谷歌TPU与GPU、FPGA有何差别?
导读: 在图像语音识别、无人驾驶等人工智能领域的运用层面,图形处理器 (GPU)正迅速扩大市场占比,而谷歌专门为人工智能研发的TPU则被视为GPU的竞争对手。TPU是什么?它怎么就被视为GPU的竞争对手了呢?
目前,Google、Facebook、Microsoft、百度等科技巨头纷纷涉足人工智能。市场对人工智能的热情持续高涨,特别是硬件领域。有分析师指出,人工智能将成为下一个科技风口,主要的就包括硬件。
在AlphaGo打败李世乭的时候,或许我们都曾想过,它怎么能这么聪明,是什么支撑了一个机器人的强大快速的运算能力呢?
没错,关键就是谷歌的TPU。在图像语音识别、无人驾驶等人工智能领域的运用层面,图形处理器 (GPU)正迅速扩大市场占比,而谷歌专门为人工智能研发的TPU则被视为GPU的竞争对手。TPU是什么?它怎么就被视为GPU的竞争对手了呢?
人工智能各要素的概念
人工智能的实现三s需要依赖三个要素:算法是核心,硬件和数据是基础。
算法主要分为为工程学法和模拟法。工程学方法是采用传统的编程技术,利用大量数据处理经验改进提升算法性能;模拟法则是模仿人类或其他生物所用的方法或者技能,提升算法性能,例如遗传算法和神经网络。
硬件方面,目前主要是使用 GPU 并行计算神经网络。
下图就可体现这些要素之间的关系:
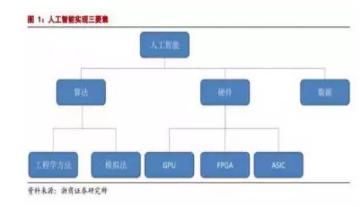
从产业结构来讲,人工智能生态分为基础、技术、应用三层。
基础层包括数据资源和计算能力;技术层包括算法、模型及应用开发;应用层包括人工智能+各行业(领域),比如在互联网、金融、汽车、游戏等产业应用的语音识别、人脸识别、无人机、机器人、无人驾驶等功能。
什么是TPU
TPU,即谷歌的张量处理器——Tensor Processing Unit。
据谷歌工程师Norm Jouppi介绍,TPU是一款为机器学习而定制的芯片,经过了专门深度机器学习方面的训练,它有更高效能(每瓦计算能力)。大致上,相对于现在的处理器有7年的领先优势,宽容度更高,每秒在芯片中可以挤出更多的操作时间,使用更复杂和强大的机器学习模型,将之更快的部署,用户也会更加迅速地获得更智能的结果。谷歌专门为人工智能研发的TPU被疑将对GPU构成威胁。不过谷歌表示,其研发的TPU不会直接与英特尔或NVIDIA进行竞争。
TPU最新的表现正是人工智能与人类顶级围棋手的那场比赛。在AlphaGo战胜李世石的系列赛中,TPU能让AlphaGo“思考”更快,“想”到更多棋招、更好地预判局势。
深度学习的运算流程
对于任何运算来说,更换新硬件无非是为了两个目的:更快的速度和更低的能耗。而深度学习这个看起来玄乎的词语,究其本质也不过是大量的运算。我们都知道那句老话:万能工具的效率永远比不上专用工具。无论是CPU、GPU还是FPGA,其属性都算是一种通用工具。因为它们都可以应付许多不同的任务。而专用的TPU自然从道理上来说就应该会比前面几种硬件的效率都要高。这里的效率高,既是指速度更快,也是指能耗会更低。
但我们不能光讲道理,也要摆出一些数据。实际上,Xilinx曾经表示在特定的FPGA开发环境下深度学习的能效比会达到CPU/GPU架构的25倍,不是一倍两倍, 是25倍!同学们可以拿出纸和笔了,让我们举一个实际的例子来讲讲这种效率提升的原因:以在深度神经网络(DNN)上进行的图像识别为例子,网络的整个结构大致是这样的:
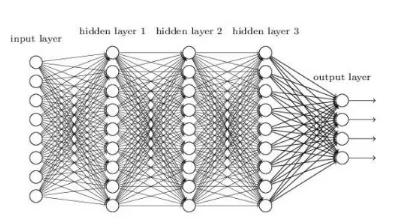
其中除输入层是用来将图像的特征提取为函数、输出层用来输出结果外,其他的隐层都是用来识别、分析图像的特征的。当一幅图被输入时,第一层隐层会首先对其进行逐像素的分析。此时的分析会首先提取出图像的一些大致特征,如一些粗略的线条、色块等。如果输入的是一张人脸的图像,则首先获得的会是一些倾斜的颜色变换。
第一层的节点会根据自己对所得信号的分析结果决定是否要向下一层输出信号。而所谓的分析过程,从数学上来看就是每个隐层中的节点通过特定的函数来处理相邻节点传来的带权重值的数据。并决定是否向下一层输出结果,通常每一层分析完成后便有些节点不会再向下一层输出数据,而当下一层接收到上一层的数据的时候,便能在此基础上识别出一些更复杂的特征,如眼睛、嘴巴和鼻子等,
逐次增加辨识度之后,在最高一层,算法会完成对面部所有特征的识别,并在输出层给出一个结果判断。基于不同的应用,这个结果可能有不同的表现。比如分辨出这是谁的脸。
谷歌的TPU对其他厂商有什么影响?
在TPU发布之前,这个领域内的大多数厂商都在同时利用FPGA和GPU来改进训练自己的神经网络算法。NVIDIA则是其中比较特殊的一家:它是世界最大的GPU制造商之一,一直在不遗余力的推广自己的产品在深度学习领域的应用。但其实GPU的设计初衷主要并不是进行神经网络运算,而是图像处理。更多是由于其特殊的构造碰巧也比较适用于神经网络运算罢了,尽管NVIDIA也在推出一些自有的深度学习算法,但由于GPU自身的特性一直还是被FPGA压着一头。而此次的TPU会让这个市场上凭空再多一个竞争对手,因此我认为这款TPU对NVIDIA的影响是最大的。
另一些在人工智能领域已经与谷歌有着相似程度的成就的公司则预计不会受到太多影响,如微软和苹果。微软一直在探索FPGA对人工智能相关运算的加速,并且有自己开发的算法。经过长时间的调试,基于FPGA的这些算法也未必会在最终表现上输给谷歌多少。如果微软愿意,其实它也可以随时开始开发一款自己的人工智能芯片,毕竟微软也是自己开发过很多专属硬件的了。
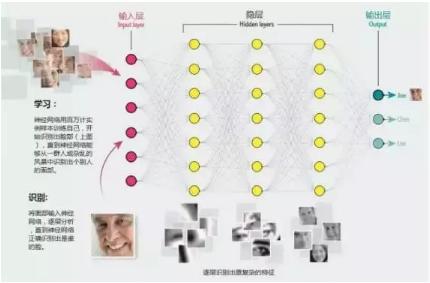
不难想象,由于每一层分析的时候都要对极大量的数据进行运算,因此对处理器的计算性能要求极高。这时CPU的短板就明显的体现出来了,在多年的演化中,CPU依据其定位需要不断强化了进行逻辑运算(If else之类)的能力。相对的却没有提高多少纯粹的计算能力。因此CPU在面对如此大量的计算的时候难免会感到吃力。很自然的,人们就想到用GPU和FPGA去计算了。
目前的深度学习硬件设备还有哪些?与传统CPU有何差异?
一.FPGA
FPGA最初是从专用集成电路发展起来的半定制化的可编程电路,它无法像CPU一样灵活处理没有被编程过的指令,但是可以根据一个固定的模式来处理输入的数据然后输出,也就是说不同的编程数据在同一片FPGA可以产生不同的电路功能,灵活性及适应性很强,因此它可以作为一种用以实现特殊任务的可再编程芯片应用与机器学习中。
譬如百度的机器学习硬件系统就是用FPGA打造了AI专有芯片,制成了AI专有芯片版百度大脑——FPGA版百度大脑,而后逐步应用在百度产品的大规模部署中,包括语音识别、广告点击率预估模型等。在百度的深度学习应用中,FPGA相比相同性能水平的硬件系统消耗能率更低,将其安装在刀片式服务器上,可以完全由主板上的PCI Express总线供电,并且使用FPGA可以将一个计算得到的结果直接反馈到下一个,不需要临时保存在主存储器,所以存储带宽要求也在相应降低。
二.GPU
英伟达(NVIDIA)制造的图形处理器 (GPU)专门用于在个人电脑、工作站、游戏机和一些移动设备上进行图像运算工作,是显示卡的“心脏”。
1.GPU与CPU的区别
本身架构方式和运算目的的不同,导致英特尔制造的CPU 和 GPU之间有所区别。
GPU之所以能够迅速发展,主要原因是GPU针对密集的、高并行的计算,这正是图像渲染所需要的,因此 GPU 设计了更多的晶体管专用于数据处理,而非数据高速缓存和流控制。
与CPU相比,GPU拥有更多的处理单元。GPU和CPU 上大部分面积都被缓存所占据有所不同,诸如GTX 200 GPU之类的核心内很大一部分面积都作为计算之用。如果用具体数据表示,大约估计在 CPU 上有 20%的晶体管是用作运算之用的,而(GTX 200)GPU 上有 80%的晶体管用作运算:
GPU 的处理核心 SP 基于传统的处理器核心设计,能够进行整数,浮点计算,逻辑运算等操作,从硬体设计上看就是一种完全为多线程设计的处理核心,拥有复数的管线平台设计,完全胜任每线程处理单指令的工作。
GPU 处理的首要目标是运算以及数据吞吐量,而 CPU 内部晶体管的首要目的是降低处理的延时以及保持管线繁忙,这也决定了 GPU 在密集型计算方面比起 CPU 来更有优势。
2.GPU+CPU异构运算
就目前来看,GPU不是完全代替CPU,而是两者分工合作。
在 GPU 计算中 CPU 和 GPU 之间是相连的,而且是一个异构的计算环境。这就意味着应用程序当中,顺序执行这一部分的代码是在 CPU 里面进行执行的,而并行的也就是计算密集这一部分是在 GPU 里面进行。
异构运算(heterogeneous computing)是通过使用计算机上的主要处理器,如CPU 以及 GPU 来让程序得到更高的运算性能。一般来说,CPU 由于在分支处理以及随机内存读取方面有优势,在处理串联工作方面较强。在另一方面,GPU 由于其特殊的核心设计,在处理大量有浮点运算的并行运算时候有着天然的优势。完全使用计算机性能实际上就是使用 CPU 来做串联工作,而 GPU 负责并行运算,异构运算就是“使用合适的工具做合适的事情”。
只有很少的程序使用纯粹的串联或者并行的,大部分程序同时需要两种运算形式。编译器、文字处理软件、浏览器、e-mail 客户端等都是典型的串联运算形式的程序。而视频播放,视频压制,图片处理,科学运算,物理模拟以及 3D 图形处理(Ray tracing 及光栅化)这类型的应用就是典型的并行处理程序。
三.FPGA和GPU
实际的计算能力除了和硬件的计算速度有关,也同硬件能支持的指令有关。我们知道将某些较高阶的运算分解成低阶运算时会导致计算的效率下降。但如果硬件本身就支持这种高阶运算,就无需再将其分解了。可以节省很多时间和资源。
FPGA和GPU内都有大量的计算单元,因此它们的计算能力都很强。在进行神经网络运算的时候速度会比CPU快很多,但两者之间仍存在一些差别。GPU出厂后由于架构固定硬件原生支持的指令其实就固定了。如果神经网络运算中有GPU不支持的指令,比如,如果一个GPU只支持加减乘除,而我们的算法需要其进行矩阵向量乘法或者卷积这样的运算,GPU就无法直接实现,就只能通过软件模拟的方法如用加法和乘法运算的循环来实现,速度会比编程后的FPGA慢一些。而对于一块FPGA来说,如果FPGA没有标准的“卷积”指令,开发者可以在FPGA的硬件电路里“现场编程”出来。相当于通过改变FPGA的硬件结构让FPGA可以原生支持卷积运算,因此效率会比GPU更高。
其实讲到这里,我们已经比较接近谷歌开发TPU的原因了。TPU是一种ASIC,这是一种与FPGA类似,但不存在可定制性的专用芯片,如同谷歌描述的一样,是专为它的深度学习语言Tensor Flow开发的一种芯片。因为是专为Tensor Flow所准备,因此谷歌也不需要它拥有任何可定制性了,只要能完美支持Tensor Flow需要的所有指令即可。而同时,TPU运行Tensor Flow的效率无疑会是所有设备中最高的。这就是谷歌开发TPU的最显而易见的目的:追求极致的效率。
一场人工智能芯片之争在谷歌发布这款专用机机器学习算法的专用芯片-TPU之后正式拉开序幕。谁能走在人工智能的前面,谁能主导未来人工智能发展趋势,掌握核心技术,谁就能赢得这场战争的胜利吧!
谷歌TPU与GPU、FPGA有何差别?http://t.jinritoutiao.js.cn/dgkojE/
转载请注明:徐自远的乱七八糟小站 » 谷歌TPU与GPU、FPGA有何差别?



