【周星驰的睡梦罗汉拳心法,现在AI也学会了:梦中“修炼”,醒来“实战”】

听说过“睡梦罗汉拳”么?
电影《武状元苏乞儿》中,周星驰在梦中得到老乞丐心法传授,学会了睡梦罗汉拳。
只是睡了一觉,醒来就武功天下第一。

边睡边学习,可能不少同学都YY过……真正做到能有几人?
没想到,现在AI已经学会了。
刚刚,两位人工智能界的大牛:Google Brain团队的David Ha(从高盛董事总经理任上转投AI研究),瑞士AI实验室的Jürgen Schmidhuber(被誉为LSTM之父),共同发布了最新的研究成果:
World Models(世界模型)。

简而言之,他们教会了AI在梦里“修炼”。
AI智能体不仅仅能在它自己幻想出来的梦境中学习,还能把学到的技能用到实际应用中。
一众人工智能界同仁纷纷发来贺电。
还有人说他们俩搞的是现实版《盗梦空间》,并且P了一张电影海报图:把Ha和Schmidhuber头像换了上去……

这种神奇能力是怎么回事?
量子位结合两位大牛的论文,尝试解释一下。
在梦里开车
在梦境中学,在现实中用,可以说是高阶技能了,我们先看一个比较基础的:
在现实里学,到梦境中用。
David Ha和Schmidhuber让一个AI在真正的模拟环境中学会了开车,然后,把它放到了“梦境”里,我们来看看这个学习过程:
先在真实的模拟环境中学开车:

当然,上图是人类视角。在这个学习过程中,AI所看到的世界是这样的:

把训练好的AI智能体放到AI的梦境中,它还是一样在开车:

这个梦境是怎么来的?要讲清楚这个问题,量子位还得先简单介绍一下这项研究的方法。他们所构建的智能体分为三部分,观察周围世界的视觉模型、预测未来状态的记忆模型和负责行动的控制器。
负责做梦的主要力量,就是其中的记忆模型。他们所用的记忆模型是MDN-RNN,正这个神经网络,让Google Brain的SketchRNN,能预测出你还没画完的简笔画究竟是一只猫还是一朵花。

在开车过程中,记忆模型负责“幻想”出自己在开车的场景,根据当前状态生成出下一时间的概率分布,也就是环境的下一个状态,视觉模型负责将这个状态解码成图像。他们结合在一起生成的,就是我们开头所说的“世界模型”。
然后,模型中的控制器就可以在记忆模型生成出来的虚假环境中开车了。
在梦里学打Doom
做梦开车很简单,但两位大牛的研究显然不止于此。既然AI幻想出来的环境很接近真实,那理论上讲,他们这项研究的终极目的也是可以实现的:让AI做着梦学技能,再用到现实中。
这一次,他们用了VizDoom,一个专门供AI练习打Doom的平台。
“做梦”的主力,又是我们前面提到过的记忆模型。和赛车稍有不同的是,它现在不仅需要预测环境的下一状态,为了让这个虚拟环境尽量真实,同时还要预测AI智能体的下一状态是死是活。
这样,强化学习训练所需的信息就齐全了,梦境中的训练,GO!

梦境重现了真实环境中的必要元素,和真正的VizDoom有着一样的游戏逻辑、物理规则和(比较模糊的)3D图形,也和真实环境一样有会扔火球的怪物,AI智能体要学着躲避这些火球。
更cool的是,这个梦境可以增加一些不确定因素,比如说让火球飞得更没有规律。这样,梦中游戏就比真实环境更难。
在梦境中训练之后,AI就可以去真正的VizDoom中一试身手了:
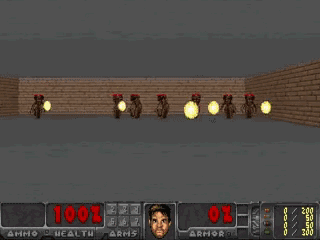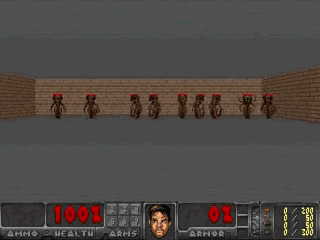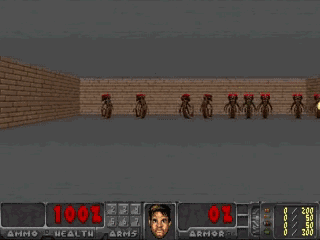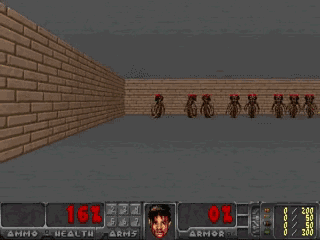
AI在VizDoom中的表现相当不错,在连续100次测试中跑过了1100帧,比150帧的基准得分高出不少。
真是666啊……
怎么做到的?
他们所用的方法,简单来说就是RNN和控制器的结合。
这项研究把智能体分为两类模型:大型的世界模型和小型的控制器模型,用这种方式来训练一个大型神经网络来解决强化学习问题。
具体来说,他们先训练一个大型的神经网络用无监督方式来学习智能体所在世界的模型,然后训练一个小型控制器使用这个世界模型来学习如何解决任务。
这样,控制器的训练算法只需要在很小的搜索空间中专注于信任度分配问题,而大型的世界模型又保障了整个智能体的能力和表达性。
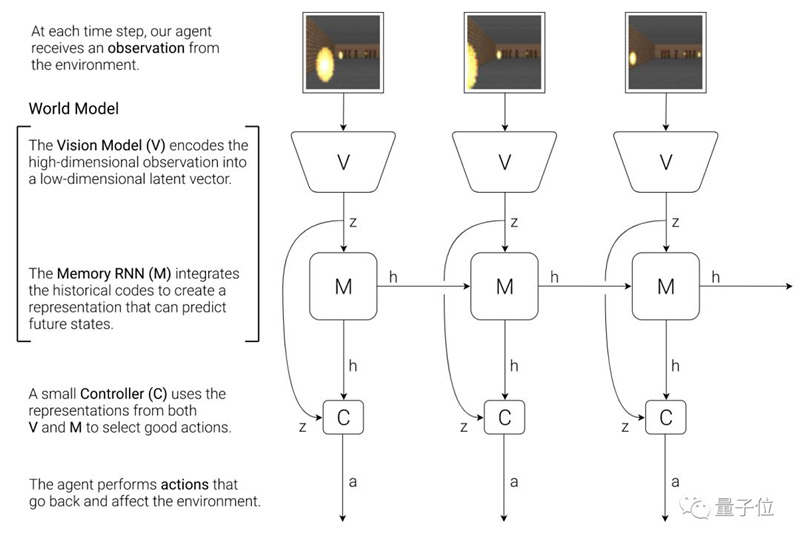
这里的世界模型包括两部分,一个视觉模型(V),用来将观察到的高维信息编码成低维隐藏向量;一个是记忆RNN(M),用来借历史编码预测未来状态。控制器(C)借助V和M的表征来选择好的行动。
在我们上面讲到的开车、打Doom实验中,视觉模型V用了一个VAE,变分自编码器;记忆模型M用的是MDN-RNN,和谷歌大脑让你画简笔画的SketchRNN一样;控制器C是一个简单的单层线性模型。
把这三个模型组装在一起,就形成了这项研究中智能体从感知到决策的整个流程:

视觉模型V负责处理每个时间步上对环境的原始观察信息,然后将这些信息编码成隐藏向量zt,和记忆模型M在同一时间步上的隐藏状态ht串联起来,输入到控制器C,然后C输出行为向量at。
然后,M根据当前的zt和at,来更新自己的隐藏状态,生成下一步的ht+1。
这有什么用?
让AI会“做梦”,还能在“梦境”中学习,其实有很多实际用途。
比如说在教AI打游戏的时候,如果直接在实际环境里训练,就要浪费很多计算资源来处理每一帧图像中的游戏状态,或者计算那些和游戏并没有太大关系的物理规则。用这个“做梦”的方式,就可以在AI自己抽象并预测出来的环境中,不消耗那么多计算资源,一遍又一遍地训练它。
在这项研究中,他们还借助了神经科学的成果,主要感知神经元最初出于抑制状态,在接收到奖励之后才会释放,也就是说神经网络主要学习的是任务相关的特征。
将来,他们还打算给VAE加上非监督分割层,来提取更有用、可解释性更好的特征表示。
文:夏乙
编辑:顾军
责任编辑:许琦敏
转载自量子位