ST多年来一直从事人工智能研究和开发。作为大批量,广泛市场,嵌入式处理解决方案的领先供应商,我们专注于开发可扩展,灵活的产品和技术,以允许AI方法使各种设备受益,支持几乎无限数量的用例。
AI在STM32微控制器上
将来,几乎所有带有32位微控制器的设备都能够使用AI技术。更具体地说,他们将能够运行经过训练以完成特定任务的DNN(深度神经网络)。
虽然目前大多数微控制器没有内存和处理能力来运行创建DNN所需的学习算法,但只要网络针对微控制器进行了优化,它们就可以自己运行DNN。

ST创建了一个工具,可以为微控制器优化DNN 。STM32CubeMx.AI计划于今年晚些时候发布,作为STM32软件生态系统的一部分。
1、将您预先训练的神经网络依赖框架输入STM32 CUBMEX。
2、STM32优化库自动快速生成代码
3、STM32 CUBMEXX.AI保证了与最先进的深度学习设计框架的互操作性。
工具采用来自各种最流行的AI框架(包括Caffe,CNTK,Keras,Lasagne,TensorFlow和theano)的预训练神经网络模型输出,并将其映射到适合记忆的优化DNN和目标STM32微控制器的处理能力。
该工具还可以检查适配的DCNN的功能 – 它可以比原始的小10倍,精度损失可以忽略不计。
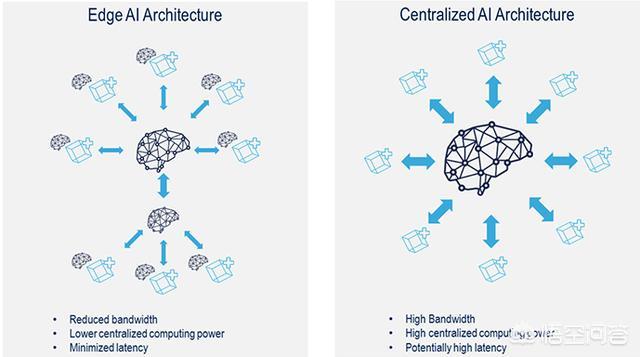
专用AI处理硬件的高级研发
ST开发了一种先进的片上系统演示器,可实现超高能效的DCNN处理。它解决了图像,视频和自然语言处理在数据速率和实时处理性能方面的挑战性要求。该演示器在28nm FD-SOI片上系统中结合了8个卷积加速器,8个双DSP集群和一个优化的分布式存储器架构。它在2017年初实现了2.9 TOPS / W @ 200MHz,0.575 V的效率。
常见框架的简洁;
Keras是由纯python编写的基于theano/tensorflow的深度学习框架。
Lasagne是 Theano 中的一个轻量级库.
TensorFlow™ 是一个采用数据流图(data flow graphs),用于数值计算的开源软件库。
Caffe/Caffe2,全称Convolutional Architecture for Fast Feature Embedding。是一种常用的深度学习框架,在视频、图像处理方面应用较多。
Theano 基于 Python,是一个擅长处理多维数组的库(这方面它类似于 NumPy)。当与其他深度学习库结合起来,它十分适合数据探索。它为执行深度学习中大规模神经网络算法的运算所设计。其实,它可以被更好地理解为一个数学表达式的编译器:用符号式语言定义你想要的结果,该框架会对你的程序进行编译,来高效运行于 GPU 或 CPU。
Computational Network Toolkit (CNTK) 是微软出品的开源深度学习工具包。
官方就放出来几张图,据说是要把CUBEMX升级成CUBEMX.AI。
说实在的,单片机发展起来搞AI也是正常的。
而且如今单片机性能如此强劲,不过,事实上这个东西我感觉应该是建立在M7内核以上了,超高性能单片机应该比较有可玩性,但是价格就有点不亲民了。
性能相对较低的F1系列,以及低功耗系列L才是STM32赚钱的地方,像F7和H7系列虽然性能强劲,但是毕竟价格也贵,而且性能相比竞品也没有突出优势。反观ATMEL以及NXP这些东西就有优势的多了,只是在消费级市场STM32太受欢迎了。
无论如何我们乐于看到新的框架新的工具出现在STM32工具平台上,虽然那个CUBEMX生成的代码经常会有问题。在此之前CMSIS-NN就是ARM官方出的AI框架,以及基于这个东西有人做出来的OPENMV,事实上还是蛮不错的,可玩性很高。
官方推这个还是很不错的,如果真的能搞起来估计又是消费级市场腥风血雨,反观开发者,又要无止境的学习学习学习。哈哈。学海无涯,回头是岸!
如何评价ST的STM32CubeMX.AI?http://t.jinritoutiao.js.cn/d5FYUc/
转载请注明:徐自远的乱七八糟小站 » 如何评价ST的STM32CubeMX.AI?