卷积神经网络通常被称为ConvNets,它是一种神经网络架构,主要用于图像分类,而ConvNets在图像方面非常好。ConvNets的灵感来自人类视觉皮质,现在让我们深入了解架构

#1:打开一个Jupyter NoteBook
您可以在工作目录上创建一个新的NoteBook购买开放终端,然后输入“jupyter notebook”,然后会出现一个弹出窗口,点击“新建 – > Python3”
#2:导入Python必要的依赖关系并声明数据源
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
import tensorflow as tf import matplotlib.pyplot as plt %matplotlib inline from tqdm import tqdm import numpy as np import os from random import shuffle import cv2 TEST_DIR = '/projects/My projects/dogs vs cats/test' TRAIN_DIR = '/projects/My projects/dogs vs cats/train' LEARNING_RATE = 1e-3 MODEL_NAME = "dogsvscats-{}-{}.model".format(LEARNING_RATE,"6conv-fire") IMAGE_SIZE = 50 |
- Tensorflow:Tensorflow是Google的一个深度学习框架,它允许我们构建和部署神经网络模型
- Matplotlib:Matplotlib是一个数据可视化库
- Numpy:Numpy是Python语言的一个扩充程序库。支持高级大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库。
#3:标记我们的数据
默认情况下,我们的数据集带有“cat”或“dog”的标签,但是我们不能 将字符串或字符FeedIn到我们的神经网络中,所以我们必须转换然后转换为向量,我们可以通过以下Python代码完成:
|
1 2 3 4 5 6 |
def label_image(img): img_name = img.split(".")[-3] if img_name == "cat": return [1,0] elif img_name == "dog": return [0,1] |
#4:创建我们的训练和测试集
我们有猫和狗的图像,但我们不能直接输入这些图像所以我们必须将它们转换成矩阵,我们可以通过以下Python代码执行计算:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
#This is for Training Data def train_data_loder(): training_data = [] for img in tqdm(os.listdir(path=TRAIN_DIR)): img_lable = label_image(img) path_to_img = os.path.join(TRAIN_DIR,img) img = cv2.resize(cv2.imread(path_to_img,cv2.IMREAD_GRAYSCALE),(IMAGE_SIZE,IMAGE_SIZE)) training_data.append([np.array(img),np.array(img_lable)]) shuffle(training_data) np.save("training_data_new.npy",training_data) return training_data #This is for Testing Data def testing_data(): test_data = [] for img in tqdm(os.listdir(TEST_DIR)): img_labels = img.split(".")[0] path_to_img = os.path.join(TEST_DIR,img) img = cv2.resize(cv2.imread(path_to_img,cv2.IMREAD_GRAYSCALE),(IMAGE_SIZE,IMAGE_SIZE)) test_data.append([np.array(img),np.array(img_labels)]) shuffle(test_data) np.save("test_dataone.npy",test_data) return test_data |

RGB和灰度比较
在知道如何将图像更改为矢量之前,我们必须知道如何存储和查看图像。图像是 RBG(红色,绿色和蓝色)的组合,所以基本上,我们必须将三个颜色通道输入我们的ConvNet,我们可以做到这一点,但计算成本太高(即)过多的复杂计算过程可能需要Hi-Performance GPU 和Stuffs,但是对于这个特殊的任务,我们可以用更简单和高效的方式做事,所以我们在OpenCV的帮助下将RGB图像改变为灰度图像,它只包含一个颜色通道。
由于我们已经对我们的图像进行了Grayscaling,因此我们必须将图像reshape为50 x 50图像,同时降低我们的计算功能,然后我们将其附加到我们的列表中
#5:编码我们的卷积神经网络模型
这里有趣的部分,编写我们的模型,我们必须导入所有帮助我们构建ConvNet模型的依赖项。
|
1 2 3 4 |
import tflearn from tflearn.layers.conv import conv_2d,max_pool_2d from tflearn.layers.core import input_data,dropout,fully_connected from tflearn.layers.estimator import regression |
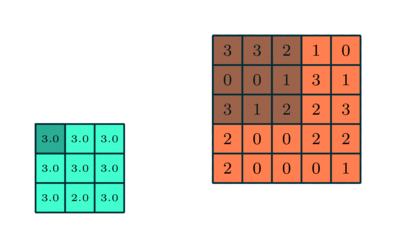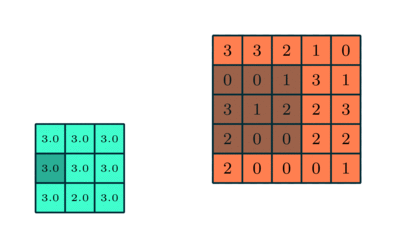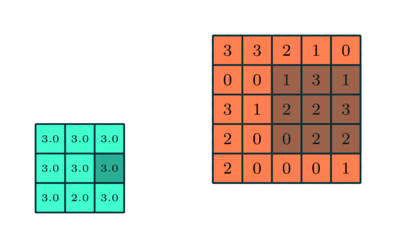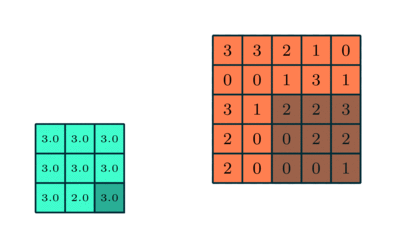
MAX POOLING
我们将使用TfLearn来构建我们的模型。首先,我们从layers.conv中导入conv_2d,因为它实际上是我们的卷积模型它是预构建的max_pool_2d用于使用最大池技术
然后,我们从layers.core导入input_data、dropout、fully_connected模块,DropOut是一种很酷的方法,通过在训练过程中随机关闭神经元来提高我们的模型精度,而完全连接层允许我们使用Softmax函数进行最终预测。
#6:建立一个ConvNet
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
import tensorflow as tf tf.reset_default_graph() convnet = input_data(shape=[None, IMAGE_SIZE, IMAGE_SIZE, 1], name='input') #Conv Layer 1 convnet = conv_2d(convnet, 32, 5, activation='relu') convnet = max_pool_2d(convnet, 5) #Conv Layer 2 convnet = conv_2d(convnet, 64, 5, activation='relu') convnet = max_pool_2d(convnet, 5) #Conv Layer 3 convnet = conv_2d(convnet, 128, 5, activation='relu') convnet = max_pool_2d(convnet, 5) #Conv Layer 4 convnet = conv_2d(convnet, 64, 5, activation='relu') convnet = max_pool_2d(convnet, 5) #Conv Layer 5 convnet = conv_2d(convnet, 32, 5, activation='relu') convnet = max_pool_2d(convnet, 5) #Conv Layer 6 convnet = fully_connected(convnet, 1024, activation='relu') convnet = dropout(convnet, 0.8) #Fully Connected Layer with SoftMax as Activation Function convnet = fully_connected(convnet, 2, activation='softmax') #Regression for ConvNet with ADAM optimizer convnet = regression(convnet, optimizer='adam', learning_rate=LEARNING_RATE, loss='categorical_crossentropy', name='targets') model = tflearn.DNN(convnet, tensorboard_dir='log') |
现在,我们已经创建了ConvNet模型。首先,我们声明了输入函数,它接受输入数据的格式,然后我们声明了5个卷积层,我们使用了ReLu
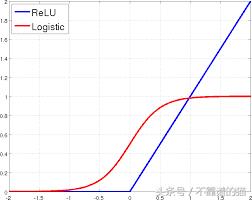
ReLu激活h函数
在第6层,我们已使用Softmax将ConvLayer转换为全连接层以进行我们的预测。最后,我们声明“ Adam ”用于优化目的
#7:拆分我们的测试和训练数据
|
1 2 3 4 5 6 7 8 9 10 |
train = train_data_g[:-500] test = train_data_g[-500:] #This is our Training data X = np.array([i[0] for i in train]).reshape(-1,IMAGE_SIZE,IMAGE_SIZE,1) Y = [i[1] for i in train] #This is our Training data test_x = np.array([i[0] for i in test]).reshape(-1,IMAGE_SIZE,IMAGE_SIZE,1) test_y = [i[1] for i in test] |
将数据分割成测试和训练集是很重要的,为了训练和验证我们的模型,我们将它转换成NumPy数组,以便于实际数据和类存储在X和y变量中
#8:训练我们的模型来识别猫和狗
|
1 2 |
model.fit(X, Y, n_epoch=6, validation_set=(test_x, test_y), snapshot_step=500, show_metric=True, run_id=MODEL_NAME) |
我们最终将我们的数据拟合到我们之前编码的卷积神经网络模型中,我们的模型要训练6个Epochs
一旦你运行这行Python代码下面你会看到这个结果

#9:保存我们的模型
所有这些过程中最重要的一步是保存我们的模型供以后使用,TFLearn通过以下代码
|
1 |
model.save(MODEL_NAME) |
这就是你如何编码你自己的卷积神经网络模型来识别给定图像中的猫和狗
利用Python和Tensorflow构建卷积神经网络的9个步骤http://t.jinritoutiao.js.cn/daf5os/



