学界|论文撞车英伟达,一作「哭晕在厕所」,英伟达:要不要来实习?
机器之心报道
参与:刘晓坤
英伟达率先发表了相似的工作,让千里之外的几位研究者一脸懵逼,于是决定公布代码以示没有剽窃。
来自韩国首尔大学的研究者近期发布了一篇利用基于流的生成模型进行实时的语音合成的研究 FloWaveNet。但奇怪的是,他们的论文中并没有语音合成中典型的人类评估 MOS(平均意见分数)指标,甚至一个实验图标都没有。原因很有趣:他们发现英伟达在前几天发布的论文 WaveGlow 竟然和 FloWaveNet 在主要思想上几乎完全相同,都提出了基于流的语音合成方法。
为此,论文二作赶紧将代码、生成样本以及 arXiv 手稿放了出来,并在 Reddit 上公告,然后苦苦思索如何安慰在实验室角落哭泣的一作。
Reddit 网友纷纷伸出援手安慰一作:
你和领域巨头的想法碰撞到一起了,这是好事不是吗?
WaveGlow 仍然只是一篇 arXiv 论文,所以不用担心,顺便提一下,Nice Work!
我的朋友,深有同感。我几周前和谷歌撞车,几个月前还和 DeepMind 撞车。我是搞人工智能的,又不是开碰碰车的。我在提交关于音频生成的论文之前,谷歌发布了类似的工作 Nsynth。我使用了简单的基于自编码器的生成模型,而谷歌的 Nsynth 基本思想一样,但规模大得多,并且能结合其它很多先进的方法。作为个人很难和拥有更多工程师、研究员和资源的巨头竞争。这是一个竞争激烈的行业,很难做出完全独特的研究。但是没关系,做好你自己的研究,并基于此不断地改进,也是我们需要的研究态度。
英伟达也开源了 WaveGlow 的代码,所以你们可以更细致地比较你们研究之间的不同。
- WaveGlow:https://github.com/NVIDIA/waveglow
- FloWaveNet:https://github.com/ksw0306/FloWaveNet
- FloWaveNet 生成样本地址:https://drive.google.com/drive/folders/1RPo8e35lhqwOrMrBf1cVXqnF9hzxsunU
这两篇论文到底有多相似?我们一起感受一下。
论文:FloWaveNet : A Generative Flow for Raw Audio
论文地址:https://arxiv.org/pdf/1811.02155.pdf
摘要:大多数文本到语音的架构使用了 WaveNet 语音编码器来合成高保真的音频波形,但由于自回归采样太慢,其在实际应用中存在局限性。人们近期提出的 Parallel WaveNet 通过整合逆向自回归流(IAF)到并行采样中实现了实时的音频合成。然而,Parallel WaveNet 需要两个阶段的训练流水线,其中设计一个训练良好的教师网络,并且如果仅使用 probability distillation 训练容易导致模式崩溃。FloWaveNet 仅需要单个最大似然损失函数,而不需要任何其它辅助项,并且由于基于流的变换的使用,其内在地是并行的。该模型可以高效地实时采样原始音频,其语音清晰度和 WaveNet 以及 ClariNet 相当。
 图 1:FloWaveNet 模型图示。左图:FloWaveNet 的整个前向传播过程,由 N 个上下文模块构成。中间:流操作的抽象图示。右图:affine coupling 操作细节。
图 1:FloWaveNet 模型图示。左图:FloWaveNet 的整个前向传播过程,由 N 个上下文模块构成。中间:流操作的抽象图示。右图:affine coupling 操作细节。
论文:WAVEGLOW: A FLOW-BASED GENERATIVE NETWORK FOR SPEECH SYNTHESIS
论文地址:https://arxiv.org/pdf/1811.00002.pdf
摘要:在本文中我们提出了 WaveGlow,这是一个基于流的可以从梅尔谱图生成高质量语音的网络。WaveGlow 结合了 Glow 和 WaveNet 的思想,以提供快速、高效和高质量的音频合成,不需要使用自回归。WaveGlow 仅使用单个网络实现,用单个损失函数训练:最大化训练数据的似然度,这使得训练过程简单而稳定。平均意见分数评估表明该方法能生成和最佳的 WaveNet 实现质量相当的结果。
 图 1: WaveGlow 模型图示。
图 1: WaveGlow 模型图示。
 表 1:WaveGlow 平均意见分数评估结果。
表 1:WaveGlow 平均意见分数评估结果。
我们大致能看到:FloWaveNet 和 WaveNet 都采用了基于流的生成模型思想;摒弃了自回归;摒弃两阶段训练过程;不需要额外辅助损失项;只需要似然度作为损失函数;只需要一个网络;能生成和 WaveNet 质量相当的语音…… 如此正面刚的撞车,难怪一作疼的流泪。
当然,通过后面对基于流的生成模型的解释,我们能发现,他们的研究的大部分重合点就是对这种模型的采用,其它的都是连带效应。这到底是什么样的生成模型,可以一己之力扭转乾坤,还让相隔千里的 AI 研究者垂涎仰望,不觉撞车?
其实,最惊喜/惊奇的援手还是来自他们的冤大头——英伟达。WaveGlow 的作者之一 Bryan Catanzaro 在 Reddit 上称赞了他们的工作,还邀请他们去实习,在语音生成研究上合作……
 学术界也是充满了戏剧性~
学术界也是充满了戏剧性~
为什么要选择基于流的生成模型
基于流的生成模型是继 GAN 和 VAE 之后的第三种生成模型,但这只是很多人的初步印象。其实这种模型在 2014 年就被提出,比 GAN 还早,但仅在近期由于 OpenAI 提出了 Glow 模型才被人注意到。基于流的生成模型具有可逆和内在并行性的优点。
实际上,生成模型可以分为四个类别:自回归、GAN、VAE、flow-based(基于流)。以图像生成为例,自回归模型需要逐像素地生成整张图像,每次新生成的像素会作为生成下一个像素的输入。这种模型计算成本高,并行性很差,在大规模生成任务中性能有限。上述的 WaveNet 就是一种自回归模型,最大的缺点就是慢。其它典型的自回归模型还有 PixelRNN 和 PixelCNN。此外,自回归模型也是可逆的。相对于自回归模型,基于流的生成模型的优势是其并行性。
相对于 VAE 和 GAN,基于流的生成模型的优势是:可以用隐变量精确地建模真实数据的分布,即精确估计对数似然,得益于其可逆性。而 VAE 尽管是隐变量模型,但只能推断真实分布的近似值,而隐变量分布与真实分布之间的 gap 是不可度量的,这也是 VAE 的生成图像模糊的原因。GAN 是一种学习范式,并不特定于某种模型架构,并且由于其存在两个模型互相博弈的特点,理论的近似极限也是无法确定的。基于流的生成模型却可以在理论上保证可以完全逼近真实的数据分布。
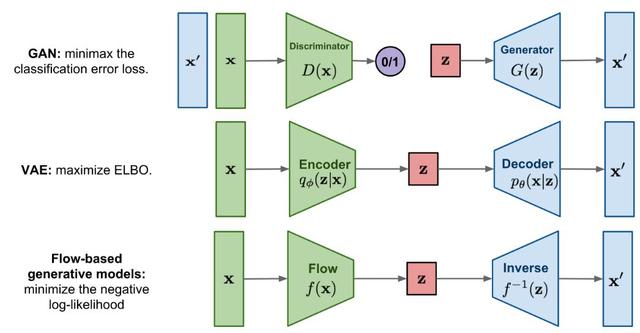 有这么多的优点,以一己之力轻松克服 WaveNet 的缺点也不是什么难事了,至于更深入的细节,还请参阅原论文。
有这么多的优点,以一己之力轻松克服 WaveNet 的缺点也不是什么难事了,至于更深入的细节,还请参阅原论文。
基于流的生成模型可以大致理解为:它希望将数据表示成简单的隐变量分布,并可以从该分布中完全还原真实数据的分布。也就是说,它要学习的是一个可逆函数。利用雅可比矩阵的这个性质:一个函数的雅可比矩阵的逆矩阵,是该函数的反函数的雅可比矩阵,NICE 和 RealNVP 提出了通过顺序的可逆函数变换,将简单分布逐步还原复杂的真实数据分布的归一化流过程,如下图所示。后来在 Glow 中提出用 1×1 可逆卷积替换 NICE 和 RealNVP 中的可逆变换。
 由于可以进行精确的密度估计,基于流的生成模型在很多下游任务中具备天然优势,例如数据补全、数据插值、新数据生成等。
由于可以进行精确的密度估计,基于流的生成模型在很多下游任务中具备天然优势,例如数据补全、数据插值、新数据生成等。
在 Glow 中,这种模型展示了其在图像生成和图像属性操控上的潜力:
 Glow 实现的人脸图像属性操作。训练过程中没有给模型提供属性标签,但它学习了一个潜在空间,其中的特定方向对应于胡须密度、年龄、头发颜色等属性的变化。
Glow 实现的人脸图像属性操作。训练过程中没有给模型提供属性标签,但它学习了一个潜在空间,其中的特定方向对应于胡须密度、年龄、头发颜色等属性的变化。
这类模型是不是能超越 GAN 不好说,但相对于 VAE 还是有很明显的优势,在未来的生成模型研究领域中也是非常值得期待和关注的方向。
学界|论文撞车英伟达,一作「哭晕在厕所」,英伟达:要不要来实习?http://t.jinritoutiao.js.cn/RxX7V3/



