我是一个婚恋网站的数据分析师,新入职的第二天,接到老板的任务,让我预测来婚恋网站新注册的男生&女生是否会约会成功。
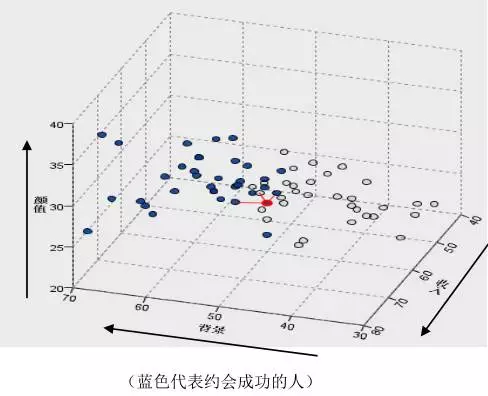
如何预测一个新来的男生是否会约会成功呢?这很简单,只需要调出一下数据库中之前注册网站的会员信息及跟踪情况,看看和这个新来的男生条件最接近的男生是否约会成功了,那么就可以大致预估新来的男生是否会约会成功。中国有句老话叫做“近朱者赤,近墨者黑”,正是这个道理。比如下图,假设我们将男生的条件划分为三个维度,颜值、背景和收入。蓝色点代表约会成功,灰色点代表未约会成功。红色点代表新来的男生,他和两个蓝色点,一个灰色点最接近,因此点约会成功的可能性是2/3。
KNN算法简介
上述思路所用到的数据挖掘算法为KNN算法, KNN(K NearestNighbor),K最邻域法属于惰性算法,其特点是不事先建立全局的判别公式和规则。当新数据需要分类的时候,根据每个样本和原有样本的距离,取最近K个样本点的众数(Y为分类变量)或者均值(Y为连续变量)作为新样本的预测值。实做KNN只需要考虑以下三件事情:
1. 数据的前处理
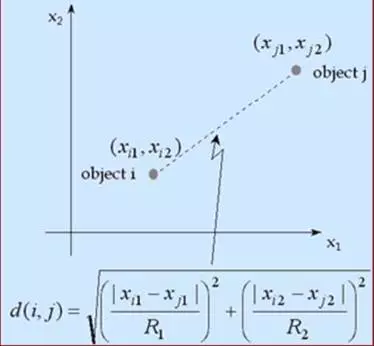
数据的属性有Scale的问题,比如收入和年龄的量纲单位不同,则不能简单的加总来计算距离,需要进行极值的正规化,将输入变量维度的数据都转换到【0,1】之间,这样才能进行距离的计算。计算公式如下:


2. 距离的计算
一般使用欧几里得距离,勾股定理大家都学过,计算两点之间的距离,不多说。
3. 预测结果的推估
预测过程中我们会同时输出预测的概率值,同时我们需要去了解几个指标的含义。
回应率(precision):
捕捉率(recall):
F指标(f1-score):F指标 同时考虑Precision& Recall
使用Python进行实做
此部分的思路如下:
- 1. 读入数据集
- 2. 描述性分析与探索性分析
- 3. KNN模型建立
- 4. 模型的效果评估
数据集描述:此数据集为取自某婚恋网站往期用户信息库,含100个观测,8个变量。
# 加载所需包
%matplotlib inline
import os
import numpy as np
from scipy importstats
import pandas aspd
importsklearn.model_selection as cross_validation
importmatplotlib.pyplot as plt
import seaborn assns
import math
from scipy importstats,integrate
importstatsmodels.api as sm
# 加载数据并查看前5行
orgData =pd.read_csv(‘date_data2.csv’)
orgData.head()

我从数据库中挑选了收入、魅力值、资产、教育等级变量,并对收入、魅力值和资产进行了分类排序。
# 查看数据集的信息
orgData.info()

从上述信息可以看出数据集总共有100个观测,8个变量。其中浮点型2个,整型6个。还可以看出这个数据集占用了我电脑7k的内存。
# 对数值型变量做描述性统计分析
orgData.describe()
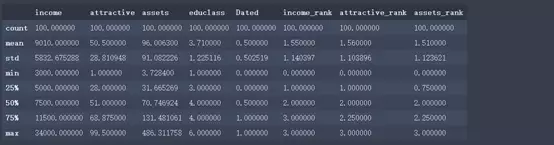
Python的语法就是这么简洁到令人发指。从上述信息我们可以观察到各变量的计数、最大值、最小值、平均值等信息。以income为例,平均值为9010元,中位数为7500元。我们猜想是收入被平均了,如何更直观的看到呢?很简单,我们画个直方图。
# 数据可视化探索
# 查看收入分布情况 直方图
sns.distplot(orgData[‘income’],fit=stats.norm);

果然,我们的收入被平均了。其他的数值型变量也可以照同样方法画画看。同时,我们想看看类别型的字段和目标变量的关系。
# 查看教育等级和是否约会成功关系 条形图
sns.barplot(x=’educlass’,y=’Dated’,data=orgData);
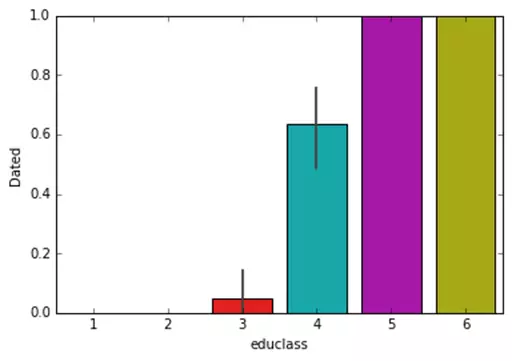
果然,教育等级越高的人约会成功的概率越高。这么多分类变量,我如何在一张图中呈现呢?很简单,设定面板数,这里我们使用分类的计数图来展现。
# 查看各分类变量和目标变量关系
fig,(axis1,axis2,axis3,axis4) = plt.subplots(1,4,figsize=(15,5))
sns.countplot(x=’Dated’,hue=”educlass”, data=orgData, order=[1,0], ax=axis1)
sns.countplot(x=’Dated’,hue=”income_rank”, data=orgData, order=[1,0], ax=axis2)
sns.countplot(x=’Dated’,hue=”attractive_rank”, data=orgData, order=[1,0], ax=axis3)
sns.countplot(x=’Dated’,hue=”assets_rank”, data=orgData, order=[1,0], ax=axis4)
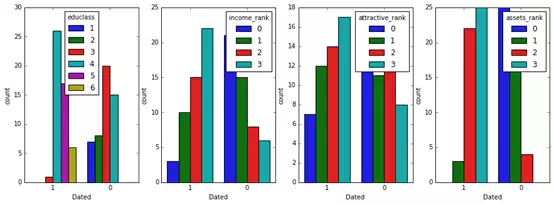
可以看出,教育等级,收入,魅力值,资产都和是否约会成功有密切关系。
说了这么多,下面我们开始用KNN建模,让机器告诉我们结果吧。
# 选取自变量和因变量
X = orgData.ix[:,:4]
Y =orgData[[‘Dated’]]
X.head()

# 进行极值的标准化
from sklearnimport preprocessing
min_max_scaler = preprocessing.MinMaxScaler()
X_scaled =min_max_scaler.fit_transform(X)
X_scaled[1:5]

此部分返回了自变量进行标准化之后的2~5行值。
#划分训练集和测试集
train_data,test_data, train_target, test_target = cross_validation.train_test_split(
X_scaled, Y, test_size=0.2, train_size=0.8,random_state=123)
划分训练集和测试集,训练集用来训练模型,测试集用来测试模型,训练集样本和测试集样本量比例为8:2.同时设定随机种子数。
# 建模
fromsklearn.neighbors import KNeighborsClassifier
model =KNeighborsClassifier(n_neighbors=3) # 默认欧氏距离
model.fit(train_data,train_target.values.flatten())
test_est =model.predict(test_data)
我们首先从导入了KNN分类器,分类模型的k值设置为3,然后用模型去训练训练集,并且用测试数据集来测试模型结果,输出到test_est对象中。
# 模型评估
import sklearn.metricsas metrics
print(metrics.confusion_matrix(test_target,test_est, labels=[0, 1])) # 混淆矩阵
print(metrics.classification_report(test_target,test_est))
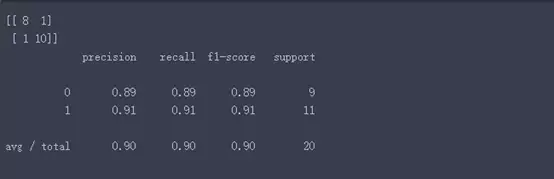
可以看出,模型的命中率和回应率均值都达到了90%。F指标为0.9
好了,模型的结果还勉强满意,美滋滋,做个报告去和老板交差了。
【后话】当然,这里面只是用了一个简单的数据集去实操了一下KNN的做法,操作和语法都比较简单易用理解,同时遍历了一下我们数据挖掘的流程,相应的知识及后续的知识没有做过多的展开,比如前端的数据如何清洗,KNN中K值如何设定和交叉验证,使用朴素贝叶斯预测模型的准确率,特征选择,模型融合等。希望大家能有所收获。
转载请注明:徐自远的乱七八糟小站 » 让Python猜猜你能否约会成功



