2019 年,如何配置一台以机器学习、深度学习为用途的工作站?
此问题已经收录至专题 别凑合,节前看看大家都买了哪些科技产品 欢迎关注专题并一起聊聊今年哪些科技产品让你冲动抱回家,怎样的使用技巧或体验让你忍不住分享…
//有钱人&大神可以跳过
//这里专门介绍10K以下的机器
众所周知,深度学习是有钱人的游戏(笑)作为一个穷学生(definitely)为了不只和minist较劲,需要配置一台较好的工作站,然而学生荷包空空,实验室的服务器抢手,如何配置一台够用的服务器呢。
(洋垃圾)服务器篇:
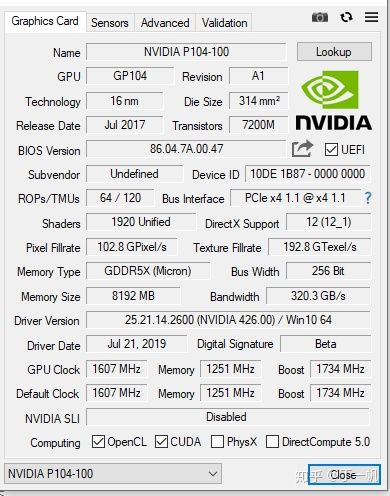
穷人的救星,P104显卡
P104显卡,或者说是换了马甲的1070显卡,拥有8G显存,一般只要700RMB就能搞到不错的橙色,用于跑深度学习再好不过了
笔者刚好有一块P104显卡。这块卡是750rmb收的。用于跑深度学习再好不过了

卡支持cuda,意味着tensorflow和pytorch都可以使用
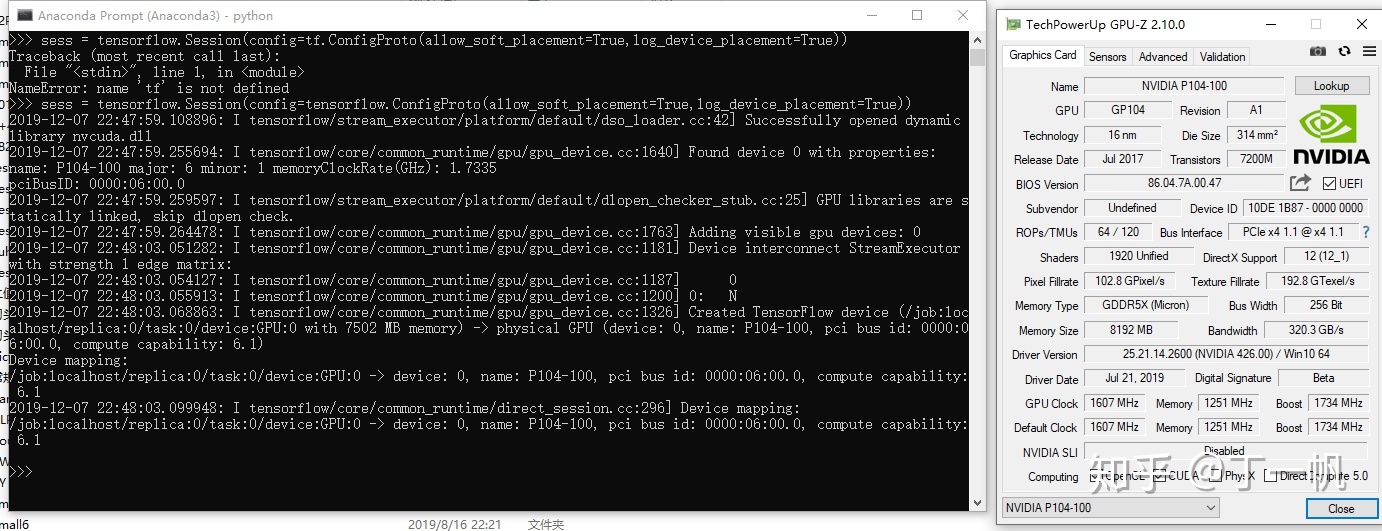
由于去掉了视频输入输出模块,该卡的温度较低,满载65摄氏度左右。
手上刚好有个PSMNet 跑一下看看温度吧

然后是算力?算力的话,以1080ti为坐标系1 大概是0.6-0.7左右(训练PSMnet的时候有图片加载时间,是0.7)
如果电源够大,可以考虑四块连载,效果更佳
(洋垃圾)平台篇(c612)
如果是老师付电费系列,当然可以直接选择C612
现在x99平台的cpu已经足够便宜(AMD,YES!)这里推荐使用富士康的主板和e5 2670v3*2
加起来也就1700元
拥有48条PCIE和28C 56T 足够你插4块显卡了
当然作为A fan 我肯定用amd啦
但是一定要知道,amd的pcie实际上是不足的,最多支持两块显卡,拿来跑小项目还行,多卡大项目是不行的
(洋垃圾)散热篇
水冷?不存在的。买不起。
基本上是靠暴力风扇来散热,做深度学习多卡一定要先考虑散热再上玩具,大部分机箱的散热性能堪忧,两块显卡就能上90度,千万别嫌吵,能上多大风扇上多大风扇。
基本上就写道这里把,我会一点cuda,主语言还是C++,人生苦短,python太慢,还是C++好。
这篇文章主要介绍的是家用的深度学习工作站,典型的配置有两种,分别是一个 GPU 的机器和 四个 GPU的机器。如果需要更多的 GPU 可以考虑配置两台四个 GPU 的机器。如果希望一台机器同时具备 6~8 个 GPU 需要联系专门的供应商进行配置,并且有专业的机房存放,放在家里噪声很大并且容易跳闸。
如何配置一台深度学习工作站?
CPU
由于最近 AMD 和 Intel 频繁更新 CPU,因此大家选择新款的 CPU 比较好。
CPU 与 GPU 的关系
CPU 瓶颈没有那么大,一般以一个 GPU 对应 2~4 个 CPU 核比较好,比如单卡机器买四核 CPU,四卡机器买十核 CPU。
当你在训练的时候,只要数据生成器(DataLoader)的产出速度比 GPU 的消耗速度快,那么 CPU 就不会成为瓶颈,也就不会拖慢训练速度。
PCI-E 支持情况
除了核数,你还需要注意 PCI-E 支持情况,一般显卡是 PCI-E 3.0 x16,比如 i9-9820X 的 PCI-E 通道数是 44 ,配置四卡的话,只能支持 1×16+3×8+1×4,也就是单卡全速,三卡半速,一个 NVMe 固态硬盘。这种情况下可以考虑选择带有 PLX 桥接芯片的主板。
AMD 的 2990WX 有 64条 PCI-E,但是只支持 x16/x8/x16/x8 的四卡配置。
带有桥接芯片的主板
有的主板如 WS X299 SAGE 带有 PLX 桥接芯片,可以在 CPU 没有足够 PCI-E 的情况下达到四卡 x16 的速度:主板
主板需要注意:
- CPU 接口是否能对上,如 LGA2066 和 SocketTR4
- PCI-E 插槽的高度是否够插显卡,比如 PCI-E 插口之间的距离至少要满足双槽宽显卡的高度
- PCI-E 同时可以支持几张卡以什么样的速度运行,如 1×16 + 3×8 是常见的配置
主板必看参数
GIGABYTE X299 AORUS MASTER (rev. 1.0) 使用了 4 组 2 槽间距显卡插槽设计,支持 1×16、2×16、2×16 + 1×8、1×16 + 3×8 四种配置(需要十核以上的 CPU),这里请参阅说明书安装显卡,安装在不同位置的速度是不一样的:
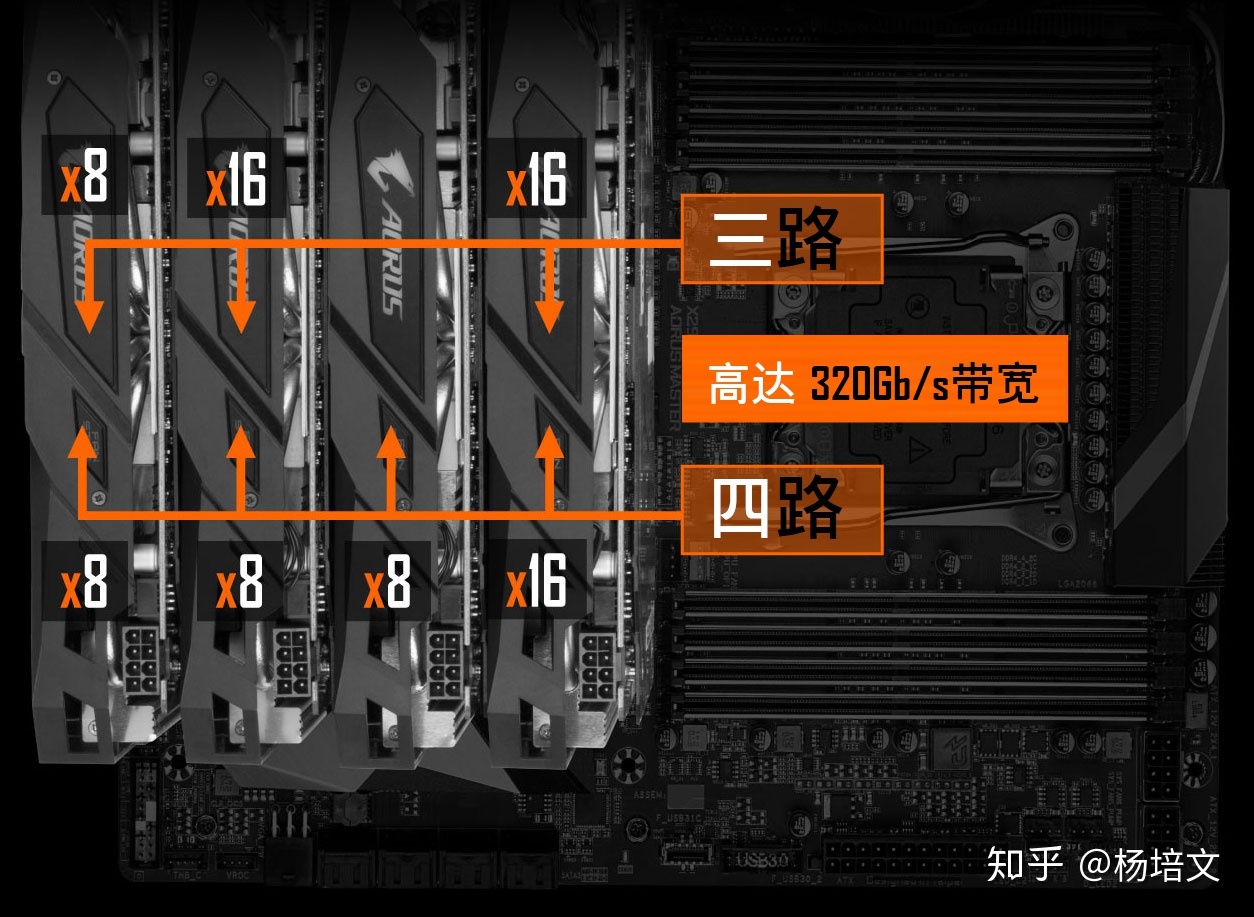
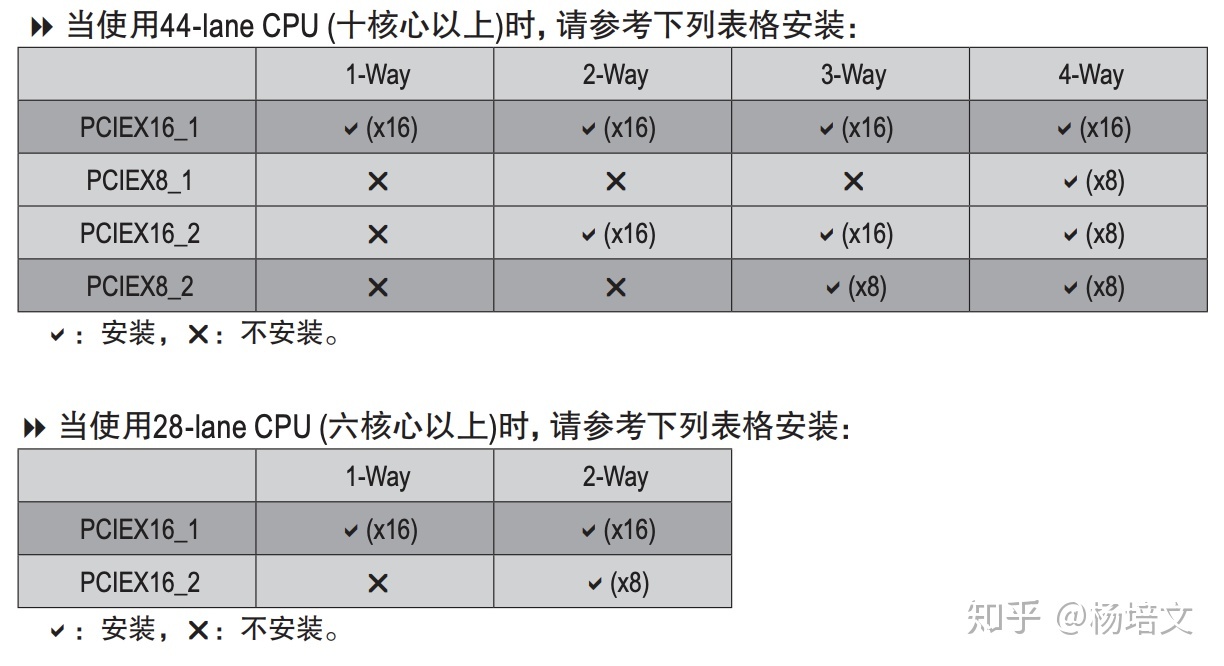
带有桥接芯片的主板
有的主板如 WS X299 SAGE 带有 PLX 桥接芯片,可以在 CPU 没有足够 PCI-E 的情况下达到四卡 x16 的速度:

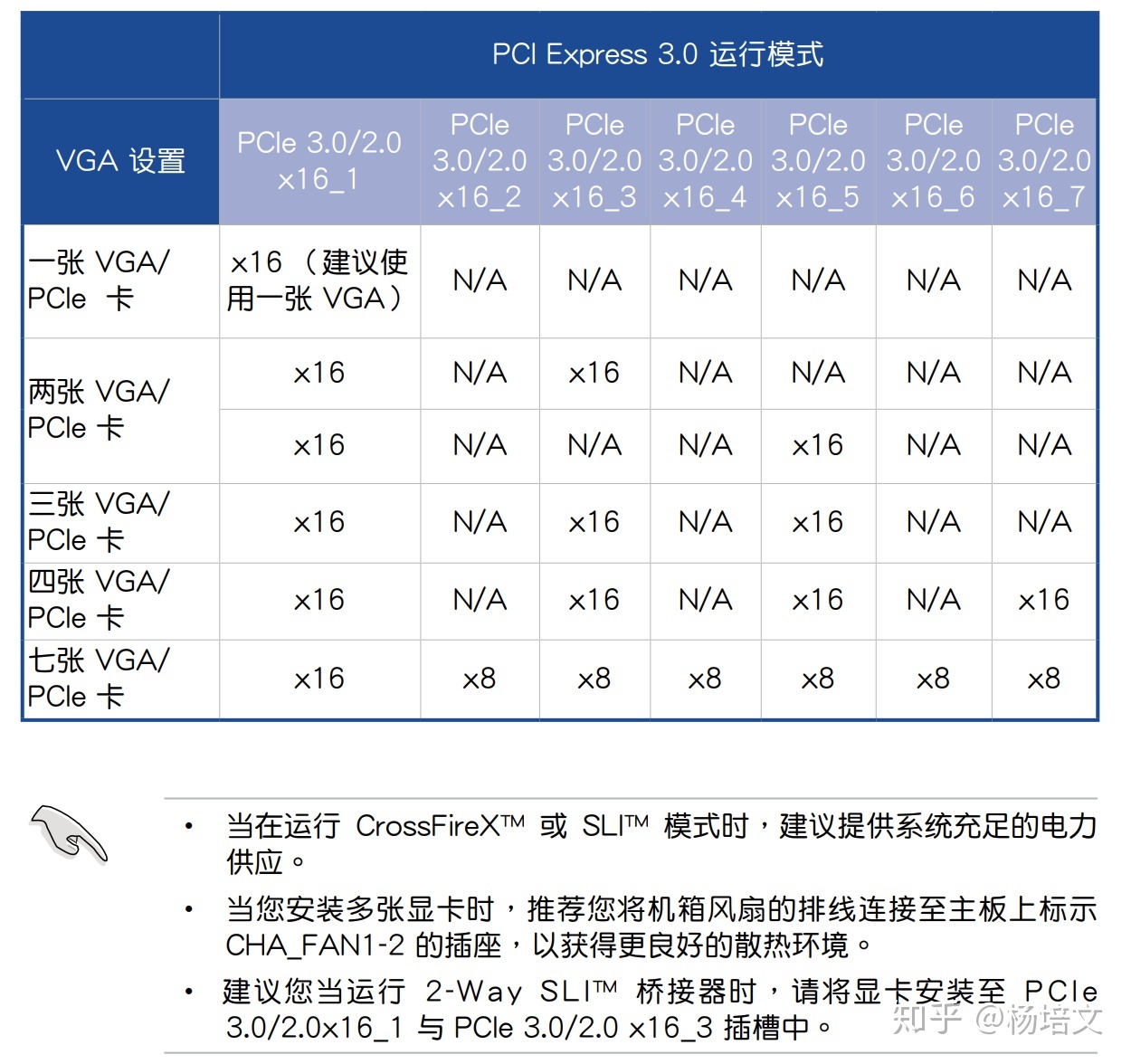
显卡
显卡性能表
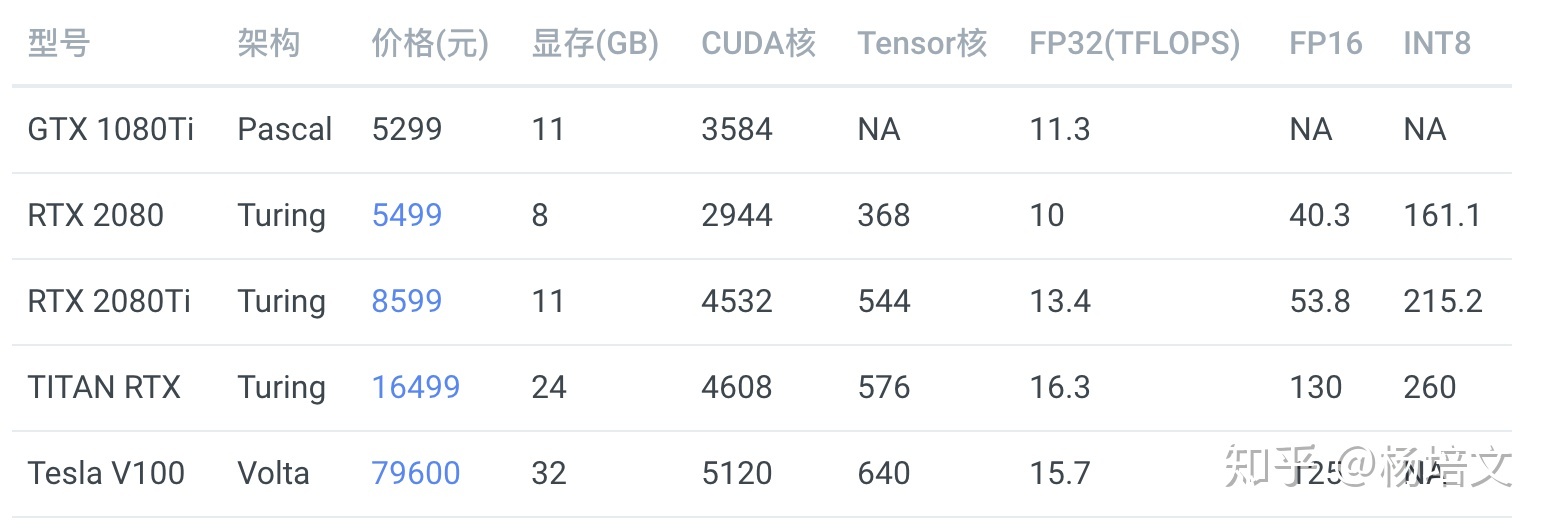
考虑成本可以买 RTX 2080Ti,想要高性能并且高性价比可以买 TITAN RTX。
RTX 2080 显存较小,不推荐。GTX 1080Ti 已经出了太久了,网上都是二手卡,不推荐。
参考链接:
涡轮与风扇
采购显卡的时候,一定要注意买涡轮版的,不要买两个或者三个风扇的版本,除非你只打算买一张卡。
因为涡轮风扇的热是往外机箱外部吹的,所以可以很好地带走热量,散热比较好。如果买三个风扇的版本,插多卡的时候,上面的卡会把热量吹向第二张卡,导致第二张卡温度过高,影响性能。
风扇显卡很有可能是超过双槽宽的,第二张卡可能插不上第二个 PCI-E 插槽,这个也需要注意。


服务器推断卡
除了用于训练,还有一类卡是用于推断的(只预测,不训练),如:
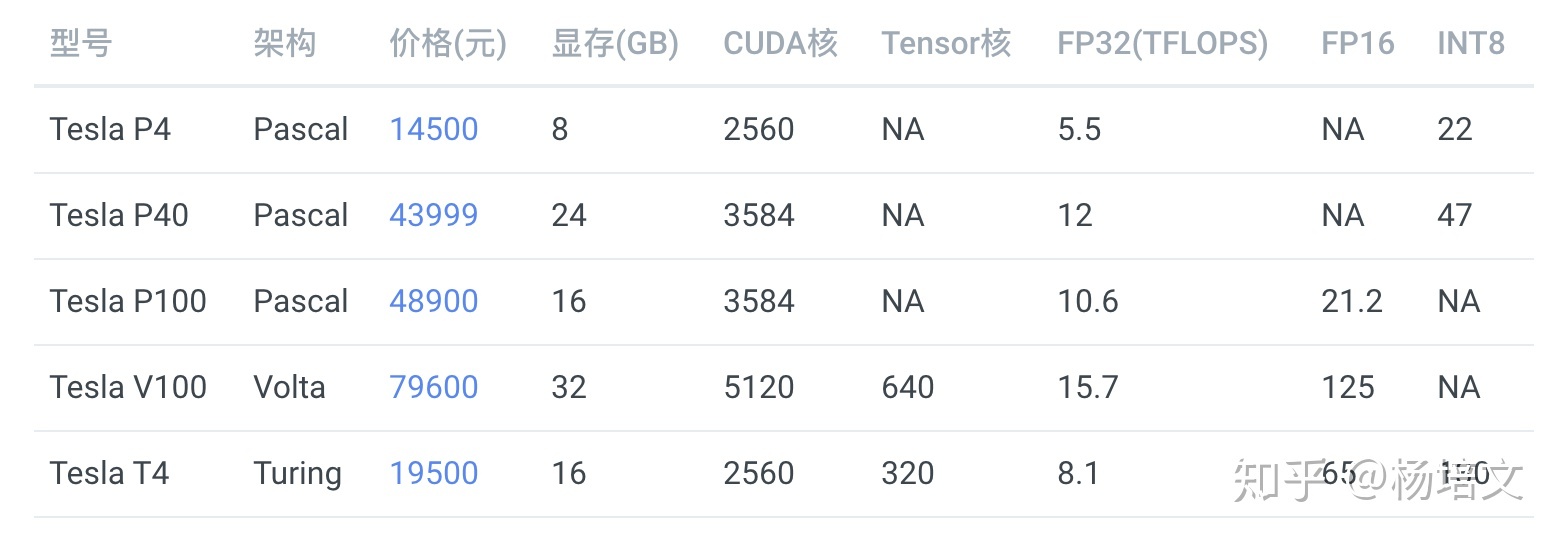
这些卡全部都是不带风扇的,但它们也需要散热,需要借助服务器强大的风扇被动散热,所以只能在专门设计的服务器上运行,具体请参考英伟达官网的说明。
性价比之选应该是 Tesla T4,但是发挥全部性能需要使用 TensorRT 深度优化,目前仍然存在许多坑,比如当你的网络使用了不支持的运算符时,需要自己实现。
英伟达只允许这类卡在服务器上运行,像 GTX 1080Ti、RTX 2080Ti 都是不能在数据中心使用的。
No Datacenter Deployment. The SOFTWARE is not licensed for datacenter deployment, except that blockchain processing in a datacenter is permitted.
参考链接:
硬盘
硬盘类型
常用硬盘接口有三种:
- SATA3.0,速度 600MB/s
- SAS,速度 1200MB/s
- PCIE 3.0 x4(NVMe),速度 3.94GB/s
参数对比
下面是根据代表产品查询的参数:
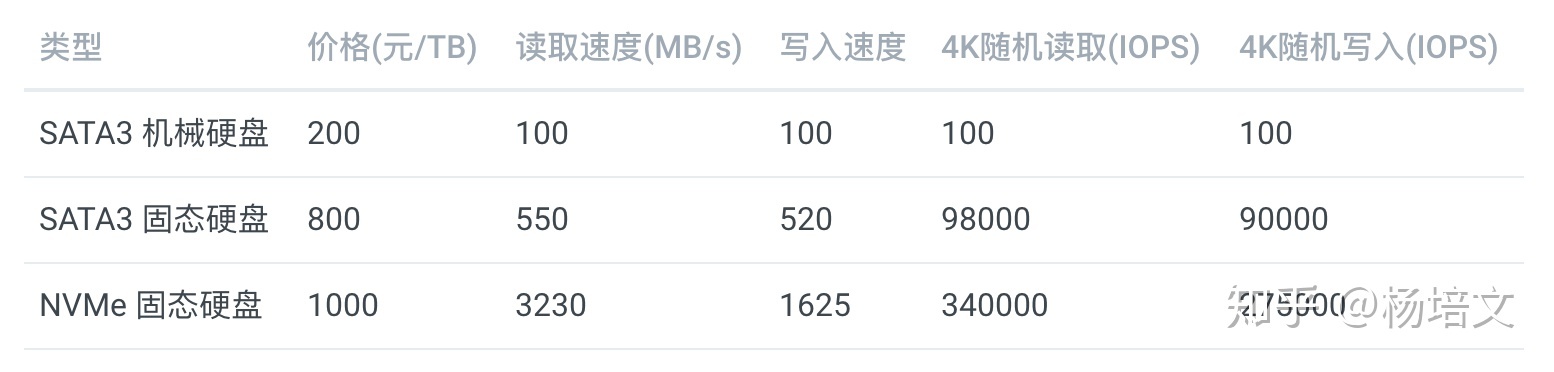
注:
- 4K 随机读写的队列深度为 32
- SATA3 机械硬盘没有太好的数据来源,所以数据是经验值
- SATA3 固态硬盘数据来源:三星(SAMSUNG)1TB SSD固态硬盘 SATA3.0接口 860 EVO
- NVMe 固态硬盘数据来源:英特尔(Intel)1TB SSD固态硬盘 M.2接口(NVMe协议) 760P系
在面对大量小文件的时候,使用 NVMe 硬盘可以一分钟扫完 1000万文件,如果使用普通硬盘,那么就需要一天时间。为了节省生命,简化代码,硬盘建议选择 NVMe 协议的固态硬盘。
如果你的主板不够新,没有NVMe 插槽,你可以使用 M.2 转接卡将 M.2 接口转为 PCI-E 接口。

内存
内存容量的选择通常大于显存,比如单卡配 16GB 内存,四卡配 64GB 内存。由于有数据生成器(DataLoader),数据不必全部加载到内存里,通常不会成为瓶颈。
电源
先计算功率总和,如单卡 CPU 100W,显卡 250W,加上其他的大概 400W,那么就买 650W 的电源。
双卡最好买 1000W 以上的电源,四卡最好买 1600W 的电源,我这里实测过四卡机用 1500W 的电源来带,跑起来所有的卡以后会因为电源不足而自动关机。
一般墙上的插座只支持 220V 10A,也就是 2200W 的交流电,由于电源要把交流电转直流电,所以会有一些损耗,最高只有 1600W,因此如果想要支持八卡,最好不要在家尝试。八卡一般是双电源,并且需要使用专用的 PDU 插座,并且使用的是 16A 插口,如果在家使用,会插不上墙上的插座。
网卡
一般主板自带千兆网卡。如果需要组建多机多卡集群,请联系供应商咨询专业的解决方案。
机箱
如果配单卡,可以直接买个普通机箱,注意显卡长度能放下就行。
如果配四卡机器,建议买一个 Air 540 机箱,因为我正在用这一款。

显示器
深度学习工作站装好系统以后就不需要显示器了,使用手边的显示器就行。
键盘鼠标
深度学习工作站装好系统以后就不需要键盘鼠标了,使用手边的键盘鼠标就行。
硬件设备,是任何一名深度学习er不可或缺的核心装备。各位初级调参魔法师们,你们有没有感到缺少那一根命中注定的魔杖?

可是,各种CPU、GPU、内存条、外设,那么多品牌种类型号参数,到底该怎么选?
为了帮你凑齐一套能打的装备,一位名叫Tim Dettmers的歪果小哥哥将自己一年组装七部工作站的装机经验凝练成一篇实用攻略分享了出来,帮你确定一整套硬件选型,并且,还根据今年的新硬件做了推荐。
太长不看版
GPU: RTX 2070、RTX 2080 Ti、GTX 1070、GTX 1080、GTX 1080,这些都不错。
CPU: 1.给每个GPU配1-2个CPU核心,具体要看你预处理数据的方式; 2.频率要大于2GHz,CPU要能支持你的GPU数量; 3.PCIe通道不重要。
内存: 1.时钟频率无关紧要,内存买最便宜的就行了; 2.内存 ≥ 显存最大的那块GPU的RAM; 3.内存不用太大,用多少买多少; 4.如果你经常用大型数据集,买更多内存会很有用。
硬盘/SSD: 1.给你的数据集准备足够大的硬盘(≥3TB); 2.有SSD会用的舒坦一些,还能预处理小型数据集。
PSU: 1.需要的功率最大值≈(CPU功率+GPU功率)×110%; 2.买一个高能效等级的电源,特别是当你需要连很多GPU并且可能运行很长时间的时,这样可以节省很多电费; 3.买之前请确保电源上有足够多的接头(PCIe 8-pin或6-pin)接GPU。
散热: CPU: 标准配置的CPU散热器或者AIO水冷散热器; GPU: 1.单个GPU,风冷散热即可; 2.若用多个GPU,选择鼓风式风冷散热或水冷散热。
主板: 准备尽可能多的链接GPU的PCle插槽,一个GPU需要两个插槽,每个系统最多4个GPU,不过你也要考虑GPU的厚度。
显示器: 为了提高效率,多买几块屏幕吧。
下面我们从GPU开始,依次看看各重要部件应该如何选择,全文超过5000字,预计阅读时间11分钟。

GPU
显卡(GPU)是深度学习的重要部件,甚至比CPU更重要。做深度学习不用GPU只用CPU显然是不明智的,所以作者Tim先介绍了GPU的选择。

选购GPU有三大注意事项:性价比、显存、散热。
使用16bit的RTX 2070或者RTX 2080 Ti性价比更高。另外在eBay上购买二手的32bit GTX 1070、GTX 1080或者1080 Ti也是不错的选择。
除了GPU核心,显存(GPU RAM)也是不可忽视的部分。RTX比GTX系列显卡在显存方面更具优势,在显存相同的情况下,RTX能够训练两倍大的模型。
通常对显存的要求如下:
- 如果想在研究中追求最高成绩:显存>=11 GB;
- 在研究中搜寻有趣新架构:显存>=8 GB;
- 其他研究:8GB;
- Kaggle竞赛:4~8GB;
- 创业公司:8GB(取决于具体应用的模型大小)
- 公司:打造原型8GB,训练不小于11GB
需要注意的是,如果你购买了多个RTX显卡,一定不要忽视散热。两个显卡堆叠在相邻PCI-e插槽,很容易令GPU过热降频,可能导致性能下降30%。这个问题后面还会具体讨论。
内存
选择内存(RAM)有两个参数:时钟频率、容量。这两个参数哪个更重要?

时钟频率
炒作内存时钟频率是厂家常用的营销手段,他们宣传内存越快越好,实际上真的是这样吗?
知名数码博主Linus Tech Tips解答了这个问题:厂商会引诱你购买“更快”的RAM,实际上却几乎没有性能提升。
内存频率和数据转移到显存的速度无关,提高频率最多只能有3%的性能提升,你还是把钱花在其他地方吧!
内存容量
内存大小不会影响深度学习性能,但是它可能会影响你执行GPU代码的效率。内存容量大一点,CPU就可以不通过磁盘,直接和GPU交换数据。
所以用户应该配备与GPU显存匹配的内存容量。如果有一个24GB显存的Titan RTX,应该至少有24GB的内存。但是,如果有更多的GPU,则不一定需要更多内存。
Tim认为:内存关系到你能不能集中资源,解决更困难的编程问题。如果有更多的内存,你就可以将注意力集中在更紧迫的问题上,而不用花大量时间解决内存瓶颈。
他还在参加Kaggle比赛的过程中发现,额外的内存对特征工程非常有用。
CPU
过分关注CPU的性能和PCIe通道数量,是常见的认知误区。用户更需要关注的是CPU和主板组合支持同时运行的GPU数量。

CPU和PCIe
人们对PCIe通道的执念近乎疯狂!而实际上,它对深度学习性能几乎没有影响。
如果只有一个GPU,PCIe通道的作用只是快速地将数据从内存传输到显存。
ImageNet里的32张图像(32x225x225x3)在16通道上传输需要1.1毫秒,在8通道上需要2.3毫秒,在4通道上需要4.5毫秒。
这些只是是理论数字,实际上PCIe的速度只有理论的一半。PCIe通道通常具有纳秒级别的延迟,因此可以忽略延迟。
Tim测试了用32张ImageNet图像的mini-batch,训练ResNet-152模型所需要的传输时间:
- 前向和后向传输:216毫秒
- 16个PCIe通道CPU-> GPU传输:大约2毫秒(理论上为1.1毫秒)
- 8个PCIe通道CPU-> GPU传输:大约5毫秒(2.3毫秒)
- 4个PCIe通道CPU-> GPU传输:大约9毫秒(4.5毫秒)
因此,在总用时上,从4到16个PCIe通道,性能提升约3.2%。但是,如果PyTorch的数据加载器有固定内存,则性能提升为0%。因此,如果使用单个GPU,请不要在PCIe通道上浪费金钱。
在选择CPU PCIe通道和主板PCIe通道时,要保证你选择的组合能支持你想要的GPU数量。如果买了支持2个GPU的主板,而且希望用上2个GPU,就要买支持2个GPU的CPU,但不一定要查看PCIe通道数量。
PCIe通道和多GPU并行计算
如果在多个GPU上训练网络,PCIe通道是否重要呢?Tim曾在ICLR 2016上发表了一篇论文指出(https://arxiv.org/abs/1511.04561):如果你有96个GPU,那么PCIe通道非常重要。
但是,如果GPU数量少于4个,则根本不必关心PCIe通道。几乎很少有人同时运行超过4个GPU,所以不要在PCIe通道上花冤枉钱。这不重要!
CPU核心数
为了选择CPU,首先需要了解CPU与深度学习的关系。
CPU为深度学习中起到什么作用?当在GPU上运行深度网络时,CPU几乎不会进行任何计算。CPU的主要作用有:(1)启动GPU函数调用(2)执行CPU函数。
到目前为止,CPU最有用的应用是数据预处理。有两种不同的通用数据处理策略,具有不同的CPU需求。
第一种策略是在训练时进行预处理,第二种是在训练之前进行预处理。
对于第一种策略,高性能的多核CPU能显著提高效率。建议每个GPU至少有4个线程,即为每个GPU分配两个CPU核心。Tim预计,每为GPU增加一个核心 ,应该获得大约0-5%的额外性能提升。
对于第二种策略,不需要非常好的CPU。建议每个GPU至少有2个线程,即为每个GPU分配一个CPU核心。用这种策略,更多内核也不会让性能显著提升。
CPU时钟频率
4GHz的CPU性能是否比3.5GHz的强?对于相同架构处理器的比较,通常是正确的。但在不同架构处理器之间,不能简单比较频率。CPU时钟频率并不总是衡量性能的最佳方法。
在深度学习的情况下,CPU参与很少的计算:比如增加一些变量,评估一些布尔表达式,在GPU或程序内进行一些函数调用。所有这些都取决于CPU核心时钟率。
虽然这种推理似乎很明智,但是在运行深度学习程序时,CPU仍有100%的使用率,那么这里的问题是什么?Tim做了一些CPU的降频实验来找出答案。
CPU降频对性能的影响:
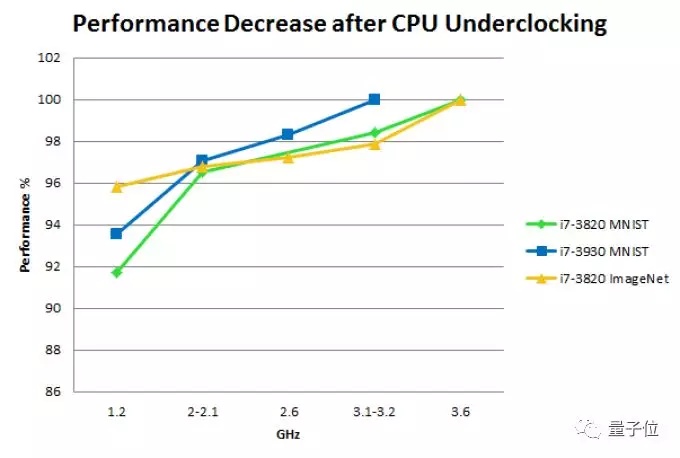
请注意,这些实验是在一些“上古”CPU(2012年推出的第三代酷睿处理器)上进行的。但是对于近年推出的CPU应该仍然适用。
硬盘/固态硬盘(SSD)
通常,硬盘不会限制深度学习任务的运行,但如果小看了硬盘的作用,可能会让你追、悔、莫、及。
想象一下,如果你从硬盘中读取的数据的速度只有100MB/s,那么加载一个32张ImageNet图片构成的mini-batch,将耗时185毫秒。
相反,如果在使用数据前异步获取数据,将在185毫秒内加载这些mini-batch的数据,而ImageNet上大多数神经网络的计算时间约为200毫秒。所以,在计算状态时加载下一个mini-batch,性能将不会有任何损失。
Tim小哥推荐的是固态硬盘(SSD),他认为SSD在手,舒适度和效率皆有。和普通硬盘相比,SSD程序启动和响应速度更快,大文件的预处理更是要快得多。
顶配的体验就是NVMe SSD了,比一般SSD更流畅。

电源装置(PSU)
一个程序员对电源最基础的期望,首先得是能满足各种GPU所需能量吧。随着GPU朝着更低能耗发展,一个质量优秀的PSU能陪你走很久。
应该怎么选?Tim小哥有一套计算方法:将电脑CPU和GPU的功率相加,再额外加上10%的功率算作其他组件的耗能,就得到了功率的峰值。
举个例子,如果你有4个GPU,每个功率为250瓦,还有一个功率为150瓦的CPU,则需电源提供4×250+150+100=1250瓦的电量。
Tim通常会在此基础上再额外添加10%确保万无一失,那就总共需要1375瓦。所以这种情况下,电源性能需达1400瓦。
这样手把手教学,应该不难理解了。还有一点得注意,即使一个PSU达到了所需瓦数,也可能没有足够的PCIe 8-pin或6-pin的接头,所以买的时候还要确保电源上有足够多的接头接GPU。

另外,买一个能效等级高的电源,特别是当你需要连很多GPU并且可能运行很长时间的时候,原因你懂的。
再举个例子吧,如果以满功率(1000-1500瓦)运行4 GPU系统、花两周时间训练一个卷积神经网络,需要耗用300-500度电。按德国每度0.2欧元计算,电费最终耗费约折合人民币455-766元。
如果电源效率降到80%,电费将增加140-203元人民币。
需要的GPU数量越多,拉开的差距越明显。PSU的挑选是不是比之前想象的复杂一点?
CPU和GPU的冷却
对于产热大户CPU和GPU来说,散热性不好会降低它们的性能。
对CPU来说,则标配的散热器,或者AIO水冷散热器都是不错的选择。
但GPU该用哪种散热方案,却是个复杂的事。
风冷散热
如果只有单个GPU,风冷是安全可靠的,但若你GPU多达3-4个,靠空气冷却可能就不能满足需求了。
目前的GPU会在运行算法时将速度提升到最大,所以功耗也达到最大值,一旦温度超过80℃,很有可能降低速度,无法实现最佳性能。
对于深度学习任务来说这种现象更常见了,一般的散热风扇远达不到所需效果,运行几秒钟就达到温度阈值了。如果是用多个GPU,性能可能会降低10%~25%。

怎么办?目前,英伟达GPU很多是针对游戏设计的,所以对于Windows系统进行了专门的优化,也可以轻松设置风扇方案。
但在Linux系统中这招就不能用了,麻烦的是,很多深度学习库也都是针对Linux编写的。
这是一个问题,但也不是无解。
在Linux系统中,你可以进行Xorg服务器的配置,选择“coolbits”选项,这对于单个GPU还是很奏效。
若你有多个GPU, 就必须模拟一个监视器,Tim小哥说自己尝试了很长时间,但还是没有什么改进。
如果你想在空气冷却的环境中运行3-4个小时,则最应该注意风扇的设计。
目前市场上的散热风扇原理大致有两种:鼓风式的风扇将热空气从机箱背面推出,让凉空气进来;非鼓风式的风扇是在GPU中吸入空气达到冷却效果。

所以,如果你有多个GPU彼此相邻,那么周围就没有冷空气可用了,所以这种情况,一定不要用非鼓风式的散热风扇了。
那用什么?接着往下看——
水冷散热
水冷散热虽然比风冷法成本略高,但很适用于多个GPU相邻的情况,它能hold住四个最强劲的GPU保持周身凉爽,是风冷无法企及的效果。

另外,水冷散热可以更安静地进行,如果你在公共区域运行多个GPU,水冷的优势更为凸显了。
至于大家最关心的成本问题,水冷单个GPU大概需要100美元(约690元人民币)再加一些额外的前期成本(大约350元人民币)。

除了财力准备,还需要你投入一些精力,比如额外花时间组装计算机等。这类事情网上教程已经很多了,只需要几个小时搞定,后期的维护也不复杂。
结论
对于单个GPU,风冷便宜也够用;多个GPU情况下,鼓风式的空气冷却比较便宜,可能会带来10%~15%的性能损失。如果想追求散热极致,水冷散热安静且效果最好。
所以,风冷or水冷都合理,看你自己的实际情况和预算了。但小哥最后建议,通常情况下,还是考虑下低成本的风冷吧。
主板
主板应该有足够的PCIe插槽来支持所需的GPU数量。但需要注意的是,大多数显卡宽度需要占用两个PCIe插槽。
【PCIe插槽】
如果打算使用多个GPU,就要购买PCIe插槽之间有足够空间的主板,确保显卡之间不会相互遮挡。
机箱
选机箱的时候,必须保证机箱能装下主板顶部的全长GPU,虽然大部分机箱是没问题的,但是万一你买小了,那就得看商家给不给你七天无理由了……
所以,买之前最好确认一下机箱的尺寸规格,也可以搜一下机箱装着GPU的图,有别人的成品图的话就能买得放心一些。
另外,如果你想用定制水冷的话,保证你的机箱能装得下散热器,尤其是给GPU用定制水冷的时候,每个GPU的散热器都需要占空间。
显示器
怎么配显示器还用教?
必须得教。
Tim放出了买家秀:
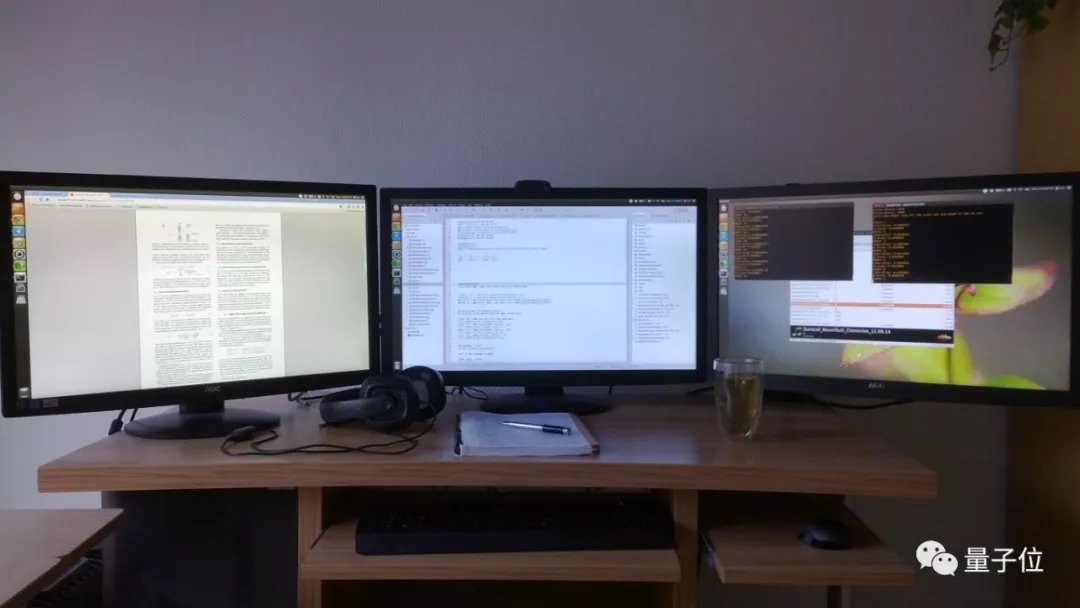
是的,作为一个成熟的技术人员,用多台显示器是基本配置了。
想象一下把买家秀上这三台显示器上的内容堆到同一块屏幕里,来回切换窗口,这得多累人。
发了三篇顶会的博士在读小哥哥
这篇指南的作者Tim Dettmers去年硕士毕业,目前在华盛顿大学读博,主要研究知识表达、问答系统和常识推理,曾在UCL机器学习组和微软实习。

按照去年毕业开始读博的话,Tim的博士才读了一年半,现在就已经是三篇顶会论文的作者了,其中还有一篇AAAI是一作,一篇ICLR是唯一作者。
另外,他还是一个刷Kaggle爱好者,曾经在2013年排到全球第63名(前0.22%)。
One More Thing
其实说了这么多,你也不想装机对不对?
Tim已然料到,所以,在装机指南之外,他还主动奉献了一些装机鼓励:
虽然买硬件很贵,一不小心搞错会肉疼,但是不要怕装电脑这件事。
其一,装机本身很简单,主板手册里都把如何装机写的明明白白,比装乐高难不了多少,还附带了大量的指南和分步操作视频,就算你是0经验小白也能学得会。
其二,装机这件事,只要有第一次,后面就不难了,因为所有的计算机都是那几个硬件构成的。所以,只要装一次,就可以get一门终身技能,投资回报率非常高。
所以,加油准备一台你自己的设备吧~

传送门
原文:
A Full Hardware Guide to Deep Learning
http://timdettmers.com/2018/12/16/deep-learning-hardware-guide/
作者推荐,数码博主Linus Tech Tips解答疑问:高频率内存对性能提升有用吗?(B站官方中文版):
https://www.bilibili.com/video/av14528439
— 完 —
量子位 · QbitAI
վ’ᴗ’ ի 追踪AI技术和产品新动态
欢迎大家关注我们,以及订阅我们的知乎专栏



