【神级程序员花了半个月整理的正则表达式!教科书一样的教学方法!】
本节我们看一下正则表达式的相关用法,正则表达式是处理字符串的强大的工具,它有自己特定的语法结构,有了它,实现字符串的检索、替换、匹配验证都不在话下。
当然对于爬虫来说,有了它,我们从 HTML 里面提取我们想要的信息就非常方便了。小编推荐大家加一下这个群:330637182 这个群里好几千人了!大家遇到啥问题都会在里面交流!而且免费分享零基础入门料资料web开发 爬虫资料一整套!是个非常好的学习交流地方!也有程序员大神给大家热心解答各种问题!很快满员了。欲进从速哦!各种PDF等

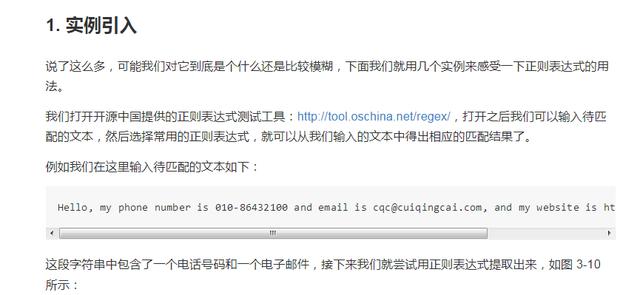
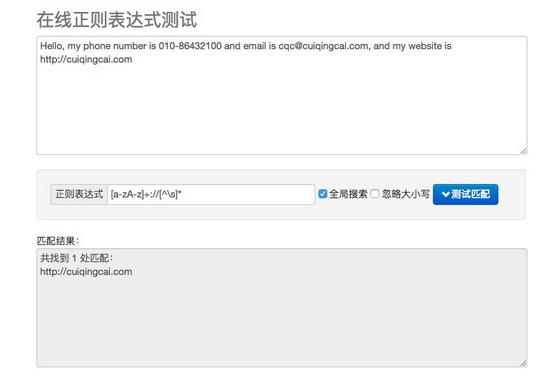
我们在网页中选择匹配 Email 地址,就可以看到在下方出现了文本中的 Email。如果我们选择了匹配网址 URL,就可以看到在下方出现了文本中的 URL。是不是非常神奇?
其实,在这里就是用了正则表达式匹配,也就是用了一定的规则将特定的文本提取出来。比如电子邮件它开头是一段字符串,然后是一个 @ 符号,然后就是某个域名,这是有特定的组成格式的。另外对于 URL,开头是协议类型,然后是冒号加双斜线,然后是域名加路径。
对于 URL 来说,我们就可以用下面的正则表达式匹配:
|
1 |
[a-zA-z]+://[^s]* |
如果我们用这个正则表达式去匹配一个字符串,如果这个字符串中包含类似 URL 的文本,那就会被提取出来。
这个正则表达式看上去是乱糟糟的一团,其实不然,这里面都是有特定的语法规则的。比如 a-z 代表匹配任意的小写字母,s 表示匹配任意的空白字符,* 就代表匹配前面的字符任意多个,这一长串的正则表达式就是这么多匹配规则的组合,最后实现特定的匹配功能。
写好正则表达式后,我们就可以拿它去一个长字符串里匹配查找了,不论这个字符串里面有什么,只要符合我们写的规则,统统可以找出来。那么对于网页来说,如果我们想找出网页源代码里有多少 URL,就可以用匹配URL的正则表达式去匹配,就可以得到源码中的 URL 了。
在上面我们说了几个匹配规则,那么正则表达式的规则到底有多少?那么在这里把常用的匹配规则总结一下:
| 模式 | 描述 | |
|---|---|---|
w |
匹配字母数字及下划线 | |
W |
匹配非字母数字及下划线 | |
s |
匹配任意空白字符,等价于 [ ]. | |
S |
匹配任意非空字符 | |
d |
匹配任意数字,等价于 [0-9] | |
D |
匹配任意非数字 | |
A |
匹配字符串开始 | |
Z |
匹配字符串结束,如果是存在换行,只匹配到换行前的结束字符串 | |
z |
匹配字符串结束 | |
G |
匹配最后匹配完成的位置 | |
|
匹配一个换行符 | |
|
匹配一个制表符 | |
^ |
匹配字符串的开头 | |
$ |
匹配字符串的末尾 | |
. |
匹配任意字符,除了换行符,当 re.DOTALL 标记被指定时,则可以匹配包括换行符的任意字符 | |
[...] |
用来表示一组字符,单独列出:[amk] 匹配 ‘a’,’m’ 或 ‘k’ | |
[^...] |
不在 [] 中的字符:abc 匹配除了 a,b,c 之外的字符。 | |
* |
匹配 0 个或多个的表达式。 | |
+ |
匹配 1 个或多个的表达式。 | |
? |
匹配 0 个或 1 个由前面的正则表达式定义的片段,非贪婪方式 | |
{n} |
精确匹配 n 个前面表达式。 | |
{n, m} |
匹配 n 到 m 次由前面的正则表达式定义的片段,贪婪方式 | |
a |
b | 匹配 a 或 b |
( ) |
匹配括号内的表达式,也表示一个组 |
可能看完了之后就有点晕晕的了把,不用担心,下面我们会详细讲解下一些常见的规则的用法。怎么用它来从网页中提取我们想要的信息。


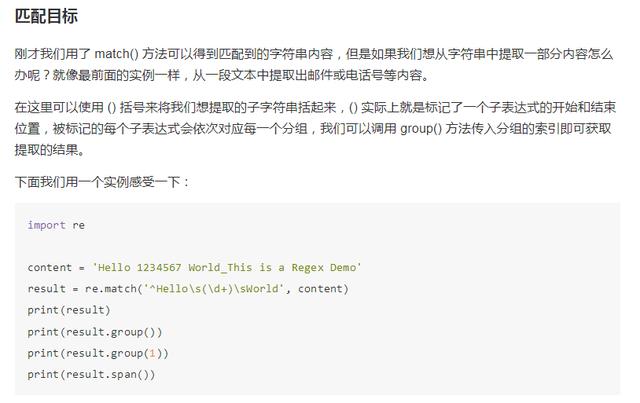
用它来匹配这个长字符串。开头的 ^ 是匹配字符串的开头,也就是以 Hello 开头,然后 s 匹配空白字符,用来匹配目标字符串的空格,d 匹配数字,3 个 d 匹配 123,然后再写 1 个 s 匹配空格,后面还有 4567,我们其实可以依然用 4 个 d 来匹配,但是这么写起来比较繁琐,所以在后面可以跟 {4} 代表匹配前面的规则 4 次,也就是匹配 4 个数字,这样也可以完成匹配,然后后面再紧接 1 个空白字符,然后 w{10} 匹配 10 个字母及下划线,正则表达式到此为止就结束了,我们注意到其实并没有把目标字符串匹配完,不过这样依然可以进行匹配,只不过匹配结果短一点而已。
我们调用 match() 方法,第一个参数传入了正则表达式,第二个参数传入了要匹配的字符串。
打印输出一下结果,可以看到结果是 SRE_Match 对象,证明成功匹配,它有两个方法,group() 方法可以输出匹配到的内容,结果是 Hello 123 4567 World_This,这恰好是我们正则表达式规则所匹配的内容,span() 方法可以输出匹配的范围,结果是 (0, 25),这个就是匹配到的结果字符串在原字符串中的位置范围。
通过上面的例子我们可以基本了解怎样在 Python 中怎样使用正则表达式来匹配一段文字
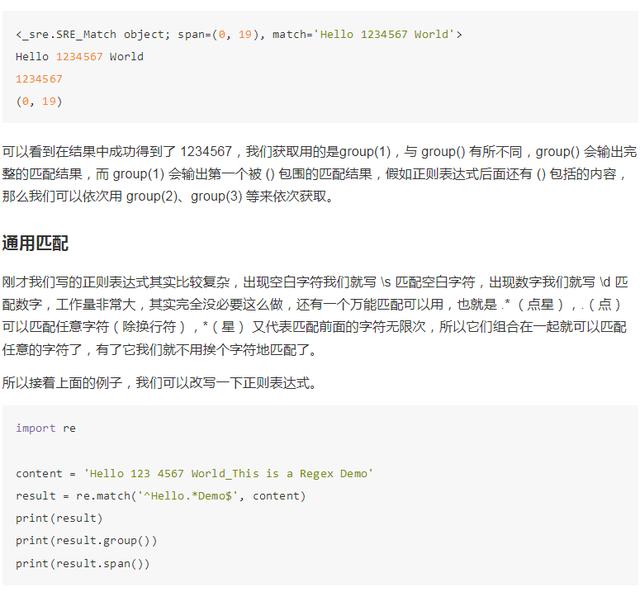
依然是前面的字符串,在这里我们想匹配这个字符串并且把其中的 1234567 提取出来,在这里我们将数字部分的正则表达式用 () 括起来,然后接下来调用了group(1) 获取匹配结果。
运行结果如下:
在这里我们将中间的部分直接省略,全部用 .* 来代替,最后加一个结尾字符串就好了,运行结果如下:
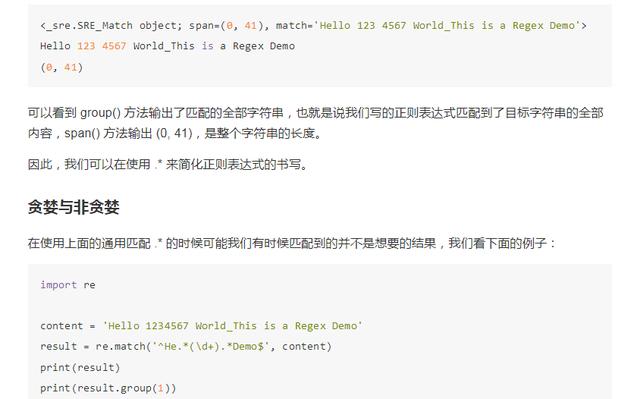
在这里我们依然是想获取中间的数字,所以中间我们依然写的是 (d+),数字两侧由于内容比较杂乱,所以两侧我们想省略来写,都写 .*,最后组成 ^He.*(d+).*Demo$,看样子并没有什么问题,我们看下运行结果:
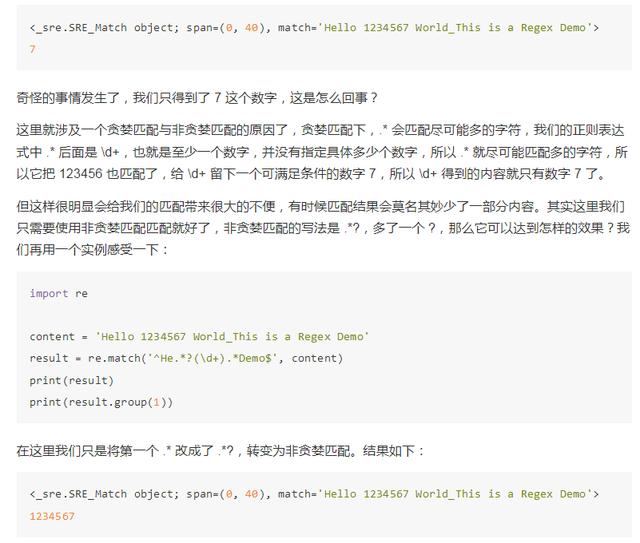
这下我们就可以成功获取 1234567 了。原因可想而知,贪婪匹配是尽可能匹配多的字符,非贪婪匹配就是尽可能匹配少的字符,.*? 之后是 d+ 用来匹配数字,当 .*? 匹配到 Hello 后面的空白字符的时候,再往后的字符就是数字了,而 d+ 恰好可以匹配,那么这里 .*? 就不再进行匹配,交给 d+ 去匹配后面的数字。所以这样,.*? 匹配了尽可能少的字符,d+ 的结果就是 1234567 了。
所以说,在做匹配的时候,字符串中间我们可以尽量使用非贪婪匹配来匹配,也就是用 .*? 来代替 .*,以免出现匹配结果缺失的情况。
但这里注意,如果匹配的结果在字符串结尾,.*? 就有可能匹配不到任何内容了,因为它会匹配尽可能少的字符,例如:
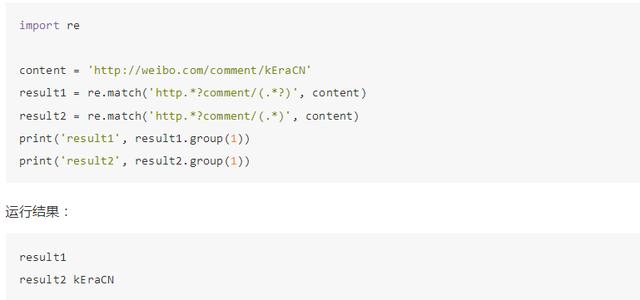
观察到 .*? 没有匹配到任何结果,而 .* 则尽量匹配多的内容,成功得到了匹配结果。
所以在这里好好体会一下贪婪匹配和非贪婪匹配的原理,对后面写正则表达式非常有帮助。
修饰符
正则表达式可以包含一些可选标志修饰符来控制匹配的模式。修饰符被指定为一个可选的标志。
我们用一个实例先来感受一下:

运行直接报错,也就是说正则表达式没有匹配到这个字符串,返回结果为 None,而我们又调用了 group() 方法所以导致AttributeError。
那我们加了一个换行符为什么就匹配不到了呢?是因为 . 匹配的是除换行符之外的任意字符,当遇到换行符时,.*? 就不能匹配了,所以导致匹配失败。
那么在这里我们只需要加一个修饰符 re.S,即可修正这个错误。
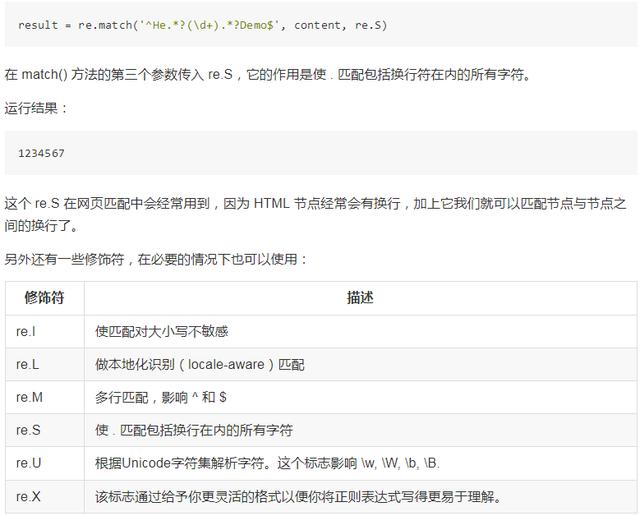
在网页匹配中较为常用的为 re.S、re.I。
转义匹配
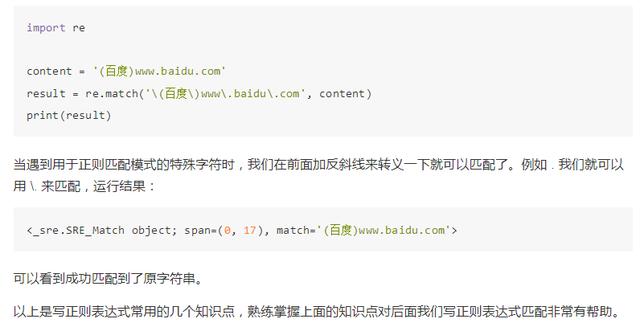
我们知道正则表达式定义了许多匹配模式,如 . 匹配除换行符以外的任意字符,但是如果目标字符串里面它就包含 . 我们改怎么匹配?
那么这里就需要用到转义匹配了,我们用一个实例来感受一下:
4. search()
我们在前面提到过 match() 方法是从字符串的开头开始匹配,一旦开头不匹配,那么整个匹配就失败了。
我们看下面的例子:
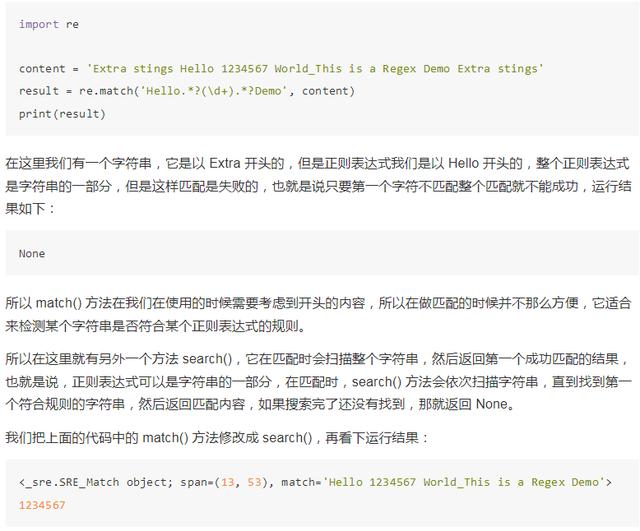
这样就得到了匹配结果。
所以说,为了匹配方便,我们可以尽量使用 search() 方法。
下面我们再用几个实例来感受一下 search() 方法的用法。
首先这里有一段待匹配的 HTML 文本,我们接下来写几个正则表达式实例来实现相应信息的提取。

观察到 ul 节点里面有许多 li 节点,其中 li 节点有的包含 a 节点,有的不包含 a 节点,a 节点还有一些相应的属性,超链接和歌手名。
首先我们尝试提取 class 为 active的 li 节点内部的超链接包含的歌手名和歌名。
所以我们需要提取第三个 li 节点下的 a 节点的 singer 属性和文本。
所以正则表达式可以以 li 开头,然后接下来寻找一个标志符 active,中间的部分可以用 .*? 来匹配,然后接下来我们要提取 singer 这个属性值,所以还需要写入singer=”(.*?)” ,我们需要提取的部分用小括号括起来,以便于用 group() 方法提取出来,它的两侧边界是双引号,然后接下来还需要匹配 a 节点的文本,那么它的左边界是 >,右边界是 </a>,所以我们指定一下左右边界,然后目标内容依然用 (.*?) 来匹配,所以最后的正则表达式就变成了:
|
1 |
<li.*?active.*?singer="(.*?)">(.*?)</a> |
然后我们再调用 search() 方法,它便会搜索整个 HTML 文本,找到符合正则表达式的第一个内容返回。另外由于代码有换行,所以这里第三个参数需要传入 re.S。
所以整个匹配代码如下:

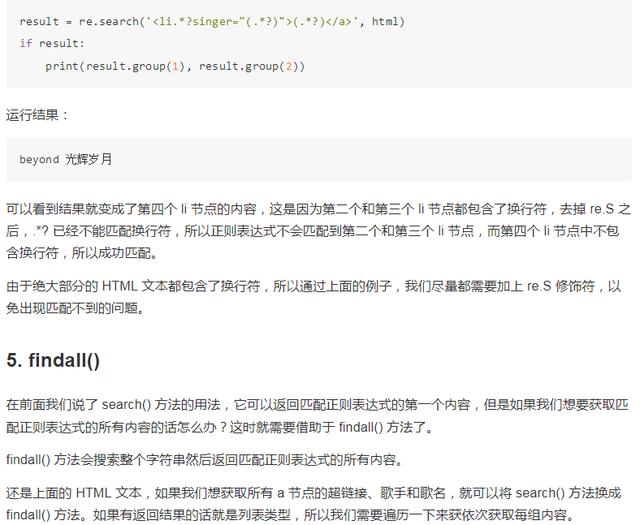
因为我们把 active 标签去掉之后,从字符串开头开始搜索,符合条件的节点就变成了第二个 li 节点,后面的就不再进行匹配,所以运行结果自然就变成了第二个 li 节点中的内容。
注意在上面两次匹配中,search() 方法的第三个参数我们都加了 re.S,使得 .*? 可以匹配换行,所以含有换行的 li 节点被匹配到了,如果我们将其去掉,结果会是什么?
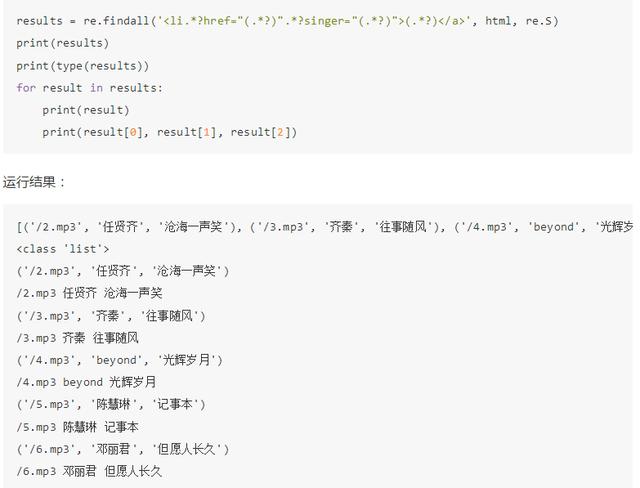
可以看到,返回的列表的每个元素都是元组类型,我们用对应的索引依次取出即可。
所以,如果只是获取第一个内容,可以用 search() 方法,当需要提取多个内容时,就可以用 findall() 方法。
6. sub()
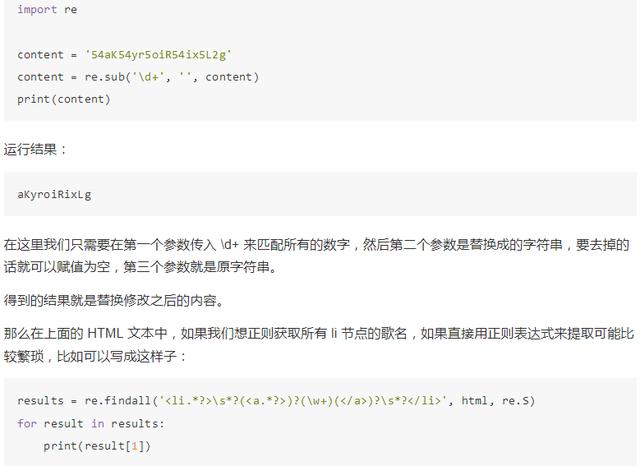
正则表达式除了提取信息,我们有时候还需要借助于它来修改文本,比如我们想要把一串文本中的所有数字都去掉,如果我们只用字符串的 replace() 方法那就太繁琐了,在这里我们就可以借助于 sub() 方法。
我们用一个实例来感受一下:
运行结果:

运行结果:
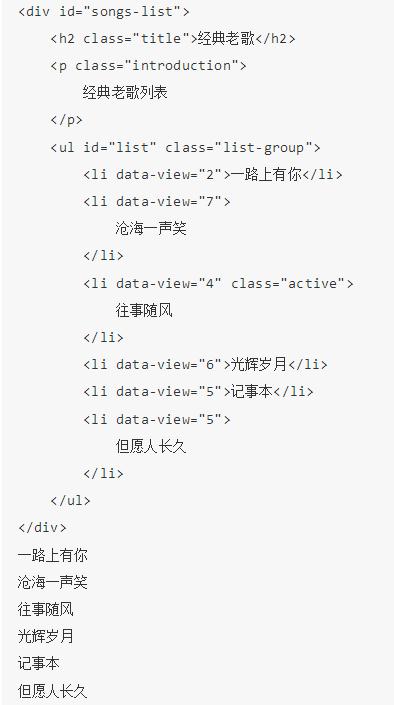
可以到 a 节点在经过 sub() 方法处理后都没有了,然后再 findall() 直接提取即可。所以在适当的时候我们可以借助于 sub() 方法做一些相应处理可以事半功倍
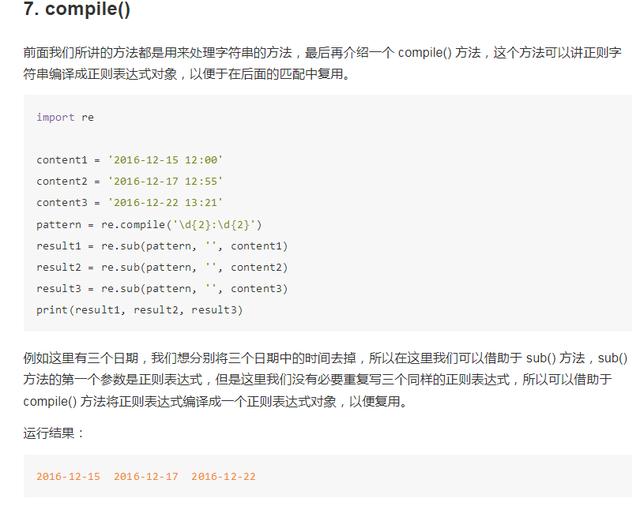
另外 compile() 还可以传入修饰符,例如 re.S 等修饰符,这样在 search()、findall() 等方法中就不需要额外传了。所以 compile() 方法可以说是给正则表达式做了一层封装,以便于我们更好地复用。
8. 结语
到此为止,正则表达式的基本用法就介绍完毕了,后面我们会有实战来讲解正则表达式的使用。