如何使用python对中文txt文件分词?
对中文txt文件分词,无非就是2步—先读取txt文本数据,然后再分词,除了常见的jieba分词外,这里再介绍3种python分词中文分词包—分别是snownlp,thulac和pynlpir,最后再结合pyecharts以词云的方式显示最终分词结果,实验环境win10+python3.6+pycharm5.0,主要介绍如下:
为了方便演示,我这里新建了一个test.txt文件,里面复制了《白鹿原》的第一章内容,如下,下面的测试都围绕这个文件而展开:

- snownlp:这个是国人开发的一个中文分词的包,受TextBlob启发而写,下面简单介绍一下这个包的安装和简单使用。
1.下载安装,这里直接输入命令”pip install snownlp”就行,如下:
![]()
2.测试代码如下,这里为了方便演示,我没有过滤掉停用词,直接做的分词、统计、最后词云显示最终统计结果,感兴趣的可以做个停用词列表过滤,很简单:
测试代码:

程序运行截图,打印的统计信息,如下:

词云显示的统计结果如下:

- thulac:这个是清华大学实验室出的一个中文分词的包,基于人民日报分词语料库,支持同时分词和词性标注功能,使用起来也很简单,下面简单介绍一下这个包的安装和使用。
1.下载安装thulac,这里直接输入命令”pip install thulac”就行,如下:
![]()
2.测试代码如下,很简单,就几行代码,与snownlp类似:
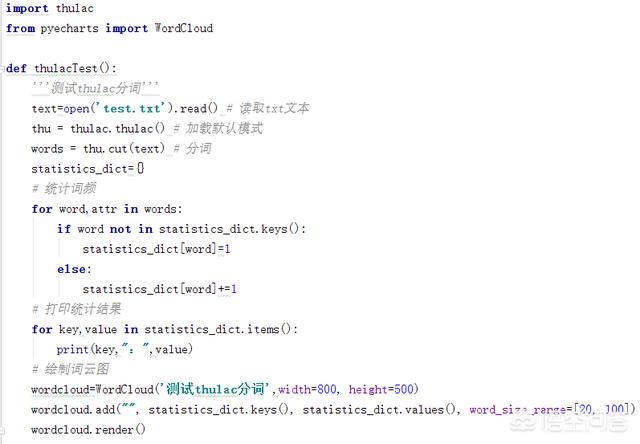
程序运行结果如下,已经成功打印出分词统计结果:

词云显示结果如下,与snownlp类似:

- pynlpir:这个包是北京市一个研究中心出的包,使用起来和上面2个包类似,也支持分词等功能,下面简单介绍一下这个包的安装和使用。
1.下载安装pynlpir,这里直接输入命令”pip install pynlpir”就行,如下:

2.测试代码如下,这里直接运行的话会提示错误—license过期,需要自己更新一下,到https://github.com/NLPIR-team/NLPIR/tree/master/License重新下载一下NLPIR.user文件,替换掉原来的NLPIR.user文件就行,代码如下:
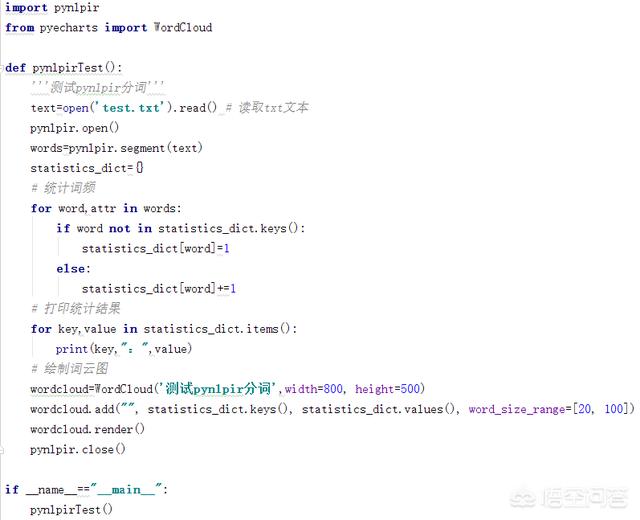
程序运行截图如下,已经成功打印出统计结果:

词云结果显示如下:

至此,snownlp,thulac和pynlpir这3个包就介绍完毕了。总的来说,使用起来都挺简单多了,只要有一定的python基础,多加练习,很快就能入门的。对于自然语言处理来说,这3个包也可以作为一个基础工具来使用,为后面的研究做好分词等准备,网上也有这几个包的教程,可以查查,学习一下,希望以上分享的内容能对你有所帮助吧。
如何使用python对中文txt文件分词?http://t.jinritoutiao.js.cn/darYdy/
转载请注明:徐自远的乱七八糟小站 » 如何使用python对中文txt文件分词?



