阅读本文,你将对以下几点有所了解:
1.如何将内存中的数据输入到模型中。
2.把TFRecord格式”提供”给你的模型。
3.将磁盘中的原始图像输入到模型中。
在本文中,作者将重点介绍内存中的数据。想更好的阅读本文,你需要了解(或掌握)神经网络的基本工作原理,Tensorflow基础知识和Keras基础模型构建。
相关链接:https://gist.github.com/shang-vikas/36176e3bed6f3234fd1c27465d8bec22

如果你的电脑没有GPU,请安装TensorFlow的CPU版本。
数据集
我们将使用最近流行的MNIST数据集。MNIST数据集包含0到9的数字图像。该数据集支持numpy数组格式。因此,作者提供了将数据转换为TFRecords格式和磁盘上原始图像的代码。
相关链接:
https://gist.github.com/shang-vikas/3670a06f0e4bfc1a52f4847ac3d31c78
第一部分 使用Estimator API(使用估计量API)
Tensorflow希望通过提供高水平的估计量API,以花费最少的时间来定义你的模型。这也是我们使用此API来构建我们模型的原因。这个模型的数据集共有10类。模型中有2个隐藏层,每层有100个神经元,每个神经元的输出层为10。
当你使用估计量API创建模型时,它会把数据集的特征类型作为训练期间所要提供的重要列表。由于我们正在使用包含数字的图像,所以我们将为它提供一个数字类型的特征列表。

这里的key是我们希望提供给特征列表的名称。需要注意的是,在向模型提供数据时,我们也应该将相同的key传递给模型。
如果你想深入研究这方面,请点击:https://www.tensorflow.org/get_started/feature_columns
现在,为了创建模型,我们将使用预先制作的估计器——DNNClassifier a.k.a深层神经网络分类器,你可以根据需要添加尽可能多的密集层。
定义模型

现在,我们已经定义了模型,接着让我们定义数据集流。

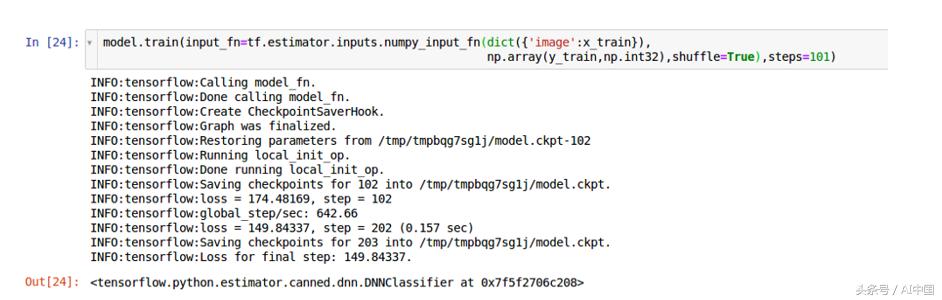
1.使用Numpy数组

因为我们在这里使用的是Numpy数组。(Tensorflow在tf.estimator.inputs中提供此功能。)需要强调的是,我们的训练步为101步,默认批量为128。详见下图:

输出应该是这样的
但是如果你想在将数据输入到模型之前对数据进行一些预处理,该怎么做呢?这时候,你就要考虑数据集API了。
正如你在上面的代码行中看到的,model.train更适合来自输入函数的数据。由于该函数需要一个预处理函数用于预处理,因此我们可以编写一个预处理函数,将numpy数组转换为张量,并将数据类型更改为float32,因为密集图层的权重为dtype float32。
注意:通常情况下,首先要将数据转换为张量(Float 32,int 32),否则会出现一些奇怪的错误,从而导致很多问题。

现在编写输入函数,返回生成器以获取下一批数据。

这里我们使用DATASET API(tf.data.Dataset)。因为我们前面使用了Numpy数组,所以我们可以调用from_tensor_slices传递数据。

如果你有一个包含各种数字和分类特征的数据集,那么你可以考虑使用Dataset API的TextLineDataset(链接:https://www.tensorflow.org/get_started/datasets_quickstart)或tf.estimator.inputs中的pandas_input_fn,但作者强烈推荐前者。
把传入的数据现在传递给我们编写的_parse_preprocess函数中,并返回一个包含两个元素的元组。这个元组包含关于密钥和数据为dtype tf.float32的784张张量图像,其次是关于dtype tf.int32的内容。
对了,shuffle()和.batch()分别表示对数据进行混洗和批处理。
要迭代这些批次的数据点,我们可以调用make_one_shot_iterator,并把它们返回到a.k.a生成器。需要注意的是,get_Next()只返回下一批数据。
现在是时候训练我们的模型了。注意:estimator.train()中的input_fn不支持带有参数的函数。解决方案是使用Python的lambda功能。
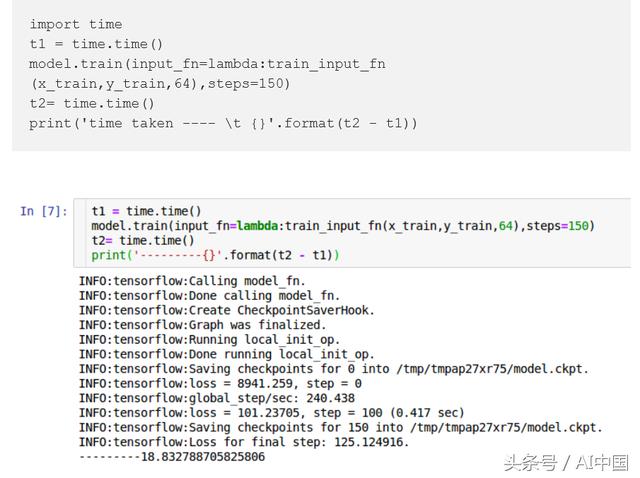
结论:
上面的代码适用于numpy数组的图像数据。概括一下,如果数据具有以下特征,比如说数字列、序数、标签类型等。你可以参照下面的这些提示:
1.在创建模型时传递列表中的特征名称。
2.使用tf.data.DatasetAPI中的TextLineDataset,而不是TRAINS_INPUT_FN()中的FROM_tensor_。
3.即便将数据集映射到适当的预处理函数中,该函数仍将返回包含DECT和标签中具有适当键的特征元组。
4.进行数据混洗,按要求批处理,最后制作迭代器并返回下一批。
关于TensorFlow 的初学者指南,还在“门外徘徊”的你一定要查收http://t.jinritoutiao.js.cn/Jd1YRE/



