【最全解读!从原理到代码,Hinton的胶囊网络实用指南(附视频+代码)】
这里是,油管Artificial Intelligence Education专栏,原作者Siraj Raval授权雷锋字幕组编译。
原标题 Capsule Networks: An Improvement to Convolutional Networks
翻译 | 夏雪松 郑汉伟 字幕 | 凡江 整理 | Frank
去年10月,深度学习之父Hinton发表《胶囊间的动态路由》(Capsule Networks),最近谷歌正式开源了Hinton胶囊理论代码。
Geoffrey Hinton是深度学习方面的教父之一,在80年代他推广了反向传播算法。正是由于反向传播算法,深度学习效果显著。在第一次AI寒冬中(80年代),其他人不相信神经网络能够奏效,而Hinton却坚信神经网络的观点,这正是他如此伟大的原因。
Siraj会重点介绍卷积神经网络的飞速发展史以及胶囊网络的工作原理、TensorFlow代码。
目前最先进的算法:卷积神经网络
这是一张关于卷积神经网络(CNN)的图片,如果我们使用标准的多层感知器,也就是说——所有的层完全的连接到其他的每一个层,它会很快变得难以计算。因为图像的维度非常高,有很多很多像素。
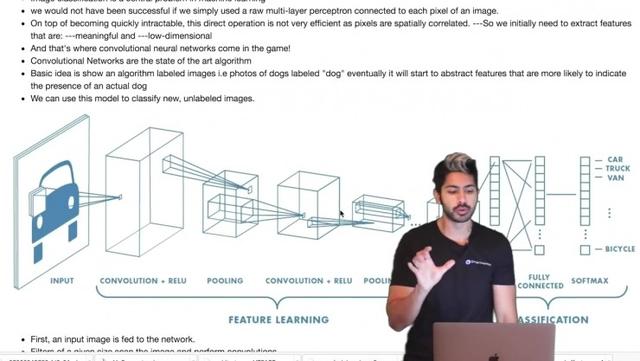
(卷积神经网络)
如果我们将这些操作连续地应用于图像中的每个单个像素每层,这将会花费太长的时间。我们的解决方案就是——使用一个卷积网络。首先我们得到一张输入的图像,这个输入的图像有一个相关的标签,如果这是一张汽车的图片,就像我们看到的,它会有一个相关的车的标签。图片是汽车,那么它的标签就是汽车。
一个卷积神经网络将要做的是——学习输入数据和输出标签间的映射关系。这个卷积神经网络在训练后,如果我们给它一张汽车的照片,它会知道那是一辆汽车,因为它已经学到了映射关系。当我们第一次为这个网络提供一个汽车的图片,它首先被应用到卷积层。在卷积层中,首先是一系列的矩阵乘法,后面是一个求和操作,下面在高层次上对它进行解释。
卷积层就像一个手电筒一样,它作用在图像中的每一个像素上。它试图寻找该图像中最相关的部分。通常卷积层会输出特征图,这些特征图代表了很多特征。卷积层从图像中学习到的一组特征是由矩阵表示的。我们将一个非线性单元应用到其中,就像整流后的线性单位。
当我们对其应用非线性时,通常会出于不同的目的:第一个目的是让网络可以学习,如何同时具有线性和非线性函数。因为神经网络是通用函数的近似误差,对于整流线性装置尤其如此;使用它的另一个目的是——与其他非线性类型不同,它解决了反向传播过程中梯度消失的问题。
当我们前向传播时我们执行一系列操作,我们得到输出类的概率,将它与实际标签进行比计算误差值,然后使用误差计算得到梯度。当我们对网络反向传播时,梯度告诉我们如何更新我们的权重,它有助于解决消失梯度问题,因为有时候当梯度反向传播时将变得越来越小,因此权值的更新也变得越来越小。
卷积神经网络的发展历程
视频中有一张很大的的现代史的关于目标识别的图,针对卷积神经网络的历史发展囊括得非常详尽,包括 ImageNet 竞赛和所有已经取得的进步等等,下面我们会仔细介绍一下。

(物体识别的发展历程)
AlexNet
卷积神经网络取得的第一个进步是AlexNet网络,它是在2012年提出的。这里有一些关键的改进:它提出了ReLu,也就是有助于防止消失的梯度问题;它也引入了dropout的概念,使得每层中神经元随机地打开和关闭,防止过拟合。如果你的数据过于相似,它不能够对相似但不同的图像进行分类,因为它过拟合了你的训练数据。
因此dropout是一种防止过拟合的正则化技术,通过随机地打开和关闭神经元,数据被迫寻找新的路径,因为它被迫寻找新的路径,网络能够更好地泛化;卷积网络也引入了数据增强的想法,AlexNet或者AlexNet的作者将经过不同角度旋转的图像送入AlexNet网络,而不是仅仅放入单一角度的,这使得它更好的适用于不同的角度,这是一个更深的网络,所以他们增加了更多的层,这提高了分类的准确性。
VGG Net
在这之后,就是VGG Net。其中最大的变化是,我们添加了更多的层。
GoogLeNet
此后是GoogLeNet。GoogLeNet卷积核的尺寸不同。我们在同一个输入中,把它连接在一起。在单独的层操作,而不是只经过一次卷积操作。我们先是乘法,接下来是求和操作。它先是乘一些东西,再乘一些东西,然后把所有这些乘法的输出连接在一起,进行前向传播。这使得它更好地学习在每一层中的特征表示。
ResNet
接下来是ResNet,这是在resin之后的创意。如果我们只是保持堆叠层,那么网络每次都会变得更好吗?答案是否定的。如果你增加更多的话,性能会发生下降。ResNet说没关系。每隔两层进行数组元素依次相加操作,它只是增加了这个操作,并且改进梯度传播,从而使得反向传播更加容易。进一步解决了梯度消失的问题。
DenseNet
这之后是DenseNet。DenseNet 提出将网络中每一层的所有块与其他层连接起来。这是一种更复杂的连接策略。网络被设计的越来越深。还有一些计算技巧正在被添加到这些卷积网络上,比如ReLu或dropout或批量标准化(Batch Normalization),从而提升了性能。另外,我们还在网络层之间使用越来越多的连接,但是Hinton说卷积神经网络存在问题。
卷积神经网络可以从看到的东西里面,学习最底层的特征。
以狗为例,在最底层学习耳朵的边和曲率,然后我们沿着层次向上到高层,当我们进入下一层时学到的每一个特征将会变得更加复杂——第一层是边缘特征,下一层学到的特征变成了形状,下一层它们变成更加复杂的形状,比如一个完整的耳朵,在最后一层,它们变成非常非常复杂的形状,比如狗的整个身体。
这与我们所知道的人类视觉皮层的工作方式非常相似。每当我们看到某些东西的时候,按层次顺序激活神经元。当我们试图去识别一些我们所看到的东西时,我们并不知道精确的复杂的细节层间的连接机制,但是我们知道在每个层之间都会有层次关系发生。

(卷积网络为何存在问题)
卷积神经网络的症结在哪?
1. 首先所有下采样池化层都会失去高精度的空间信息,在高层特征中就好比鼻子和嘴巴之间的空间关系,仅仅能够区分鼻子和嘴巴是不够的,就好像如果你的鼻子在图片中的左边角落,而嘴巴在图片中的右边角落,眼睛在图片的下面,你总不能说根据这三个特点说这肯定是一张脸。
2. 还有一个空间相关性——眼睛要在鼻子的上面,鼻子要在嘴巴上面。但是下采样或池化会失去这种关系,它们对几何关系的理解卷积网络在图像检测上很糟糕。
针对这个问题,我们的想法是不变的。我们要努力争取同变性(Equivariance),所以下采样或池化初衷是一样的。

(同变性和不变性)
子采样或池化试图让神经活动在小变化上保持不变性,所以这意味着无论图像怎么旋转位置在哪,或者旋转某些图像,神经网络响应是相同的,也就是说数据流是相同的,但最好还是针对同变性,这意味着如果我们旋转一张图像,神经网络也要发生改变。
所以我们需要的是一个更鲁棒的网络去改变,由于图像位置的变换,我们需要能对从未见过的数据有更好的泛化能力的算法,建立在已训练的网络的基础上。
解读胶囊网络论文
本文所探讨的关于卷积网络的论文,内容主要讲的是一种针对深度神经网络的像素攻击,论文的作者发现,通过调整图像中一丁点像素,整个网络分类变得很糟糕。
例如,对狗的分类本可以进行完美预测,但只改变这一丁点像素,他们发现整个网络分类效果并不好。无意义的神经网络容易受到攻击,如果自动驾驶车辆这些巨大机器飞驰在马路上,它们使用计算视觉去检测路况,这些系统是不能够受到这些像素攻击的影响,它们必须非常稳健。
Hinton介绍胶囊网络的想法是——人类大脑必须在比池化更好的方式下实现平移不变性。Hinton假设大脑有一些模块,他称之为胶囊。
这些模块非常擅长处理不同类型的视觉刺激,以及在一个确定方式下进行编码。卷积神经网络指导数据如何通过池化操作传输到每个层。如果我们输入一张图像并对它应用卷积操作,然后对它进行非线性操作,接着根据图像的池化层的输出来拉取它,在一个确定方向上进入下一层。不过它会冲击基于池化的下一层中的某些单位,但池化是路由数据非常粗糙的方式。
有一个更好的路由数据的方式,胶囊网络背后基本想法是——这只是一个神经网络而不是仅仅添加另一个层,所以通常我们添加不同类型的层而不是在一个层上嵌套新层,也就是说我们在层的里面添加另一个层,所以这是个内部嵌套层。由此,内部嵌套层被称为一组神经元胶囊。

(胶囊网络)
胶囊网络有两个主要特性:第一是基于层的压缩,第二是动态路由。典型的神经网络只有一个单元输出被非线性挤压,所以我们有一套输出神经元,而且基于每个输出神经元,我们给每个神经元应用非线性而不是给每个个体神经元应用非线性,组合这些神经元到一个胶囊中,然后应用非线性到整个神经元集。所以当我们应用非线性的时候,对整个层而不是对个体神经元实现动态路由,它用矢量输出胶囊取代了输出映射检测器,而且它通过路由和协议取代了最大化池化。
每个层中的每个胶囊当它们向前传播数据的时候,会进入下一个最相关的胶囊中,有点像层内嵌套层的层次结构树,这一新架构的代价是这个路由算法。
基本上常规的卷积网络的主要不同点是——向前传播有一个额外的外环,它要在所有单元(至少一个)上进行四个迭代去计算输出。数据流看起来有一丁点复杂,因为对于每个胶囊来说嵌套在一个图层中应用这些操作,无论是Softmax函数或者压缩函数(squashing function)会让梯度更难计算。并且模型可能会遭遇较大数据集中的消失梯度,这可能会阻止网络扩展。
代码演示和讲解
我们可以看到一些代码是还在更新中的,这篇论文比较新。不过这个代码是用tensorFlow创建的。
所以在这一层注意只有两个import(代码中的关键字)或者numpy(Python基础包)和tensorFlow。
它是个很干净的架构,构造了这个胶囊卷积层。这个架构有输出数目(num_outpurs变量)、内核大小(kernel_size变量)、类似stride变量的超参数这个if-else语句。讲的是——如果不用路由方案创建这种方法,那就直接创建这种方法。
如果我们有路由方案,我们将从一个有所有胶囊的列表开始,迭代遍历我们指定的单元数目,循环创建一个卷积层就像一个标准tensorFlow卷积层,存储到这个胶囊变量里面,然后把这个胶囊变量添加到胶囊列表中。最终我们有了这个胶囊层中的所有卷积层。这就是它嵌套的过程。一旦我们有了所有层把它们串联在一起,然后用这个novel非线性函数进行压缩。
我们来看下这个胶囊实现方法,对于ReLU我们把它添加到一个单神经元,但当我们添加一个非线性,得到到一组神经元或胶囊,我们发现这种非线性运行得很好。所以一旦我们有胶囊层,我们可以把它引入到胶囊网络中。
我们可以往前看,开始创建我们的架构,对于每个层有一个primaryCaps变量和一个digitCaps变量,给它们添加一个胶囊层。在每个胶囊层内部都有一个嵌套的卷积网络,那些胶囊中应用论文中的novel非线性压缩函数。
所以论文中网络的最后只是用一个解码器去重构一个来自数字胶囊层的数字,之后应用了第一套胶囊操作,然后可以重构来自该学习表示法的输入,应用一个重构损失去提高学习表示法,这就是重建误差。 随着时间推移重构损失被用来学习表示法和提升该表示法。

代码演示:https://github.com/llSourcell/capsule_networks
论文原文:https://arxiv.org/pdf/1710.09829.pdf
更多文章,关注雷锋网(公众号:雷锋网),添加雷锋字幕组微信号(leiphonefansub)为好友
备注「我要加入」,To be a AI Volunteer !雷锋网雷锋