在不远的将来,实现一定程度上的语音支持将成为日常科技的基本要求。整合了语音识别的 Python 程序提供了其他技术无法比拟的交互性和可访问性。最重要的是,在 Python 程序中实现语音识别非常简单。
语言识别工作原理概述(提供一份Python学习资料置于文末)

语音识别的首要部分当然是语音。通过麦克风,语音便从物理声音被转换为电信号,然后通过模数转换器转换为数据。一旦被数字化,就可适用若干种模型,将音频转录为文本。



幸运的是,对于 Python 使用者而言,一些语音识别服务可通过 API 在线使用,且其中大部分也提供了 Python SDK。

选择 Python 语音识别包
PyPI中有一些现成的语音识别软件包。其中包括:


SpeechRecognition 库可满足几种主流语音 API ,因此灵活性极高。其中 Google Web Speech API 支持硬编码到 SpeechRecognition 库中的默认 API 密钥,无需注册就可使用。SpeechRecognition 以其灵活性和易用性成为编写 Python 程序的最佳选择。
安装 SpeechRecognation
SpeechRecognition 兼容 Python2.6 , 2.7 和 3.3+,但若在 Python 2 中使用还需要一些额外的安装步骤。本教程中所有开发版本默认 Python 3.3+。
读者可使用 pip 命令从终端安装 SpeechRecognition:


识别器类





音频文件的使用

支持文件类型

使用 record() 从文件中获取数据



例如,以下内容仅获取文件前四秒内的语音:






噪声对语音识别的影响

尝试转录此文件时会发生什么?





通过把 recognition_google()中 True 参数改成 show_all 来给出完整响应。


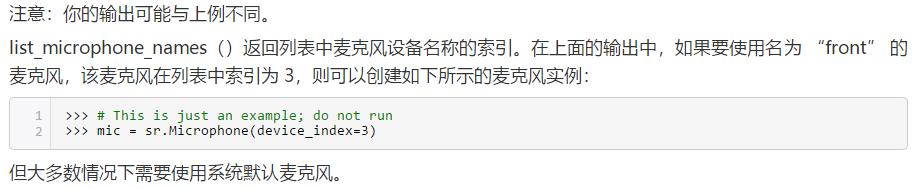
麦克风的使用
若要使用 SpeechRecognizer 访问麦克风则必须安装 PyAudio 软件包,请关闭当前的解释器窗口,进行以下操作:
安装 PyAudio
安装 PyAudio 的过程会因操作系统而异。
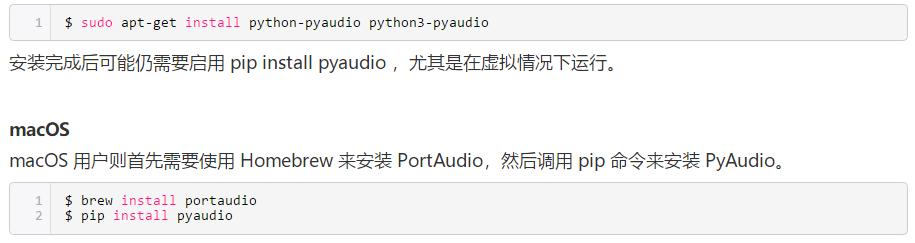
Debian Linux
如果使用的是基于 Debian的Linux(如 Ubuntu ),则可使用 apt 安装 PyAudio:

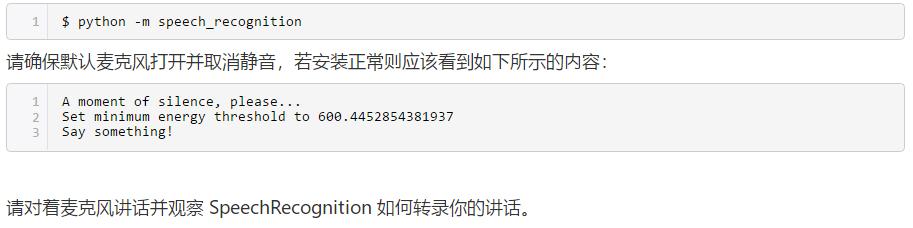
安装测试
安装了 PyAudio 后可从控制台进行安装测试。
Microphone 类


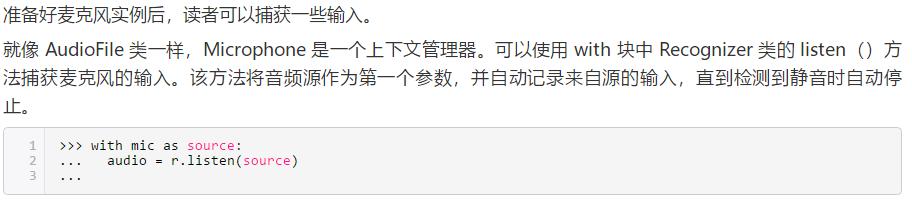
使用 listen()获取麦克风输入数据


处理难以识别的语音


私信小编007即可获取Python学习资料一份。
傻瓜式教学,某大学教师给学生的一份Python语音识别详细教材!http://t.jinritoutiao.js.cn/eVQdFm/



