北大新成果!首次成功地将CNN解码器用于代码生成|论文+代码
乾明 发自 凹非寺
量子位 报道 | 公众号 QbitAI
想象一下。
直接说你想干什么,就能生成相应的代码,会是多么“功德无量”一件事。
最直接受益的,就是程序员群体。
再也不用饱受“996”的折磨,也不用摸着不断后退的发际线而黯然神伤。

现在,这一天又近了一些。
最近,有一篇论文提出了一种基于语法的结构化CNN代码生成器,用《炉石传说》(HearthStone)基准数据集进行实验的结果表明:
准确性上明显优于以前最先进的方法5个百分点。

这篇论文目前已经被AAAI 2019收录。作者在论文中表示,他们是第一个成功地将CNN解码器用于代码生成的团队。
那么问题来了:
将CNN解码器用到代码生成,与之前的方法相比,到底有什么不同?
他们的模型又有什么特殊之处?效果到底好在哪?
下面,我们就来一一回答这些问题。
用CNN解码器生成代码的优势
基于自然语言描述生成代码,是挺难的一件事。
现在,通常用循环神经网络( RNN)进行序列生成,生成一首诗、进行机器翻译,都没问题。
但用在生成代码上,“麻烦”就来了。
程序中有很多结构化的信息,对程序建模很重要,但传统的Seq2Seq神经网络,并没有明确对程序结构进行建模。就比如下面这个Python的抽象语法树(AST)。
其中,n3和n6两个节点应该作为父子节点紧密交互,但如果使用传统的Seq2Seq方法,就会导致他们“父子离散”,彼此远离。
为了解决这个问题,很多人都开始想各种办法。其中一个关键方法就是用卷积神经网络(CNN),毕竟人家效率高,训练也简单。
这篇论文,就是一个代表。而且是第一个成功地将CNN解码器用于代码生成的,颇具分水岭意义。
在论文中,作者也介绍说,这比原来的RNN强多了。最主要的一点就是:
输入的程序一半都比自然语言句子长得多,就算RNN有LSTM(long short-term memory)的加持,也会一直受到依赖性问题的困扰。
而CNN就不一样了,可以通过滑动窗口(slide window)有效地捕捉不同区域的特征。
那,这个模型是怎么设计的呢?
模型设计
论文中介绍的CNN,是一种基于语法的结构化CNN。模型会根据AST的语法结构规则生成代码,而且还能预测语法规则的顺序,最终构建整个程序。
那,他们是如何预测语法规则的呢?主要基于三种类型的信息:
指定要生成的程序的源序列、之前预测的语法规则和已经生成的部分AST。
第一种很好理解,是编码器的输入。后两种的任务,就是使解码器能够自回归(autoregressiveness),并且解码器也以编码器为条件。
为了让这个结构化CNN更适合于代码生成,他们还设计了几个不同的组件:
第一,基于树的卷积思想,在AST结构上应用滑动窗口。然后,设计另一个CNN模块对部分AST中的节点进行前序遍历。这两种类型的CNN不仅捕获序列中的“邻居”信息,还捕获树结构中的“邻居”信息。
第二,将另一个CNN模块应用于要生成的节点的祖先,让网络知道,在某个步骤中在哪里生成。从而增强“自回归性”。
第三,设计专门的注意力机制,将CNN的特征与不同的CNN模块进行交互。此外,作者表示,在代码生成过程中考虑范围名称(例如,函数和方法名称)是有用的,所以就使用了这样的信息当作几个池层的控制器。
于是,就得出了这样的一个模型。
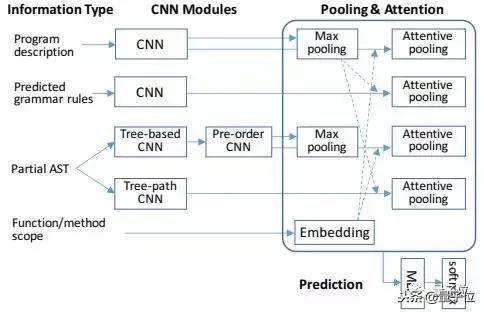
△模型概述。虚线箭头表示注意力控制器。
这个模型,效果到底怎么样呢?
模型效果
作者用两个任务评估了模型的效果。一个是生成《炉石传说》游戏的Python代码,一个是用于语义解析的可执行逻辑形式生成。
生成《炉石传说》的Python代码
这个任务使用的是《炉石传说》基准数据集,一共包括665张不同卡牌。
输入是字段的半结构化描述,例如卡牌名、成本、攻击、描述和其他属性;

要输出的是实现卡牌功能的Python代码片段。

通过准确性与BLEU分数来测量模型的质量。在准确性方面,作者追踪了之前大多数研究相同的方法,根据字符串匹配计算精度(表示为StrAcc )。
有时候,几个生成的程序使用了不同的变量名,但功能是正确的,这就需要人为去调整。并用Acc +表示人为调整的精度。
最后,用BLEU值评估生成的代码的质量。
结果如下图所示:

在准确性和BLEU分数方面,都优于之前的所有模型。StrAcc比之前最好的模型高出了5个百分点。经过人为调整后的Acc+达到了30.3%,增加了3个百分点,之前的模型最好的效果提高了2%。
作者认为,这显示了他们方法的有效性。至于之前的模型跟他们的模型在BLEU分数上的相似性,作者解释道,代码生成还是要看细节。
语义解析任务
在语义解析任务中,使用的两个语义解析数据集( ATIS和JOBS ),其中输入是自然语言句子。ATIS的输出是λ演算形式,而对于JOBS,输出的是Prolog形式。

在这两个数据集中,论文中提出的模型并没有展现出什么优势。
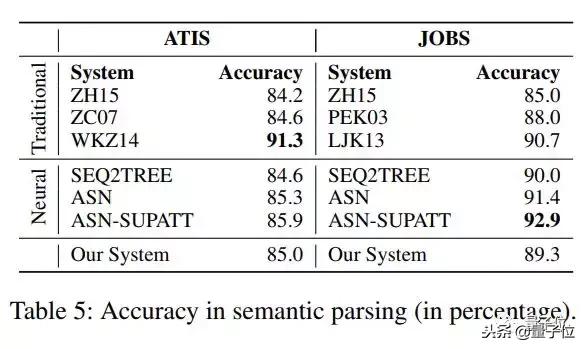
作者在论文中表示,这可能是因为语义解析的逻辑形式通常很短,因此,RNN和CNN都可以生成逻辑形式。
不过,这个实验也证明了用CNN进行代码生成的普遍性和灵活性。毕竟,整个模型基本上是为长程序设计的,在语义解析方面也很好。
关于作者
按照署名顺序,作者分别为孙泽宇、朱琪豪、牟力立、熊英飞、李戈、张路,其中其中熊英飞为通讯作者。作者单位为北京大学信息科学技术学院。

传送门
论文:
https://arxiv.org/abs/1811.06837
GitHub:
https://github.com/zysszy/GrammarCNN
— 完 —
诚挚招聘
量子位正在招募编辑/记者,工作地点在北京中关村。期待有才气、有热情的同学加入我们!相关细节,请在量子位公众号(QbitAI)对话界面,回复“招聘”两个字。
量子位 QbitAI · 头条号签约作者
վ’ᴗ’ ի 追踪AI技术和产品新动态
北大新成果!首次成功地将CNN解码器用于代码生成|论文+代码http://t.jinritoutiao.js.cn/RTjN1E/



