谷歌终于开源BERT代码:3 亿参数量,机器之心全面解读
机器之心原创,参与:思源、路、晓坤。
最近谷歌发布了基于双向 Transformer 的大规模预训练语言模型,该预训练模型能高效抽取文本信息并应用于各种 NLP 任务,该研究凭借预训练模型刷新了 11 项 NLP 任务的当前最优性能记录。如果这种预训练方式能经得起实践的检验,那么各种 NLP 任务只需要少量数据进行微调就能实现非常好的效果,BERT 也将成为一种名副其实的骨干网络。
今日,谷歌终于放出官方代码和预训练模型,包括 BERT 模型的 TensorFlow 实现、BERT-Base 和 BERT-Large 预训练模型和论文中重要实验的 TensorFlow 代码。在本文中,机器之心首先会介绍 BERT 的直观概念、业界大牛对它的看法以及官方预训练模型的特点,并在后面一部分具体解读 BERT 的研究论文与实现,整篇文章的主要结构如下所示:
1 简介
- 预训练 NLP 模型
- 计算力
- 研究团队
- 官方预训练模型
2 Transformer 概览
3 BERT 论文解读
- 输入表征
- 预训练过程
- 微调过程
4 官方模型详情
- 微调预训练 BERT
- 使用预训练 BERT 抽取语义特征
1 简介
BERT 的核心过程非常简洁,它会先从数据集抽取两个句子,其中第二句是第一句的下一句的概率是 50%,这样就能学习句子之间的关系。其次随机去除两个句子中的一些词,并要求模型预测这些词是什么,这样就能学习句子内部的关系。最后再将经过处理的句子传入大型 Transformer 模型,并通过两个损失函数同时学习上面两个目标就能完成训练。
业界广泛认为谷歌新提出来的 BERT 预训练模型主要在三方面会启发今后的研究,即对预训练 NLP 模型的贡献、计算力对研究的重要性、以及研究团队和工程能力。
预训练 NLP 模型
其实预训练模型或迁移学习很早就有人研究,但真正广受关注还是在近几年。清华大学刘知远表示:「大概在前几年,可能很多人都认为预训练的意义不是特别大,当时感觉直接在特定任务上做训练可能效果会更好。我认为 BERT 相当于在改变大家的观念,即在极大数据集上进行预训练对于不同的 NLP 任务都会有帮助。」
虽然 CV 领域的预训练模型展现出强大的能力,但 NLP 领域也一直探讨实现无监督预训练的方法,复旦大学邱锡鹏说:「其实早在 16 年的时候,我们在知乎上讨论过 NLP 的发展方向。我记得当初回答 NLP 有两个问题,其中第一个就是怎么充分挖掘无标注数据,而 BERT 这篇论文提供了两个很好的方向来挖掘无标注数据的潜力。虽然这两个方法本身并不新颖,但它相当于做得非常极致。另外一个问题是 Transformer,它当时在机器翻译中已经展示出非常强的能力,其实越大的数据量就越能显示出这个结构的优点,因为它可以叠加非常深的层级。」
深度好奇创始人兼 CTO 吕正东博士最后总结道:「通用的 composition architecture + 大量数据 + 好的 unsupervised 损失函数,带来的好的 sentence model, 可以走很远。它的架构以及它作为 pre-trained model 的使用方式,都非常类似视觉领域的好的深度分类模型,如 AlexNet 和 Residual Net。」
计算力
尽管 BERT 效果惊人,但它需要的计算量非常大,原作者在论文中也表示每次只能预测 15% 的词,因此模型收敛得非常慢。BERT 的作者在 Reddit 上也表示预训练的计算量非常大,Jacob 说:「OpenAI 的 Transformer 有 12 层、768 个隐藏单元,他们使用 8 块 P100 在 8 亿词量的数据集上训练 40 个 Epoch 需要一个月,而 BERT-Large 模型有 24 层、2014 个隐藏单元,它们在有 33 亿词量的数据集上需要训练 40 个 Epoch,因此在 8 块 P100 上可能需要 1 年?16 Cloud TPU 已经是非常大的计算力了。」
吕正东表示:「BERT 是一个 google 风格的暴力模型,暴力模型的好处是验证概念上简单模型的有效性,从而粉碎大家对于奇技淫巧的迷恋; 但暴力模型通常出现的一个坏处是’there is no new physics’,我相信不少人对 BERT 都有那种『我也曾经多多少少想过类似的事情』的感觉,虽然也仅仅是想过而已。」
研究团队
最后对于 BERT 的研究团队,微软全球技术院士黄学东说:「包括一作 Jacob 在内,BERT 四个作者有三个是微软前员工。这个研究其实改变了自然语言处理今后的方向,他们的贡献应该和当年微软在计算机视觉中用 ResNet 所造就的贡献是一样的。可惜 Jacob 不是在我们团队做的,我们本来可以多一项光荣的任务。我非常喜欢 Jacob 的东西,他以前也是微软的优秀员工。」
BERT 官方预训练模型
在众多研究者的关注下,谷歌发布了 BERT 的实现代码与预训练模型。其中代码比较简单,基本上是标准的 Transformer 实现,但是发布的预训练模型非常重要,因为它需要的计算力太多。总体而言,谷歌开放了预训练的 BERT-Base 和 BERT-Large 模型,且每一种模型都有 Uncased 和 Cased 两种版本。
其中 Uncased 在使用 WordPiece 分词之前都转换为小写格式,并剔除所有 Accent Marker,而 Cased 会保留它们。项目作者表示一般使用 Uncased 模型就可以了,除非大小写对于任务很重要才会使用 Cased 版本。所有预训练模型及其地址如下:
- BERT-Base, Uncased:12-layer, 768-hidden, 12-heads, 110M parameters
- 地址:https://storage.googleapis.com/bert_models/2018_10_18/uncased_L-12_H-768_A-12.zip
- BERT-Large, Uncased:24-layer, 1024-hidden, 16-heads, 340M parameters
- 地址:https://storage.googleapis.com/bert_models/2018_10_18/uncased_L-24_H-1024_A-16.zip
- BERT-Base, Cased:12-layer, 768-hidden, 12-heads , 110M parameters
- 地址:https://storage.googleapis.com/bert_models/2018_10_18/cased_L-12_H-768_A-12.zip
- BERT-Large, Cased:24-layer, 1024-hidden, 16-heads, 340M parameters(目前无法使用,需要重新生成)。
每一个 ZIP 文件都包含了三部分,即保存预训练模型与权重的 ckpt 文件、将 WordPiece 映射到单词 id 的 vocab 文件,以及指定模型超参数的 json 文件。除此之外,谷歌还发布了原论文中将预训练模型应用于各种 NLP 任务的源代码,感兴趣的读者可以查看 GitHub 项目复现论文结果。
BERT 官方项目地址:https://github.com/google-research/bert
最后,这个项目可以在 CPU、GPU 和 TPU 上运行,但是在有 12GB 到 16GB 显存的 GPU 上,很可能模型会发生显存不足的问题。因此读者也可以在 Colab 先试着使用 BERT,如下展示了在 Colab 上使用免费 TPU 微调 BERT 的 Notebook:
BERT Colab 地址:https://colab.sandbox.google.com/github/tensorflow/tpu/blob/master/tools/colab/bert_finetuning_with_cloud_tpus.ipynb
2 Transformer 概览
在整个 Transformer 架构中,它只使用了注意力机制和全连接层来处理文本,因此 Transformer 确实没使用循环神经网络或卷积神经网络实现「特征抽取」这一功能。此外,Transformer 中最重要的就是自注意力机制,这种在序列内部执行 Attention 的方法可以视为搜索序列内部的隐藏关系,这种内部关系对于翻译以及序列任务的性能有显著提升。
如 Seq2Seq 一样,原版 Transformer 也采用了编码器-解码器框架,但它们会使用多个 Multi-Head Attention、前馈网络、层级归一化和残差连接等。下图从左到右展示了原论文所提出的 Transformer 架构、Multi-Head Attention 和点乘注意力。本文只简要介绍这三部分的基本概念与结构,更详细的 Transformer 解释与实现请查看机器之心的 GitHub 项目:基于注意力机制,机器之心带你理解与训练神经机器翻译系统 。
其中点乘注意力是注意力机制的一般表达形式,将多个点乘注意力叠加在一起可以组成 Transformer 中最重要的 Multi-Head Attention 模块,多个 Multi-Head Attention 模块堆叠在一起就组成了 Transformer 的主体结构,并借此抽取文本中的信息。
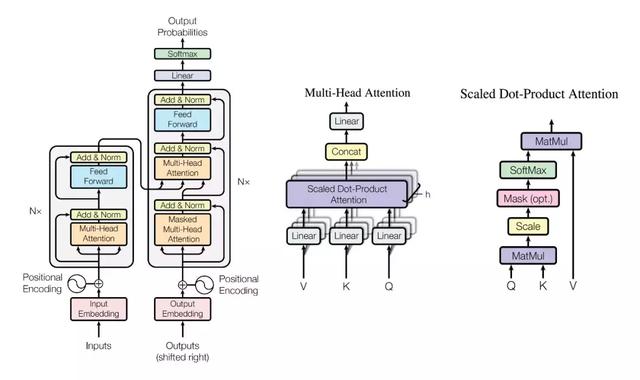
改编自论文《Attention is all your need》。
上图右边的点乘注意力其实就是标准 Seq2Seq 模型中的注意力机制。其中 Query 向量与 Value 向量在 NMT 中相当于目标语输入序列与源语输入序列,Query 与 Key 向量的点乘相当于余弦相似性,经过 SoftMax 函数后可得出一组归一化的概率。这些概率相当于给源语输入序列做加权平均,即表示在生成一个目标语单词时源语序列中哪些词是重要的。
上图中间的 Multi-head Attention 其实就是多个点乘注意力并行处理并将最后的结果拼接在一起。这种注意力允许模型联合关注不同位置的不同表征子空间信息,我们可以理解为在参数不共享的情况下,多次执行点乘注意力。
最后上图左侧为 Transformer 的整体架构。输入序列首先会转换为词嵌入向量,在与位置编码向量相加后可作为 Multi-Head 自注意力模块的输入,自注意力模块表示 Q、V、K 三个矩阵都是相同的。该模块的输出再经过一个全连接层就可以作为编码器模块的输出。
原版 Transformer 的解码器与编码器结构基本一致,只不过在根据前面译文预测当前译文时会用到编码器输出的原语信息。在 BERT 论文中,研究者表示他们只需要使用编码器抽取文本信息,因此相对于原版架构只需要使用编码器模块。
在模型架构上,BERT 使用了非常深的网络,原版 Transformer 只堆叠了 6 个编码器解码器模块,即上图的 N=6。而 BERT 基础模型使用了 12 个编码器模块(N=12),BERT 大模型堆叠了 24 个编码器模块(N=24)。其中堆叠了 6 个模块的 BERT 基础模型主要是为了和 OpenAI GPT 进行对比。
3 BERT 论文解读
BERT 的全称是基于 Transformer 的双向编码器表征,其中「双向」表示模型在处理某一个词时,它能同时利用前面的词和后面的词两部分信息。这种「双向」的来源在于 BERT 与传统语言模型不同,它不是在给定所有前面词的条件下预测最可能的当前词,而是随机遮掩一些词,并利用所有没被遮掩的词进行预测。下图展示了三种预训练模型,其中 BERT 和 ELMo 都使用双向信息,OpenAI GPT 使用单向信息。
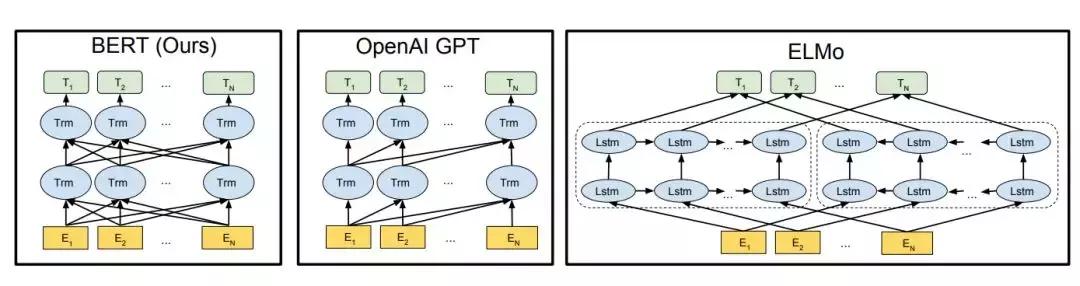
图:选自《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》。
如上所示为不同预训练模型的架构,BERT 可以视为结合了 OpenAI GPT 和 ELMo 优势的新模型。其中 ELMo 使用两条独立训练的 LSTM 获取双向信息,而 OpenAI GPT 使用新型的 Transformer 和经典语言模型只能获取单向信息。BERT 的主要目标是在 OpenAI GPT 的基础上对预训练任务做一些改进,以同时利用 Transformer 深度模型与双向信息的优势。
输入表征
前面已经了解过 BERT 最核心的过程就是同时预测加了 MASK 的缺失词与 A/B 句之间的二元关系,而这些首先都需要体现在模型的输入中,在 Jacob 等研究者的原论文中,有一张图很好地展示了模型输入的结构。

图:选自《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》。
如上所示,输入有 A 句「my dog is cute」和 B 句「he likes playing」这两个自然句,我们首先需要将每个单词及特殊符号都转化为词嵌入向量,因为神经网络只能进行数值计算。其中特殊符 [SEP] 是用于分割两个句子的符号,前面半句会加上分割编码 A,后半句会加上分割编码 B。
因为要建模句子之间的关系,BERT 有一个任务是预测 B 句是不是 A 句后面的一句话,而这个分类任务会借助 A/B 句最前面的特殊符 [CLS] 实现,该特殊符可以视为汇集了整个输入序列的表征。
最后的位置编码是 Transformer 架构本身决定的,因为基于完全注意力的方法并不能像 CNN 或 RNN 那样编码词与词之间的位置关系,但是正因为这种属性才能无视距离长短建模两个词之间的关系。因此为了令 Transformer 感知词与词之间的位置关系,我们需要使用位置编码给每个词加上位置信息。
预训练过程
BERT 最核心的就是预训练过程,这也是该论文的亮点所在。简单而言,模型会从数据集抽取两句话,其中 B 句有 50% 的概率是 A 句的下一句,然后将这两句话转化前面所示的输入表征。现在我们随机遮掩(Mask 掉)输入序列中 15% 的词,并要求 Transformer 预测这些被遮掩的词,以及 B 句是 A 句下一句的概率这两个任务。
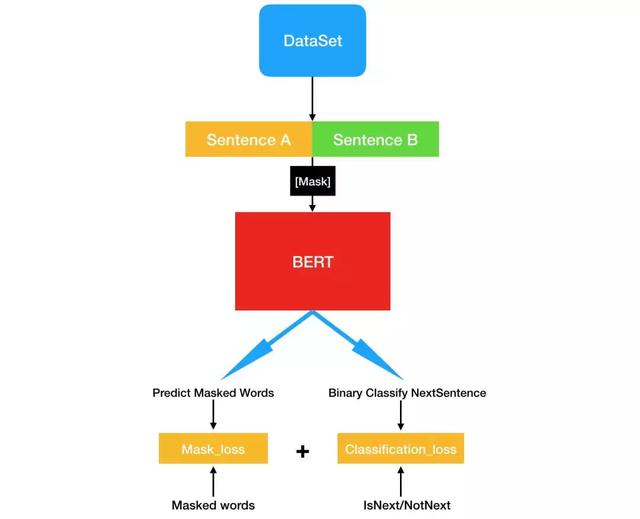
首先谷歌使用了 BooksCorpus(8 亿词量)和他们自己抽取的 Wikipedia(25 亿词量)数据集,每次迭代会抽取 256 个序列(A+B),一个序列的长度为小于等于 512 个「词」。因此 A 句加 B 句大概是 512 个词,每一个「句子」都是非常长的一段话,这和一般我们所说的句子是不一样的。这样算来,每次迭代模型都会处理 12.8 万词。
对于二分类任务,在抽取一个序列(A+B)中,B 有 50% 的概率是 A 的下一句。如果是的话就会生成标注「IsNext」,不是的话就会生成标注「NotNext」,这些标注可以作为二元分类任务判断模型预测的凭证。
对于 Mask 预测任务,首先整个序列会随机 Mask 掉 15% 的词,这里的 Mask 不只是简单地用「[MASK]」符号代替某些词,因为这会引起预训练与微调两阶段不是太匹配。所以谷歌在确定需要 Mask 掉的词后,80% 的情况下会直接替代为「[MASK]」,10% 的情况会替代为其它任意的词,最后 10% 的情况会保留原词。
- 原句:my dog is hairy
- 80%:my dog is [MASK]
- 10%:my dog is apple
- 10%:my dog is hairy
注意最后 10% 保留原句是为了将表征偏向真实观察值,而另外 10% 用其它词替代原词并不会影响模型对语言的理解能力,因为它只占所有词的 1.5%(0.1 × 0.15)。此外,作者在论文中还表示因为每次只能预测 15% 的词,因此模型收敛比较慢。
微调过程
最后预训练完模型,就要尝试把它们应用到各种 NLP 任务中,并进行简单的微调。不同的任务在微调上有一些差别,但 BERT 已经强大到能为大多数 NLP 任务提供高效的信息抽取功能。对于分类问题而言,例如预测 A/B 句是不是问答对、预测单句是不是语法正确等,它们可以直接利用特殊符 [CLS] 所输出的向量 C,即 P = softmax(C * W),新任务只需要微调权重矩阵 W 就可以了。
对于其它序列标注或生成任务,我们也可以使用 BERT 对应的输出信息作出预测,例如每一个时间步输出一个标注或词等。下图展示了 BERT 在 11 种任务中的微调方法,它们都只添加了一个额外的输出层。在下图中,Tok 表示不同的词、E 表示输入的嵌入向量、T_i 表示第 i 个词在经过 BERT 处理后输出的上下文向量。

图:选自《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》。
如上图所示,句子级的分类问题只需要使用对应 [CLS] 的 C 向量,例如(a)中判断问答对是不是包含正确回答的 QNLI、判断两句话有多少相似性的 STS-B 等,它们都用于处理句子之间的关系。句子级的分类还包含(b)中判语句中断情感趋向的 SST-2 和判断语法正确性的 CoLA 任务,它们都是处理句子内部的关系。
在 SQuAD v1.1 问答数据集中,研究者将问题和包含回答的段落分别作为 A 句与 B 句,并输入到 BERT 中。通过 B 句的输出向量,模型能预测出正确答案的位置与长度。最后在命名实体识别数据集 CoNLL 中,每一个 Tok 对应的输出向量 T 都会预测它的标注是什么,例如人物或地点等。
4 官方模型详情
前面我们已经介绍过谷歌官方发布的 BERT 项目,这一部分主要会讨论如何在不同的 NLP 任务中微调预训练模型,以及怎样使用预训练 BERT 抽取文本的语义特征。此外,原项目还展示了 BERT 的预训练过程,但由于它需要的计算力太大,因此这里并不做介绍,读者可详细阅读原项目的说明文件。
项目地址:https://github.com/google-research/bert
微调预训练 BERT
该项目表示原论文中 11 项 NLP 任务的微调都是在单块 Cloud TPU(64GB RAM)上进行的,目前无法使用 12GB – 16GB 内存的 GPU 复现论文中 BERT-Large 模型的大部分结果,因为内存匹配的最大批大小仍然太小。但是基于给定的超参数,BERT-Base 模型在不同任务上的微调应该能够在一块 GPU(显存至少 12GB)上运行。
这里主要介绍如何在句子级的分类任务以及标准问答数据集(SQuAD)微调 BERT-Base 模型,其中微调过程主要使用一块 GPU。而 BERT-Large 模型的微调读者可以参考原项目。
以下为原项目中展示的句子级分类任务的微调,在运行该示例之前,你必须运行一个脚本下载GLUE data,并将它放置到目录$GLUE_DIR。然后,下载预训练BERT-Base模型,解压缩后存储到目录$BERT_BASE_DIR。
GLUE data 脚本地址:https://gist.github.com/W4ngatang/60c2bdb54d156a41194446737ce03e2e
该示例代码在Microsoft Research Paraphrase Corpus(MRPC)上对BERT-Base进行微调,该语料库仅包含3600个样本,在大多数GPU上该微调过程仅需几分钟。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
export BERT_BASE_DIR=/path/to/bert/uncased_L-12_H-768_A-12export GLUE_DIR=/path/to/glue python run_classifier.py --task_name=MRPC --do_train=true --do_eval=true --data_dir=$GLUE_DIR/MRPC --vocab_file=$BERT_BASE_DIR/vocab.txt --bert_config_file=$BERT_BASE_DIR/bert_config.json --init_checkpoint=$BERT_BASE_DIR/bert_model.ckpt --max_seq_length=128 --train_batch_size=32 --learning_rate=2e-5 --num_train_epochs=3.0 --output_dir=/tmp/mrpc_output/ |
输出如下:
|
1 2 3 4 5 |
***** Eval results ***** eval_accuracy = 0.845588 eval_loss = 0.505248 global_step = 343 loss = 0.505248 |
可以看到,开发集准确率是84.55%。类似MRPC这样的较小数据集在开发集准确率上方差较高,即使是从同样的预训练检查点开始运行。如果你重新运行多次(确保使用不同的output_dir),结果将在84%和88%之间。注意:你或许会看到信息“Running train on CPU.”这只是表示模型不是运行在Cloud TPU上而已。
通过预训练BERT抽取语义特征
对于原论文11项任务之外的试验,我们也可以通过预训练BERT抽取定长的语义特征向量。因为在特定案例中,与其端到端微调整个预训练模型,直接获取预训练上下文嵌入向量会更有效果,并且也可以缓解大多数内存不足问题。在这个过程中,每个输入token的上下文嵌入向量指预训练模型隐藏层生成的定长上下文表征。
例如,我们可以使用脚本extract_features.py 抽取语义特征:
|
1 2 3 4 5 6 7 8 9 10 |
# Sentence A and Sentence B are separated by the ||| delimiter.# For single sentence inputs, don't use the delimiter.echo 'Who was Jim Henson ? ||| Jim Henson was a puppeteer' > /tmp/input.txt python extract_features.py --input_file=/tmp/input.txt --output_file=/tmp/output.jsonl --vocab_file=$BERT_BASE_DIR/vocab.txt --bert_config_file=$BERT_BASE_DIR/bert_config.json --init_checkpoint=$BERT_BASE_DIR/bert_model.ckpt --layers=-1,-2,-3,-4 --max_seq_length=128 --batch_size=8 |
上面的脚本会创建一个JSON文件(每行输入占一行),JSON文件包含layers指定的每个Transformer层的BERT激活值(-1是Transformer的最后一个隐藏层)。注意这个脚本将生成非常大的输出文件,默认情况下每个输入token 会占据 15kb 左右的空间。
最后,项目作者表示它们近期会解决GPU显存占用太多的问题,并且会发布多语言版的BERT预训练模型。他们表示只要在维基百科有比较大型的数据,那么他们就能提供预训练模型,因此我们还能期待下次谷歌发布基于中文语料的BERT预训练模型。
谷歌终于开源BERT代码:3 亿参数量,机器之心全面解读http://t.jinritoutiao.js.cn/RDJbdp/



