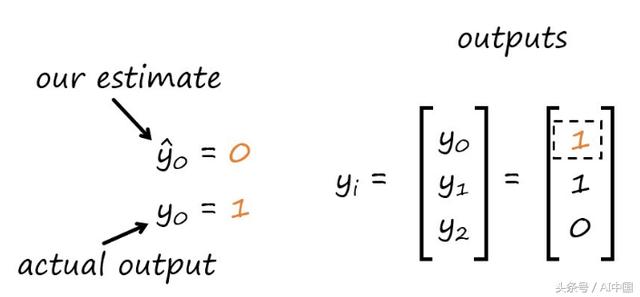
由于我们的预测是错误的,我们需要更新权重,这就把我们带到了下一步。
4.更新权重
接下来,我们将更新权重。下面是我们将要使用的公式:
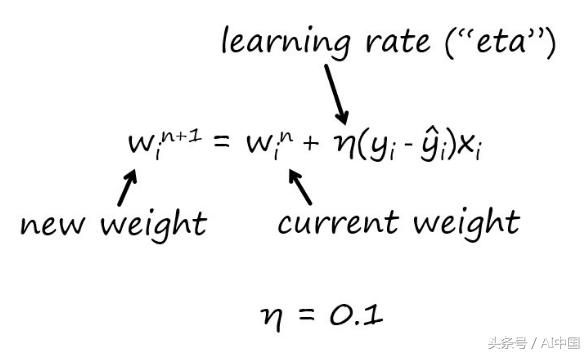
基本思想是在迭代”n”时调整当前的权重,以便在下一次迭代中使用新的权重,”n+1″。
为了调整权重,我们需要设定一个”学习速率”。这是用希腊字母”ETA”表示的。
我选择使用0.1作为学习速率,但是你可以使用不同的数字,就像阈值一样。
以下是我们到目前为止所做的简要总结:
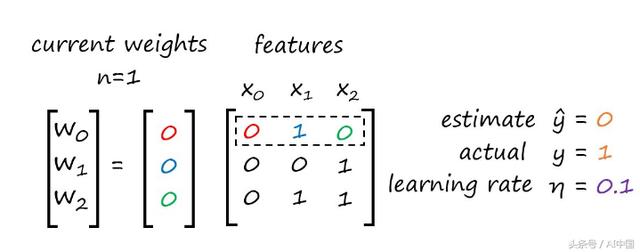
现在让我们继续计算迭代n=2的新权重。

我们成功地完成了感知器算法的第一次迭代。
5.重复
因为我们的算法没有计算出正确的输出,所以我们需要继续下去。
通常,我们需要多次迭代。循环遍历数据集中的每一行,我们将每次更新权重。
一个完整的扫描数据集被称为”epoch”(轮回)。
因为我们的数据集有3行,所以我们需要三次迭代才能完成一个”epoch”。
我们可以设置总迭代次数或时间来继续执行该算法。也许我们需要指定30次迭代(或10次迭代)。
与阈值和学习速率一样,epoch数(即轮回数)是你可以使用的参数。
在下一次迭代中,我们继续讨论第二行的特性。
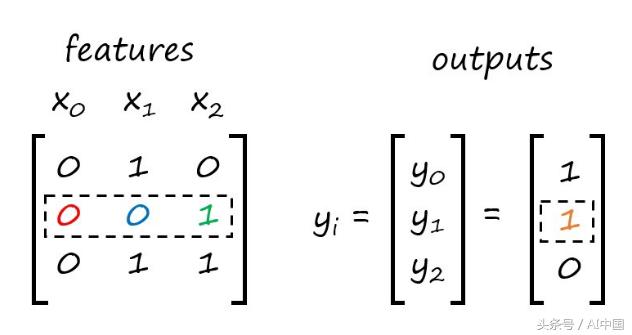
我不会重复每一步,但下面是点积的新计算:
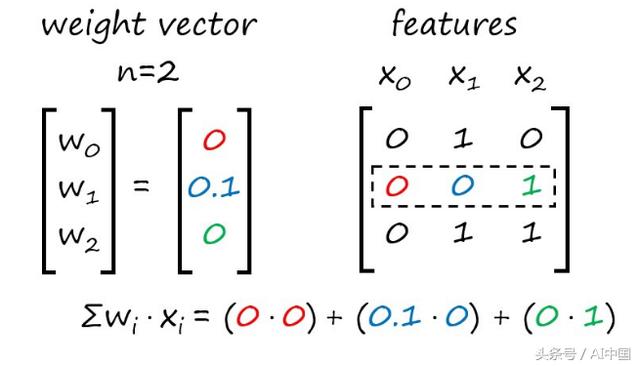
接下来,我们将点积与阈值进行比较,以计算一个新的估计值,更新权重,然后继续进行。如果我们的数据是线性可分的,感知器就会收敛。
从一个简单的例子开始
现在我们已经手工将算法分解成块,现在是开始在代码中实现它的时候了。
为了保持简单,我总是喜欢从一个非常小的数据集开始。
这类问题的一个很好的、小的、线性可分离的数据集是NAND gate(https://en.wikipedia.org/wiki/NAND_gate)。这是数字电子学中常用的一个数据集。
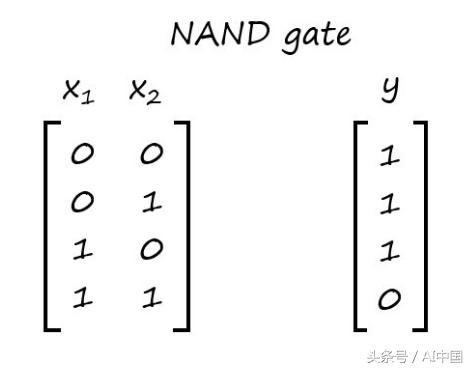
由于这是一个相当小的数据集,我们只需手动将其输入Python。
我将添加一个虚拟特性”X0″,这是一个1的列。我这样做是为了让我们的模型计算偏置项。
你可以将偏差看作是截取项,它正确地允许我们的模型分离这两个类。
以下是输入数据的代码:


与上一节一样,我将以块的形式逐步完成算法,编写代码,并在我们进行测试时对其进行测试。
1.初始化权重
第一步是初始化权重。

请记住,权重向量的长度需要匹配特征的数量。对于这个NAND gate例子,长度是3。
2.将权值乘以输入,并将它们加起来。
接下来,我们将把权重乘以输入,然后把它们加起来。
它的另一个名字是”点积”。
同样,我们可以使用Numpy轻松地执行此操作。我们将使用的方法是.dot()。
让我们从权向量和第一行特征的点积开始。

正如预期的那样,结果是0。
为了与前文保持一致,我将点积赋给变量f。
3.与阈值比较
在计算了点积之后,我们准备将结果与阈值进行比较,从而对输出进行预测。
同样,我将保持与前文一致。
我要让临界值z等于0。如果点积f大于0,我们的预测是1。否则,它就是0。
记住,这个预测通常是用”carat”的顶部来表示的,也被称为”hat”。我将预测赋给的变量是”yhat”。

正如预期的那样,预测为0。
你会注意到,在上面的注释中,我称之为”激活函数”。这是对我们正在做的事情的更正式的描述。
查看NAND输出的第一行,我们可以看到实际值为1。既然我们的预测是错误的,我们就需要继续更新权重。
4.更新权重
既然我们已经做出了预测,我们就可以更新权重了。
我们需要设定一个学习速率才能做到这一点。为了与前面的示例保持一致,我将为学习率”ETA”赋值0.1。
我将对每个权重的更新进行编码,以便更容易阅读。


我们可以看到,我们的权重现在已经更新,所以我们准备继续前进。
5.重复
现在我们已经完成了每一步,现在是时候把所有的东西都放在一起了。
我们还没有讨论的最后一个部分是损失函数。这是我们试图最小化的函数,在我们的例子中,这将是平方和的错误。
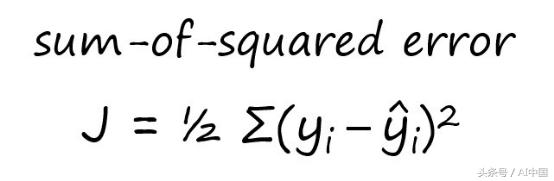
这就是我们用来计算错误的地方,看看模型是如何运行的。
将所有内容结合在一起,下面是整个函数的样子:







现在我们已经编写了完整的感知器,让我们继续运行它:




看一看错误,我们可以看到,在第6次迭代时,错误变为0。对于其余的迭代,它保持在0。
当误差达到0并停留在那里时,我们知道我们的模型已经收敛了。这告诉我们,我们的模型已经正确地”学习”了适当的权重。
在下一节中,我们将在更大的数据上使用计算的权重做预测。
使用确信的案例进行验证
到目前为止,我们已经找到了不同的学习资源,手工完成了算法,并用一个简单的例子在代码中测试了它。
现在是时候将我们的结果与可信的实现进行比较了。为了比较,我们将使用scikit-learn中的感知器(http://scikit-learn.org/stable/modules/generated/sklearn.linear_model.Perceptron.html)。
我们将使用以下步骤完成此比较:
1.导入数据
2.将数据分割成训练/测试组
3.训练我们的感知器
4.测试感知器
5.与scikit-learn中的感知器进行比较
1.导入数据
让我们从导入数据开始。你可以获得数据集链接为:https://github.com/dataoptimal/posts/blob/master/algorithms%20from%20scratch/dataset.csv 。
这是一个线性可分离的数据集,我创建它是为了确保感知器能够工作。为了进一步的工作,让我们继续绘制数据。

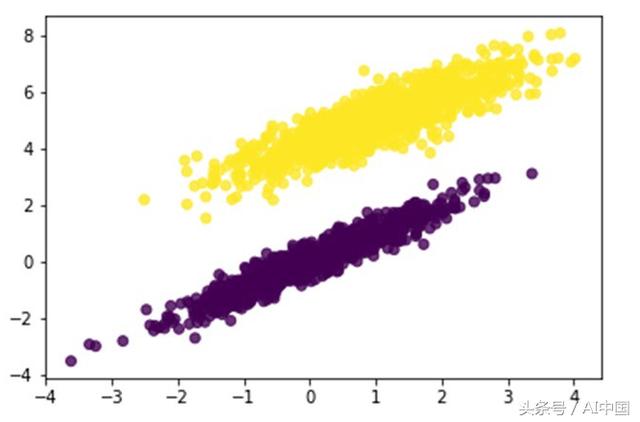
看一下这幅图,很容易看出我们可以用一条直线将这些数据分开。
在我们继续之前,我将解释我上面的代码。
我使用Pandas导入CSV,CSV自动将数据放入dataframe中。
要绘制数据,我必须从dataframe中提取值,这就是为什么我使用”.values”方法。
特性在第1和第2列中,所以我在散点图函数中使用了这些特性。第0列是我包含的1的虚拟特性,这样就能计算出截距。这与我们在上文中对NAND gate所做的事情一样。
最后,我使用C=df[‘3’],alpha=0.8在散射图函数中。输出是第3列(0或1)中的数据,因此我”告诉”函数使用’3’列对这两个类进行着色。
如果你想找到更多关于Matplotlib的散点图函数,请点击:https://matplotlib.org/api/_as_gen/matplotlib.pyplot.scatter.html 。
2.将数据分割成训练/测试组
现在,我们已经确认数据可以线性分离,是时候将数据拆分了。
在一个独立的数据集上训练一个模型,而不是你测试的数据集,这是一个很好的实践。这有助于避免过度拟合。
做这件事有不同的方法,但是为了保持简单,我只使用一个训练集和一个测试集。
我将从整理我的数据开始。如果你查看原始文件,你将看到数据按行分组,输出为0(第三列),然后是所有的1。我想要改变事物,增加一些随机性,所以我现在要打乱数据。

我首先将数据从dataframe更改为numpy数组。这使我将要使用的许多numpy函数更容易使用,例如.shuffle(即打乱或洗牌)。
为了使结果可重复,我设置了一个随机数种子(5)。在我们完成之后,尝试改变随机数种子,看看结果是如何变化的。
接下来,我将70%的数据分成训练集,30%的数据分成测试集。

最后一步是分离训练和测试集的特性和输出。

为了这个例子,我选择了70%的训练集和30%的测试集,但我鼓励你研究其他方法,例如K折交叉验证(https://en.wikipedia.org/wiki/Cross-validation_%28statistics%29)。
3.训练我们的感知器
接下来,我们将训练我们的感知器。
这很简单,我们将重用我们在前文构建的代码。







让我们继续看一看权重与平方误差之和。
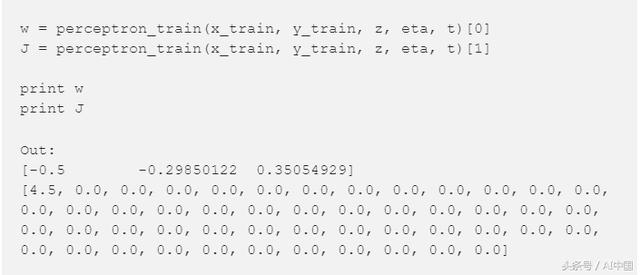
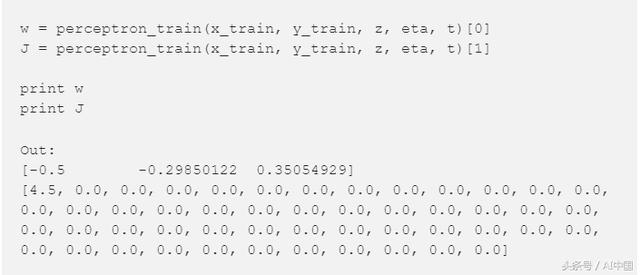
现在这些权值对我们来说并不重要,但是我们将在后面使用这些数字来测试我们的感知器。我们还将使用它将我们的模型与scikit-learn模型进行比较。
看一下平方误差之和,我们可以看到我们的感知器已经收敛了,这是我们所期望的,因为数据是线性可分的。
4.测试我们的感知器
现在是时候测试我们的感知器了。为了做到这一点,我们将建造一个小的感知器测试函数。
这和我们已经看到的很相似。这个函数取我们使用perceptron_train函数计算的权值的点积,以及特征,以及激活函数,来进行预测。
我们唯一没有看到的是accuracy_score。这是一个来自scikit-learn的评价度量函数。你可以在这里了解更多。
把所有这些放在一起,下面是代码:



得分为1.0表明我们的模型正确地预测了所有的测试数据。这个数据集显然是可分离的,所以我们期望这个结果。
5.与scikit-learn感知器相比
最后一步是将我们的结果与scikit-learn的感知器进行比较。下面是这个模型的代码:

现在我们已经训练了模型,让我们比较权重和我们的模型计算的权重。
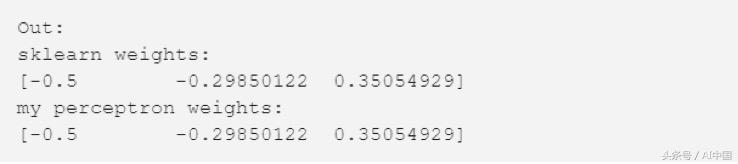
scikit-learn模型中的权重与我们的相同。这意味着我们的模型工作正常,这是个好消息。
在我们结束之前,有几个小问题需要复习一下。在scikit-learn模型中,我们必须将随机状态设置为”None”并关闭洗牌。因为我们已经设置了一个随机数种子并打乱了数据,所以我们不需要再这样做了。
我们还必须将学习速率”eta0″设置为0.1,以与我们的模型相同。
最后一点是截距。因为我们已经包含了一个虚拟的特性列1s,我们正在自动拟合截距,所以我们不需要在scikit-learn感知器中打开它。
这些看起来都是次要的细节,但如果我们不设置这些,我们就无法复制与我们的模型相同的结果。
这一点很重要。在使用模型之前,阅读文档并理解所有不同设置的作用是非常重要的。
写下你的过程
这个过程中的最后一步可能是最重要的。
你已经完成了所有的工作,包括学习、记笔记、从头开始编写算法,并将其与确信的案例进行比较。不要让前期准备白白浪费掉!
写下这个过程很重要,原因有二:
1.你会得到更深的理解,因为你正在教导别人你刚刚学到的东西。
2.你可以向潜在雇主展示它。
证明的天赋与能力,但如果你可以自己从头实现它,那就更令人印象深刻了。
一个展示你作品的好方法是使用GitHub页面组合(https://www.youtube.com/watch?v=qWrcgHwSG8M)。
结语
在这篇文章中,我们学习了如何实现从零开始编写机器学习算法(https://www.dataoptimal.com/machine-learning-from-scratch/)。
更重要的是,我们学会了如何找到有用的学习资源,以及如何将算法分解成块。
然后,我们学习了如何使用较小数据集在代码中训练和测试算法。
最后,我们将模型的结果与可信的案例进行了比较。
这是一个很好的方法,我们可以在更深层次上了解、学习算法,这样你就可以自己实现它。
大多数情况下,你使用的算法都是准确无误的,但是如果你真的想更深入地了解幕后的情况,从头开始学习它是一个很好的练习!
从零开始编写任意机器学习算法的6个步骤:关于感知器案例的研究http://t.jinritoutiao.js.cn/RGY7Mv/



