【python程序员如何找到心仪小姐姐?】
感谢关注天善智能,走好数据之路↑↑↑
欢迎关注天善智能,我们是专注于商业智能BI,人工智能AI,大数据分析与挖掘领域的垂直社区,学习,问答、求职一站式搞定!
可以加: xtechday (长按复制),进入Python爱好者交流群。
既然是Python程序员找小姐姐,就要用python程序员的方法。
今天我们的目标是,爬社区的小姐姐~而且,我们又要用到新的姿势(雾)了~scrapy爬虫框架~
1scrapy原理
在写过几个爬虫程序之后,我们就知道,利用爬虫获取数据大概的步骤:请求网页,获取网页,匹配信息,下载数据,数据清洗,存入数据库。
scrapy是一个很有名的爬虫框架,可以很方便的进行网页信息爬取。那么scrapy到底是如何工作的呢?之前在网上看了不少scrapy入门的教程,大多数入门教程都配有这张图。
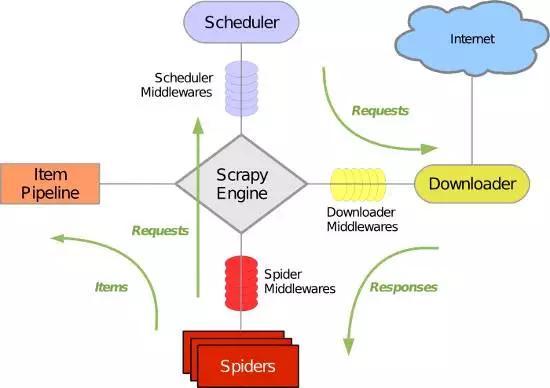
_(:зゝ∠)_也不知道是这张图实在太经典了,还是程序员们都懒得画图,第一次看到这个图的时候,米酱的心情是这样的

经过了一番深入的理解,大概知道这幅图的意思,让我来举个栗子(是的,我又要举奇怪的栗子了):
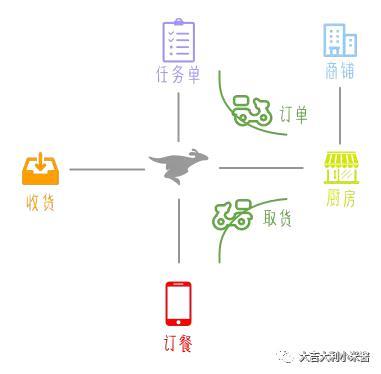
当我们想吃东西的时候,我们会出门,走到街上,寻找一家想吃的点,然后点餐,服务员再通知厨房去做,最后菜到餐桌上,或者被打包带走。这就是爬虫程序在做的事,它要将所有获取数据需要进行的操作,都写好。
而scrapy就像一个点餐app一般的存在,在订餐列表(spiders)选取自己目标餐厅里想吃的菜(items),在收货(pipeline)处写上自己的收货地址(存储方式),点餐系统(scrapy engine)会根据订餐情况要求商铺(Internet)的厨房(download)将菜做好,由于会产生多个外卖取货订单(request),系统会根据派单(schedule)分配外卖小哥从厨房取货(request)和送货(response)。说着说着我都饿了。。。。
什么意思呢?在使用scrapy时,我们只需要设置spiders(想要爬取的内容),pipeline(数据的清洗,数据的存储方式),还有一个middlewares,是各功能间对接时的一些设置,就可以不用操心其他的过程,一切交给scrapy模块来完成。
2创建scrapy工程
安装scrapy之后,创建一个新项目
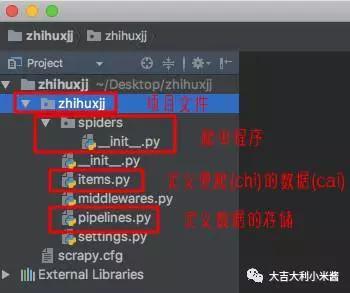
我用的是pycharm编译器,在spiders文件下创建zhihuxjj.py
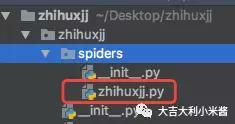
在zhihuxjj.py这个文件中,我们要编写我们的爬取规则。
3 爬取规则制定(spider)
创建好了项目,让我们来看一下我们要吃的店和菜…哦不,要爬的网站和数据。
我选用了知乎作为爬取平台,知乎是没有用户从1到n的序列id的,每个人可以设置自己的个人主页id,且为唯一。所以采选了选取一枚种子用户,爬取他的关注者,也可以关注者和粉丝一起爬,考虑到粉丝中有些三无用户,我仅选择了爬取关注者列表,再通过关注者主页爬取关注者的关注者,如此递归。
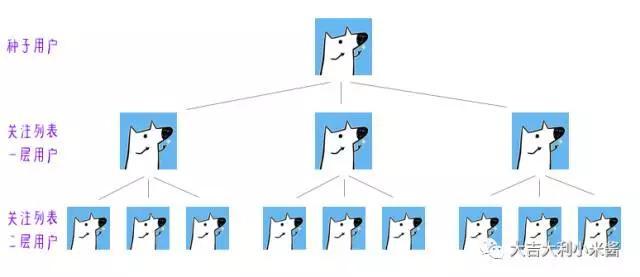
对于程序的设计,是这样的。
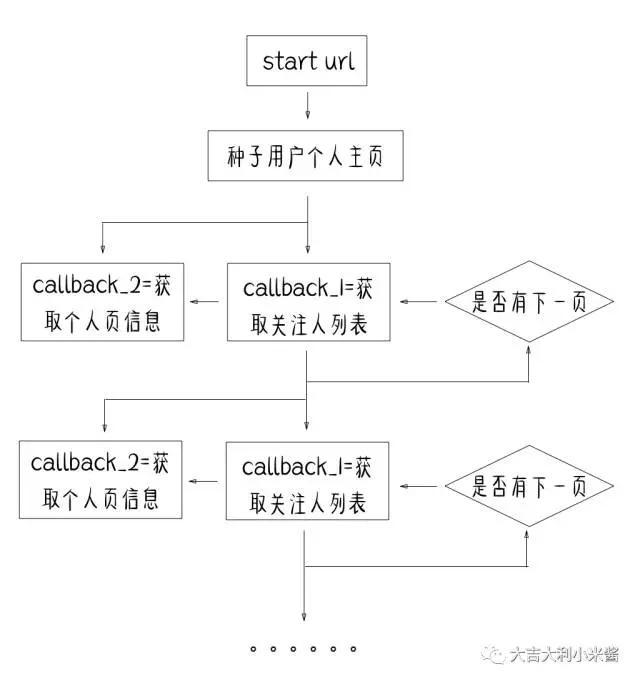
start url是scrapy中的一个标志性的值,它用于设置爬虫程序的开始,也就是从哪里开始爬,按照设定,从种子用户个人主页开始爬便是正义,但是考虑到个人主页的链接会进行重复使用,所以在这里我将起始url设成了知乎主页。
之后就是种子用户的个人主页,知乎粉丝多的大V很多,但是关注多的人就比较难发现了,这里我选择了知乎的黄继新,联合创始人,想必关注了不少优质用户(≖‿≖)✧。
分析一下个人主页可知,个人主页由’https://www.zhihu.com/people/’ + 用户id 组成,我们要获取的信息是用callback回调函数(敲黑板!!划重点!!)的方式设计,这里一共设计了俩个回调函数:用户的关注列表和关注者的个人信息。
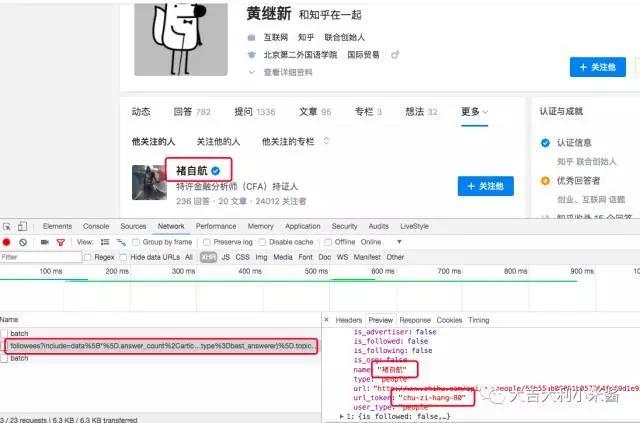
使用chrome浏览器查看上图的页面可知获取关注列表的url,以及关注者的用户id。
将鼠标放在用户名上。
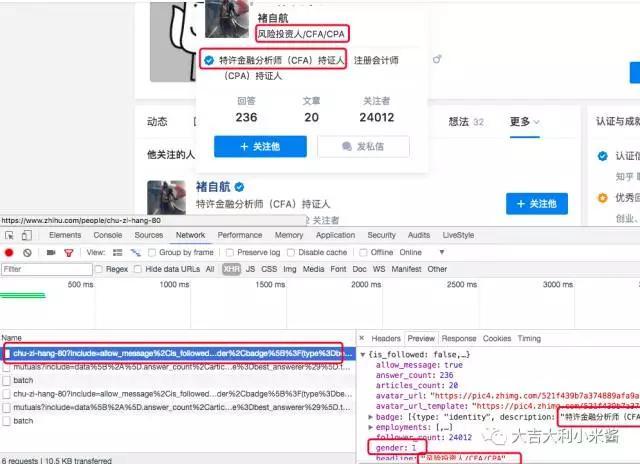
可以获得个人用户信息的url。分析url可知:
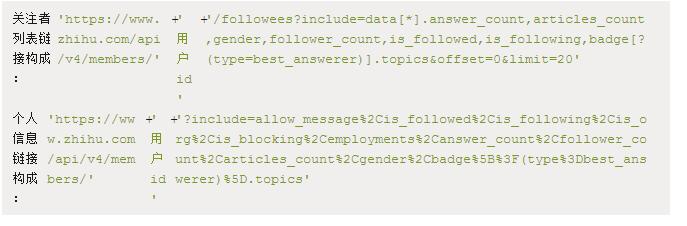
so,我们在上一节中创建的zhihuxjj.py文件中写入以下代码。


这里需要划重点的是yield的用法,以及item[‘name’],将爬取结果赋值给item,就是告诉系统,这是我们要选的菜…啊呸…要爬的目标数据。
4设置其他信息
在items.py文件中,按照spider中设置的目标数据item,添加对应的代码。

在pipeline.py中添加存入数据库的代码(数据库咋用上一篇文章写了哦~)。

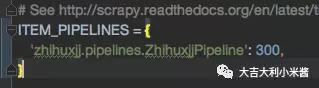
因为使用了pipeline.py,所以我们还需要再setting.py文件中,将ITEM_PIPELINE注释解除,这里起到连接两个文件的作用。
到这里,基本就都设置好了,程序基本上就可以跑了。不过因为scrapy是遵循robots.txt法则的,所以让我们来观察一下知乎的法则https://www.zhihu.com/robots.txt
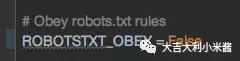
emmmmmmm,看完法则了吗,很好,然后我们在setting.py中,将ROBOTSTXT_OBEY 改成 False。(逃
好像…还忘了点什么,对了,忘记设置headers了。通用的设置headers的方法同样是在setting.py文件中,将DEFAULTREQUESTHEADERS的代码注释状态取消,并设置模拟浏览器头。知乎是要模拟登录的,如果使用游客方式登录,就需要添加authorization,至于这个authorization是如何获取的,我,就,不,告,诉,你(逃

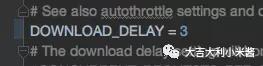
为了减少服务器压力&防止被封,解除DOWNLOADDELAY注释状态,这是设置下载延迟,将下载延迟设为3(robots法则里要求是10,但10实在太慢了_(:зゝ∠)知乎的程序员小哥哥看不见这句话看不见这句话…
写到这里你会发现,很多我们需要进行的操作,scrapy都已经写好了,只需要将注释去掉,再稍作修改,就可以实现功能了。scrapy框架还有很多功能,可以阅读官方文档了解。
5运行scrapy文件
写好scrapy程序后,我们可以在终端输入
运行文件。
但也可以在文件夹中添加main.py,并添加以下代码。
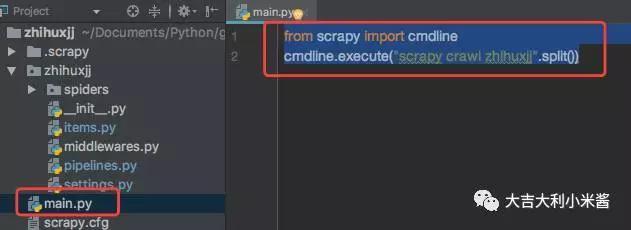
然后直接用pycharm运行main.py文件即可,然后我们就可以愉快的爬知乎用户啦~(小姐姐我来啦~
6查找小姐姐
经过了X天的运行,_(:зゝ∠)_爬到了7w条用户数据,爬取深度5。(这爬取速度让我觉得有必要上分布式爬虫了…这个改天再唠)
有了数据我们就可以选择,同城市的用户进行研究了……
先国际惯例的分析一下数据。
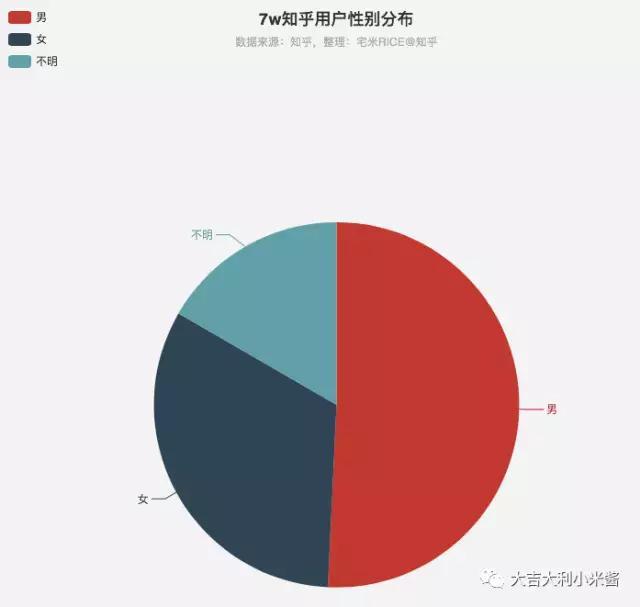
在7w用户中,明显男性超过了半数,标明自己是女性的用户只占了30%左右,还有一部分没有注明性别,优质的小姐姐还是稀缺资源呀~
再来看看小姐姐们都在哪个城市。(从7w用户中筛选出性别女且地址信息不为空的用户)
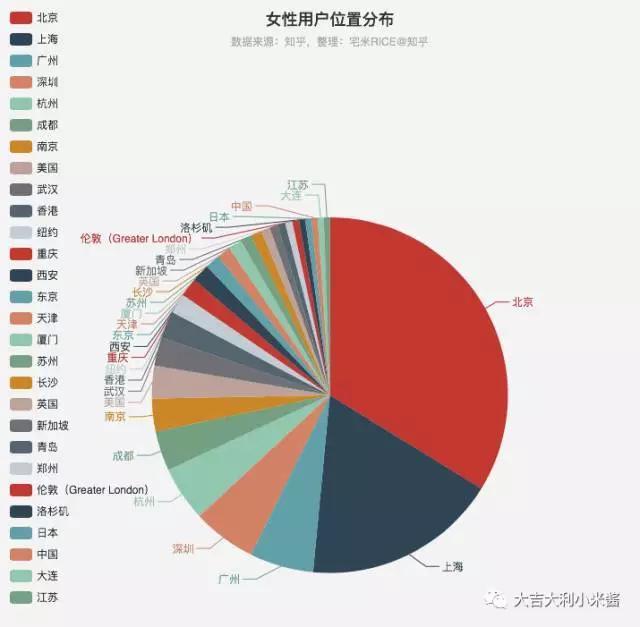
看来小姐姐们还是集中在北上广深杭的,所以想发现优质小姐姐的男孩纸们还是要向一线看齐啊,当然也不排除在二三线的小姐姐们没有标记处自己的地理位置。
emmmmm……这次的分析,就到此为止,你们可以去撩小姐姐们了。(逃
7研究小姐姐
意不意外?开不开心?这里还有一章。正所谓,授之以鱼,不如授之以渔;撒了心灵鸡汤,还得加一只心灵鸡腿;找到了小姐姐,我们还要了解小姐姐…………
让我再举个栗子~来研究一个小姐姐。(知乎名:动次,已获取小姐姐授权作为示例。)
让我们来爬一下她的动态,chrome右键检查翻network这些套路我就不说了,直接将研究目标。
赞同的答案和文章(了解小姐姐的兴趣点)
发布的答案和文章(了解小姐姐的世界观、人生观、价值观)
关注的问题和收藏夹(了解小姐姐需求)
提出的问题(了解小姐姐的疑惑)
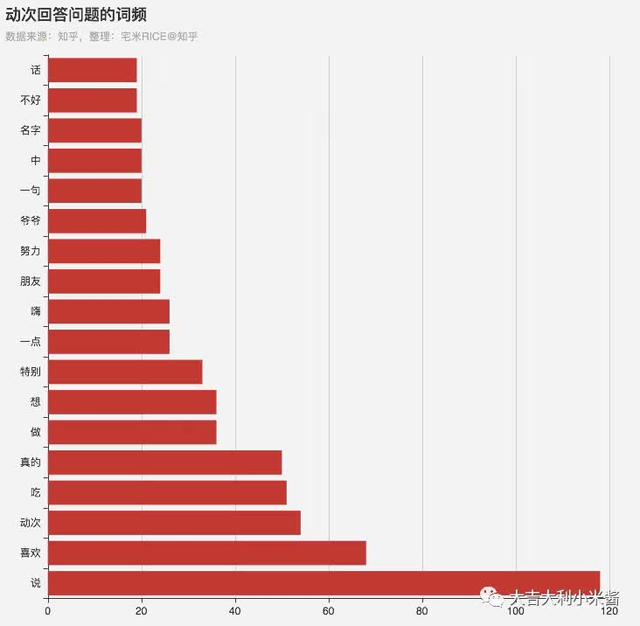
代码也不贴了,会放在gayhub的,来看一下输出。

因为你乎风格,所以对停用词进行了一些加工,添加了“如何”“看待”“体验”等词语,得到了小姐姐回答问题的词频。小姐姐的回答里出现了喜欢、朋友、爷爷等词语。
还有!!在关注、赞同和输出中,都有的词(✪ω✪)。(是不是可以靠美味捕获小姐姐呢……

再来一张刘看山背景的,答题词云。

8后记
本文涉及项目会持续更新,会将研究对象拓展至各平台,并进行后续优化,有兴趣的盆友可以关注gayhub项目。
本文作者:天善智能社区 光芒万丈的 大吉大利小米酱(公号)
欢迎关注天善智能,我们是专注于商业智能BI,人工智能AI,大数据分析与挖掘领域的垂直社区,学习,问答、求职一站式搞定!
转载请注明:徐自远的乱七八糟小站 » 【python程序员如何找到心仪小姐姐?】