【如何通过人工神经网络实现图像识别?】

首先,我们需要把图像转换成神经网络能够接受的格式(表示,representation)。然后,我们设计一个神经网络模型(model)。之后我们在一大堆图像上训练(train)上一步设计的神经网络。最后我们用训练好的网络来识别图像。
表示
图像如何表示?假设我们有一个图像,该图像的大小是646×454。那么,我们可以用一个[646, 454]的矩阵来表示这个图像,矩阵中的每个元素对应一个像素。这是一个非常简单直接的做法。假设我们用1表示对应像素为黑色,用0表示对应像素为白色,那么我们的矩阵就由大量1和0组成。大概就是这副样子:
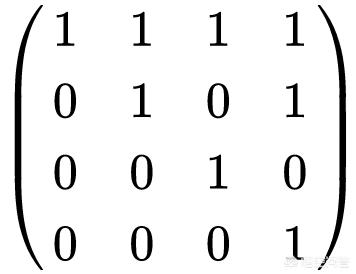
(图片来源:维基百科)
646×454太大了,画不下,上面是一个4×4的示意图,你可以把它想象成是由646×454个元素组成的巨大矩阵。
显然,这个矩阵只能表示真黑白图像。如果我们要表示灰度图像,那么我们可以用一个数字表示像素的亮度(intensity)。比如,下面这个矩阵(同样需要你发挥想象力,将它想象成一个646×454的巨大矩阵)。
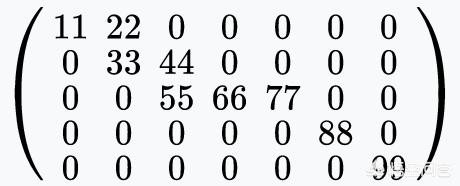
(图片来源:维基百科)
那么,如果是彩图怎么办?很简单,再增加一个维度。用[646, 454, 3]表示。(数字3是因为一般我们用RGB系统表示色彩,比如,[1.0, 0.0, 0.0]表示红色)。
所以,某种意义上说,灰度图像(也就是我们平常说的黑白照片)才是真2D图像。;-)
想一想,真3D图像该怎么表示?(想到了请留言讨论。)
模型
将图像转换为矩阵或张量后,我们就可以让神经网络学习这些矩阵或张量了。最早的神经网络就是这么干的。当然,这么干有一个缺点,就是只能处理尺寸非常小的图像,否则算力负担太重。
所以,后来人们提出了卷积网络(CNN),大大提升了处理图像的性能。现在CNN是图像识别的主流。
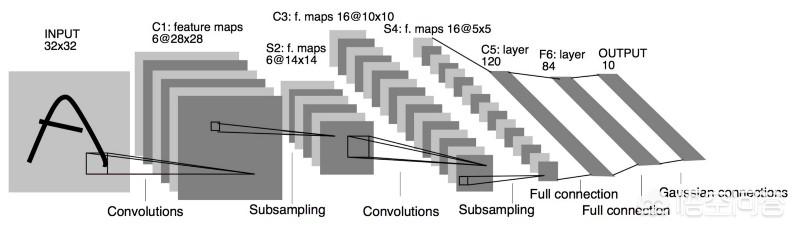
(图为Yann LeCun1994年提出的LeNet5,是最早出现的CNN之一。)
CNN的基本思路很简单,图像中有很多空间关系,比如线条什么的。直接学习像素,不好好利用这些空间关系,太傻了。

(图片来源:arXiv:1710.10777)
从上图我们可以看到,CNN不同层学习不同层次的空间关系(特征),从细小的局部的边缘,逐渐到高层的抽象特征。
训练
简单来说,训练过程分为以下几步:
- 搜集大量图像
- 如果图像不够,我们通过数据增强手段生成一些新图像,比如平移几个像素,缩放一下图像,这样可以避免模型过拟合
- 将图像分为训练集和测试集(比如,按80%和20%的比例切分)
- 在训练集上训练
- 用测试集评估模型的表现
训练成功后,就可以将新图像传给神经网络,让神经网络自动识别。
转载请注明:徐自远的乱七八糟小站 » 【如何通过人工神经网络实现图像识别?】



