面向软件工程师的卡尔曼滤波器
面向软件工程师的卡尔曼滤波器

Photo by Clem Onojeghuo on Unsplash
与我的朋友交谈时,我经常听到:”哦,卡尔曼过滤器……我通常学习它们,理解它们,然后我忘记了一切”。 好吧,考虑到卡尔曼滤波器(KF)是世界上应用最广泛的算法之一(如果环顾四周,您80%的技术可能已经在内部运行某种KF),让我们尝试将其弄清楚 一劳永逸。
在这篇文章的结尾,您将对KF的工作原理,其背后的想法,为什么需要多个变体以及最常见的变体有一个直观而详细的了解。
状态估计
KF是所谓的状态估计算法的一部分。 什么是状态估计? 假设您有一个系统(让我们将其视为黑匣子)。 黑匣子可以是任何东西:您的风扇,化学系统,移动机器人。 对于这些系统中的每一个,我们都可以定义一个状态。 状态是变量的向量,我们很想知道它们,它们可以描述系统在特定时间点的”状态”(这就是为什么将其称为状态)。 “可以描述”是什么意思? 这意味着,如果您知道在时间k处的状态向量和提供给系统的输入,则可以(同时使用系统工作原理的一些知识)知道在时间k + 1处的系统状态。
例如,假设我们有一个移动的机器人,并且我们关心知道它在空间中的位置(而不关心它的方向)。 如果我们将状态定义为机器人的位置(x,y)及其速度(v_x,v_y),并且我们有一个关于机器人如何运动的模型,那么就足以确定机器人的位置和位置。 下一次瞬间。
因此,状态估计算法估计系统的状态。 为什么要估算呢? 因为在现实生活中,外部观察者永远无法访问系统的真实状态。 通常有两种情况:您可以测量状态,但是测量结果会受到噪声的影响(每个传感器只能产生一定精度的读数,可能对您来说还不够),或者您无法直接测量状态。 一个示例可能是使用GPS计算上述移动机器人的位置(我们将位置确定为状态的一部分),这可能会给您带来多达10米的测量误差,对于您可能想到的任何应用程序来说,这可能都不足够 。
通常,在进行状态估计时,您可以放心地假设您知道系统的输入(因为是您提供的)和输出。 由于测量了输出,因此它也会受到一定的测量噪声的影响。 据此,我们将状态估计器定义为一个系统,该系统接收要估计其状态的系统的输入和输出,并输出系统状态的估计值。传统上,状态用x表示,输出用 y或z,u是输入,而tilde_x是估计状态。

System and State Estimator block diagram.
卡尔曼滤波器
您可能已经注意到,我们已经讨论了一些有关错误的内容:
· 您可以测量系统的输出,但是传感器会给出测量误差
· 您可以估计状态,但是作为状态估计它具有一定的置信度。
除此之外,我说过,您需要某种系统知识,您需要了解系统”行为”的模型(稍后会详细介绍),您的模型当然并不完美,因此您将拥有 另一个错误。
在KF中,您可以使用高斯分布来处理所有这些不确定性。 高斯分布是表示您不确定的事物的一种好方法。 您当前的信念可以用分布的均值表示,而标准差可以说明您对信念的信心。
在KF中:
· 您的估计状态将是具有一定均值和协方差的高斯随机变量(它将告诉我们该算法”信任”当前估计的程度)
· 您对原始系统的输出测量的不确定性将用均值为0和一定协方差的随机变量表示(这将告诉我们我们对测量本身的信任程度)
· 系统模型的不确定性将由均值为0和一定协方差的随机变量表示(这将告诉我们我们对所使用模型的信任程度)。
让我们举一些例子来了解其背后的想法。
· 不良的模型,好的传感器让我们再次假设您想跟踪机器人的位置,并且您在传感器上花费了很多钱,它们为您提供厘米级的精度。 另一方面,您根本不喜欢机器人技术,您在Google上搜索了一下,然后发现了一个非常基本的运动模型:随机游动(基本上是一个仅由噪声给出运动的粒子)。 很明显,您的模型不是很好,不能真正被信任,而您的测量结果却很好。 在这种情况下,您可能将使用非常窄的高斯分布(小方差)来建模测量噪声,而使用非常宽的高斯分布(大方差)来建模不确定性。
· 传感器质量差,模型好如果传感器质量不佳(例如GPS),但您花费大量时间对系统进行建模,则情况恰好相反。 在这种情况下,您可能将使用非常窄的高斯分布(小方差)来建模模型不确定性,而使用非常宽的高斯分布(大方差)来建模噪声。

Wide variance vs. small variance Gaussian distributions.
估计状态不确定性如何?KF将根据估计过程中发生的事情进行更新,您唯一要做的就是将其初始化为足够好的值。 “足够好”取决于您的应用程序,您的传感器,您的模型等。通常,KF需要一点时间才能收敛到正确的估计值。
KF如何运作?
如前所述,要让KF正常工作,您需要对系统有”一定的了解”(”不确定”,即不完美的模型)。 特别是对于KF,您需要两个模型:
· 状态转换模型:某些函数,在时间k给出状态和输入,可以在时间k + 1给出状态。
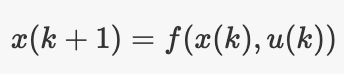
· 测量模型:给定时间为k的某个函数,可以为您提供同一时间的测量结果
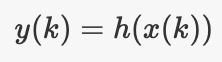
稍后,我们将了解为什么需要这些功能,让我们首先看一些示例以了解它们的含义。
状态转换模型,此模型告诉您系统如何随时间演变(如果您还记得的话,我们之前曾谈到状态如何具有足够的描述性以及时推断系统行为)。这在很大程度上取决于系统本身以及您对系统的关心。如果您不知道如何对系统建模,则可以使用一些Google搜索来提供帮助。对于运动的物体(如果以适当的采样率测量),可以使用恒速模型(假定物体以恒定的速度运动),对于车辆,可以使用单轮脚踏车模型,等等……让我们假设一种或另一种,我们建立了一个模型。我们在这里做出一个重要的假设,这对于KF的工作是必要的:您的当前状态仅取决于先例。换句话说,系统状态的”历史”浓缩为先前的状态,也就是说,给定先前的状态,每个状态都独立于过去。这也称为马尔可夫假设。如果这不成立,就不能仅凭先例来表达当前状态。
度量模型度量模型告诉您如何将输出(可以度量)和状态联系在一起。 直观上,您需要这样做,因为您知道测量的输出,并且想要在估计期间从中推断出状态。 同样,此模型因情况而异。 例如,在移动机器人示例中,如果您关心位置并且拥有GPS,则您的模型就是身份功能,因为您已经在测量状态的嘈杂版本。
每个步骤的数学公式和解释如下:
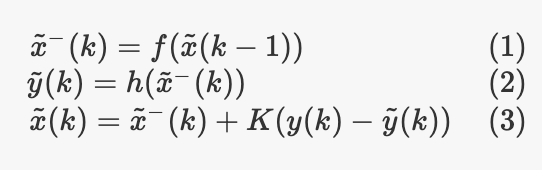
那么,KF实际如何运作? 该算法分两个步骤工作,称为预测和更新。 假设我们在时间k处,并且那时我们有估计状态。 首先,我们使用状态转换模型,并使估计状态演化到下一个时刻(1)。 这相当于说:鉴于我当前对状态的信念,我所拥有的输入以及对系统的了解,我希望我的下一个状态是这样。 这是预测步骤。
现在,由于我们还具有输出和测量模型,因此我们实际上可以使用实际测量”校正”预测。 在更新步骤中,我们采用预期状态,我们计算输出(使用测量模型)(2),然后将其与实际测量的输出进行比较。 然后,我们以”智能方式”使用两者之间的差异来校正状态的估计(3)。
通常,我们用顶点-表示校正前来自预测步骤的状态估计。 K称为卡尔曼增益。 那才是真正的聪明之处:K取决于我们对测量的信任程度,我们对当前估计的信任程度(这取决于我们对模型的信任程度),并根据此信息K”决定”了预测的估计量 用测量值校正。 如果我们的测量噪声”小”,而不是我们相信来自预测步骤的估计,那么我们将使用该测量对估计进行很多校正,如果相反,那么我们将对其进行最小限度的校正。
注意:为简单起见,我写方程式时就好像在处理普通变量一样,但是您必须考虑到在每一步中我们都在处理随机的高斯变量,因此我们还需要通过函数传播 变量的协方差,而不仅仅是均值。d
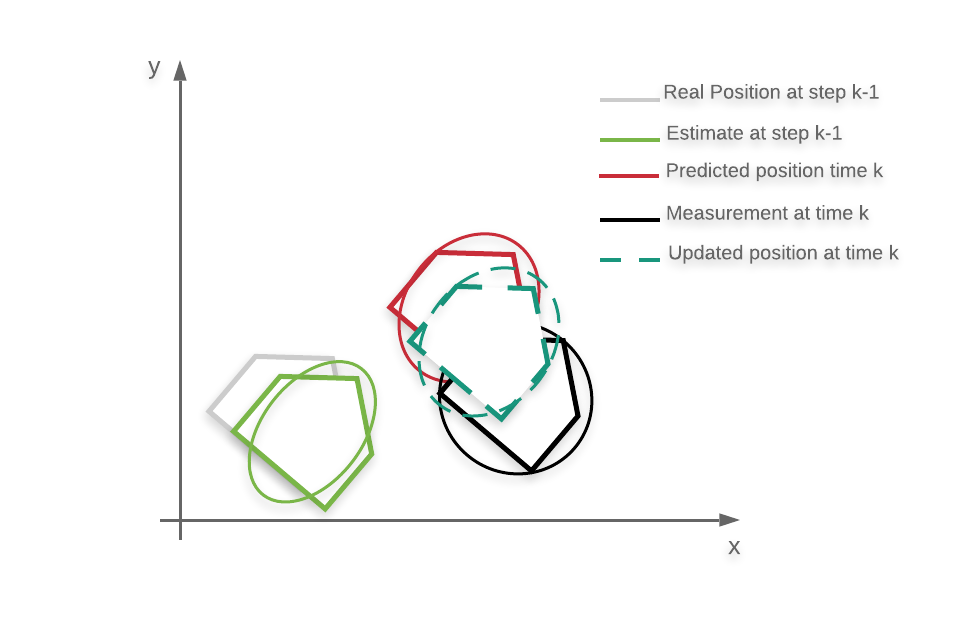
Example of real position and estimation at each step of the KF algorithm.
肯德基家族
根据所使用的模型类型(状态转换和测量),可以将KF分为两个大类:如果模型是线性的,则具有线性卡尔曼滤波器,而如果它们是非线性的,则具有非线性卡尔曼滤波器。
为什么要区分? 好吧,KF假设您的变量是高斯变量,当通过线性函数传递时,高斯变量仍然是高斯变量,如果通过非线性函数传递,则不正确。 这打破了卡尔曼假设,因此我们需要找到解决方法。
从历史上看,人们发现了两种主要方法:用模型作弊和用数据作弊。如果您对模型作弊,则基本上可以使当前估计值周围的非线性函数线性化,从而使您回到可以工作的线性情况。这种方法称为扩展卡尔曼滤波器(EKF)。该方法的主要缺点是您必须能够计算f()和h()的雅可比行列式。另外,如果您使用数据作弊,则可以使用非线性函数,但随后尝试对非高斯分布进行”高斯化”(如果该词甚至存在)。这是通过称为”无味转换”的智能采样技术完成的。通过此变换,您可以(均值)和均方差来描述一个分布(在前两个时刻仅完全描述了高斯分布)。这种方法称为无味卡尔曼滤波器(UKF)。从理论上讲,UKF优于EKF,因为与模型线性化相比,Unscented Transform对结果分布的近似更好。在实践中,必须具有相当大的非线性才能实际看到较大的差异。
肯尼迪行动
由于我谈到了很多有关带GPS的移动机器人的内容,因此我就此情况作了简短的演示(如果要使用它,可以在这里找到代码)。 使用独轮车模型生成机器人运动。 用于KF的状态转换模型是等速模型,其状态包含x和y位置,转向角及其导数。
机器人会及时移动(实际位置显示为黑色),在每一步中,您都会得到非常嘈杂的GPS测量值,该测量值给出x和y(红色)并估算位置(蓝色)。 您可以使用不同的参数,看看它们如何影响状态估计。 如您所见,我们可以进行非常嘈杂的测量,并对实际位置进行很好的估算。

KF in action: a robot real path (black) is tracked with a KF (blue) from noisy measurements (red).
奖励:卡尔曼增益的直观含义
让我们看一下线性OF情况下卡尔曼增益的公式,并尝试更深入地了解增益的工作原理。

其中P_k是当前估计状态的协方差(我们对估计的信心程度),C是测量模型的线性变换,使得y(k)= Cx(k),R是测量噪声的协方差矩阵 。 请注意,分数表示法并不是真正正确的,但是可以使发生的事情更容易可视化。
根据等式,如果R变为0,则我们有:

代之以定义的算法步骤(3),可以看到我们将完全忽略预测步骤的结果,并且使用测量模型的逆变换来获得仅来自测量的状态估计。
相反,如果我们非常信任模型/估计,则P_k将趋于0,从而得出:

因此,我们得到的最终估计与预测步长输出相同。
请注意,我正在交替使用”信任模型”和”信任当前估计”。 它们并不相同,但它们是相关的,因为我们对预测步骤的估计的信任程度是我们对模型的信任程度(因为仅使用模型完成预测步骤)加上我们对模型的信任程度的组合。 估计上一步过滤。
奖励2:库
有很多不错的库可以在线计算KF,这是我的一些最爱。
作为GO爱好者,我将从这个非常不错的GO库开始,其中包含几个预先实现的模型:rosshemsley/kalman
对于Python,您可以查看 pykalman.github.io
结论:我们深入研究了什么是状态估计,卡尔曼滤波器的工作原理,其背后的直觉,如何使用它们以及何时使用。 我们介绍了一个玩具(但现实生活中)的问题,并介绍了如何使用卡尔曼滤波器解决该问题。 然后,我们更深入地研究了Kalman滤波器在幕后的实际作用。
干杯!
(本文翻译自Lorenzo Peppoloni的文章《Kalman Filters for Software Engineers》,参考:https://towardsdatascience.com/kalman-filters-for-software-engineers-3d2a05dee465)
https://m.toutiaocdn.com/i6786630824532902414/?app=news_article×tamp=1591026245&use_new_style=1&req_id=20200601234405010026059030254AEA7D&group_id=6786630824532902414&tt_from=android_share&utm_medium=toutiao_android&utm_campaign=client_share
转载请注明:徐自远的乱七八糟小站 » 面向软件工程师的卡尔曼滤波器