索尼大法好,224秒在ImageNet上搞定ResNet-50
机器之心编辑部,参与:刘晓坤、王淑婷、张倩。
随着技术、算力的发展,在 ImageNet 上训练 ResNet-50 的速度被不断刷新。2018 年 7 月,腾讯机智机器学习平台团队在 ImageNet 数据集上仅用 6.6 分钟就训练好 ResNet-50,创造了 AI 训练世界纪录。如今,这一纪录再次被索尼刷新……
随着数据集和深度学习模型的规模持续增长,训练模型所需的时间也不断增加,大规模分布式深度学习结合数据并行化是大幅减少训练时间的明智选择。然而,在大规模 GPU 集群上的分布式深度学习存在两大技术难题。第一大难题是大批量训练下的收敛准确率下降;第二大难题是在 GPU 之间进行梯度同步时的信息交流成本。我们需要一种解决这两大难题的分布式处理新方法。
在过去的几年里,研究者们为这两大问题提出了很多解决方法。他们使用 ImageNet/ResNet-50(在 ImageNet 数据集上训练 ResNet-50 分类器)作为训练性能的基准。ImageNet 和 ResNet-50 是最流行的用作大规模分布式深度学习基准的数据集和深度神经网络之一。表 1 对比了近期研究的训练时间和 top-1 验证准确率。
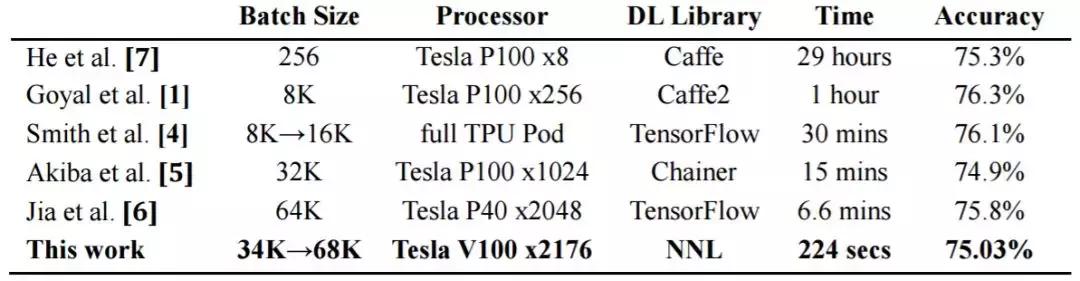
表 1:ImageNet/ResNet-50 训练时间和 top-1 1-crop 验证准确率。
从表中可以看出,随着技术、算力的发展,在 ImageNet 上训练 ResNet-50 的速度被不断刷新。日本 Perferred Network 公司的 Chainer 团队曾在 15 分钟训练好 ResNet-50;2018 年 7 月,腾讯机智机器学习平台团队在 ImageNet 数据集上,仅用 6.6 分钟就可以训练好 ResNet-50,创造了 AI 训练世界新纪录。这一次,训练记录被再一次刷新。
本文作者着眼于大批量训练的不稳定性和梯度同步成本问题,成功地使用 2176 块 Tesla V100 GPU 将训练时间减少到 224 秒,并达到 75.03% 的验证准确率。研究者还尝试在不显著降低准确率的前提下提升 GPU 扩展效率。如表 2 所示,他们最终使用 1088 块 Tesla V100 GPU 实现了 91.62% 的 GPU 扩展效率。

表 2:ImageNet/ResNet-50 训练的 GPU 扩展效率。
论文:ImageNet/ResNet-50 Training in 224 Seconds

论文地址:https://arxiv.org/ftp/arxiv/papers/1811/1811.05233.pdf
摘要:由于大规模批量训练的不稳定性和梯度同步的开销,将分布式深度学习扩展至 GPU 集群级颇具挑战。我们通过批量控制来解决大规模批量训练不稳定的问题,用 2D-Torus all-reduce 来解决梯度同步的开销。具体来说,2D-Torus all-reduce 将 GPU 排列在逻辑 2D 网格中,并在不同方向上执行一系列集群计算。这两种技术是用神经网络库(NNL)实现的。我们在 224 秒内成功训练了 ImageNet/ResNet-50,并且在 ABCI 集群上没有显著的准确性损失。
方法
我们采用了 [4], [10] 和 [11] 中引入的批量控制技术来解决大规模批量不稳定的问题。我们开发了一个 2D-Torus all-reduce 方案来有效交换 GPU 上的梯度。
批量控制
根据之前的研究,在训练期间通过逐渐增加批量的总规模可以减少大批量训练的不稳定性。随着训练损失曲面变得「平坦」,增加批量有助于避开局部最小值 [4] [10] [11]。在本文中,我们采用了批量控制的方法来减少批量超过 32K 时的准确率下降。训练期间采用预定的批量变化方案。
2D-Torus All- reduce
高效的交流拓扑对于减少集群计算的交流成本而言非常重要。人们已经提出了包括 Ring all-reduce[12] 和层级 Ring all-reduce[6] 等多种交流拓扑来提高 all-reduce 计算的效率。Ring all-reduce 算法不能完全利用超过 1000 块 GPU 的极大规模集群的带宽。这是因为 [12] 中展示的网络延迟的存在,使得算法的交流成本和 GPU 的数量成正比。我们开发了 2D-Torus all-reduce 来解决这个问题。
2D-Torus 拓扑如图 1 所示。集群中的 GPU 按照 2D 网格排列。在 2D-Torus 拓扑中,all-reduce 包含三个步骤:reduce-scatter、all-reduce、all-gather。图 2 展示了 2D-Torus all-reduce 的案例。首先,水平地执行 reduce-scatter。然后,竖直地执行 all-reduce。最后,水平地执行 all-together。
2D-Torus all-reduce 的交流成本比 Ring all-reduce 的更低。设 N 为集群中的 GPU 数量,X 为水平方向的 GPU 数量,Y 为竖直方向的 GPU 数量。2D-Torus all-reduce 只需执行 2(X-1) 次 GPU-to-GPU 运算。相比而言,Ring all-reduce 需要执行 2(N-1) 次 GPU-to-GPU 运算。尽管层级 Ring all-reduce 执行的 GPU-to-GPU 运算次数和 2D-Torus all-reduce 相同,2D-Torus all-reduce 方案的第二步的数据量只有层级 all-reduce 的 1/X。
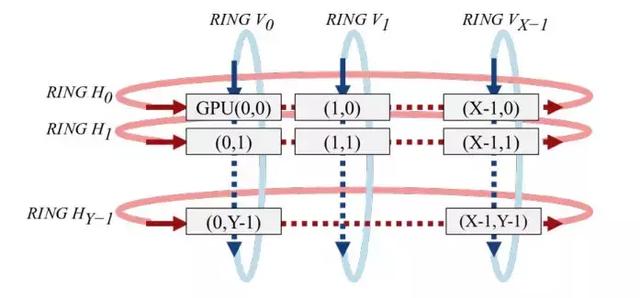
图 1:2D-Torus 拓扑由水平和竖直方向上的多个闭圈构成。
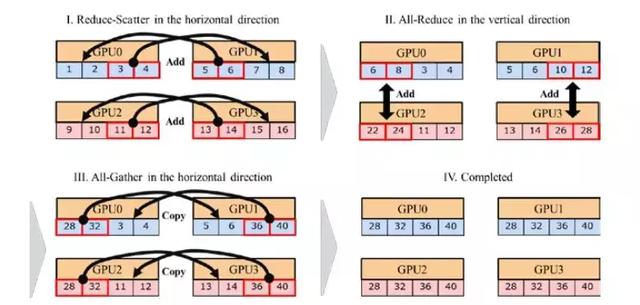
图 2: 4-GPU 集群的 2D-Torus all-reduce 计算步骤。
评估结果
我们在 224 秒内完成了 ResNet-50 的训练,并且准确率没有显著降低,如表 5 所示。训练误差曲线和参考曲线很相似(图 3)。尽管最大批量可以增加到 119K 而不会有明显的准确率降低,进一步增加最大批量到 136K 会减少 0.5% 的准确率(表 5 中的 Exp. 6)。表 6 展示了当每块 GPU 的批量被设为 32 的时候,使用的 GPU 数量和训练吞吐量。
尽管当我们使用超过 2176 块 GPU 时,GPU 扩展效率降低了 50% 到 70%,但在使用 1088 块 GPU 时 GPU 扩展效率也能超过 90%。过去的研究 [6] 报告称当使用 1024 块 Tesla P40 并且将批量设为 32 时,GPU 扩展效率达到了 87.9%。对比过去的研究,我们的 GPU 交流方案可以使用更快和更多的 GPU(Tesla V100)达到更高的 GPU 扩展效率。
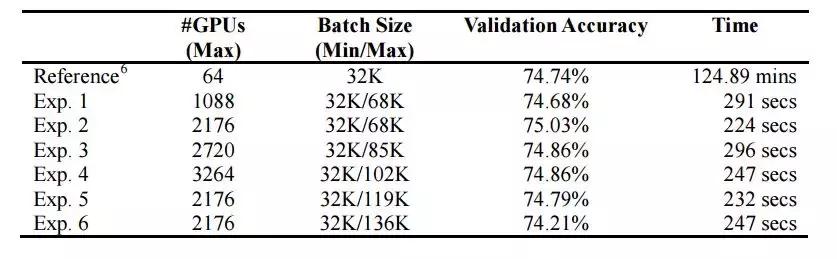
表 5:Top-1 1-crop 验证准确率和训练时间
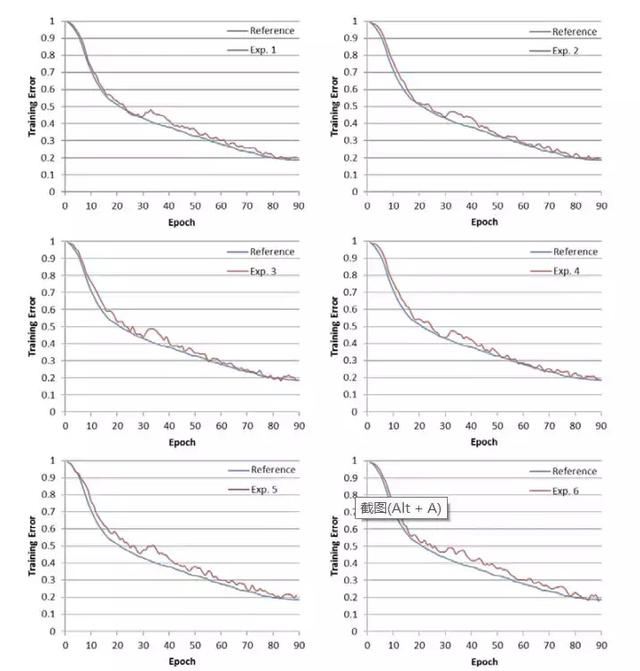
图 3:训练误差曲线
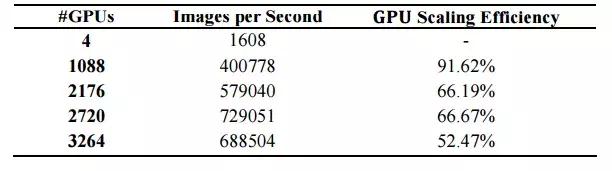
表 6:2D-Torus all-reduce 的训练吞吐量和扩展效率
讨论
分布式深度学习的瓶颈
从过去在 ImageNet 上的大规模分布式研究来看,基本上都将工作重点放在减少通信成本上。
深度学习的分布式训练分为同步和异步两种,它们的主要区别在于参数在各个 GPU(工作器)上的计算是否独立。
具体来说,异步式训练在初始化时在每个 GPU 上有一个相同的模型,然后每个 GPU 接收不同的样本进行训练。各个 GPU 在一个批量训练完成时会将参数更新到一个公有的服务器,但这个服务器仅保留一个模型参数版本。当其它工作器训练完一个批量时,会直接在公有服务器上用新的模型参数覆盖。
这种训练方式的通信成本较低,并且独立工作的方式可以在时间协调上更加灵活,但也存在问题。由于「参数覆盖」,这些 GPU 之间就像是在互相竞争,看看谁先完成训练,就能成为下一次更新的初始参数。而更新了之后,有些 GPU 还在之前的参数上进行更新,这就导致了每个 GPU 无法获取完整的梯度信息,从而其更新方向不一定是朝着收敛的方向进行。也就是说,GPU 通信的不足导致了模型更新的梯度信息不足。
同步式训练可以克服异步式训练的这个缺点。同步式训练就是在每一次更新模型参数前,先对所有的 GPU 计算出的梯度求平均。如此就能保证每个 GPU 获取相同的梯度信息,但这需要等待所有的 GPU 完成训练才行。所以很自然,这种训练方式的一大缺点就是通信成本大和延迟问题。经典的 all reduce 方案的通信成本与 GPU 的数量成正比。

all reduce 通信方案:所有 GPU 与单个 reducer GPU 之间的数据传输。
为了降低 all reduce 通信方案的成本,百度研究院提出了 Ring all reduce 通信方案,将 GPU 连接成一个圆环,进行参数信息传递,这种通信方式可以有效减少通信成本。在理想情况下,这种通信方案的成本是和 GPU 数量无关的。至于本文研究者提到的 Ring all reduce 存在的网络延迟问题,这里就不讨论了。简单来说,Ring all reduce 将通信分成两个阶段,在第一个阶段中可以先将传递过来的部分参数值进行合并,然后在每个 GPU 中都有部分的最终合并参数值,并在第二个阶段中再次进行传递。
Ring all reduce 通信方案:被布置在逻辑环中的 GPU,与近邻的 GPU 接收和发送参数值。
和 all reduce 方案对比一下,我们可以发现,Ring all reduce 就是将单阶段通信变成了多阶段,每个阶段可以先合并部分参数值,这样参数数量就会在每个阶段不断缩减。也就是说,对于同类的可合并的数值通信而言,分层通信才是根本。如此,我们也不难理解腾讯之后提出的层级 all reduce 的思想了。
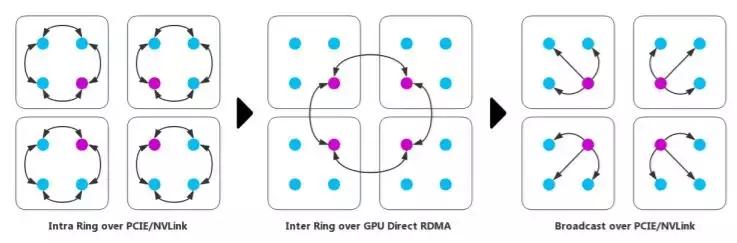
层级 all reduce 的三阶段通信方案图示。
根据论文方法部分的解释,2D-Torus All- reduce 的通信拓扑比 Ring all reduce 多一个维度,并且和层级 all reduce 的通信次数相同,但在第二个步骤的通信数据量更小。2D-Torus All- reduce 将通信过程分成多个维度和多个阶段进行,经过了两个阶段的合并之后在每个 GPU 都有部分的最终参数值,和层级 all reduce 有着异曲同工之妙。至于更细节的过程,其实论文中也没说。
之后的研究可能会在什么方向?可能的变量还是很多的,无论是 GPU 性能增长,通信带宽成本的降低,还是 GPU 集群拓扑的新方案……
竟然花费那么大成本来训练 ImageNet?
首先,完成这种训练的成本到底有多大?我们可以参考 Reddit 上网友的粗略计算:Tesla V100 大约是单价 6000 美元,训练最快的结果中使用了 2176 块 V100,总价约 1300 万美元。你可能觉得这对于索尼大法而言不算什么,但考虑到维护成本和占地,这就很不经济了。当然,索尼也可能像迪士尼一样利用这些 GPU 来渲染动画(游戏)。
另外也有网友计算了一下租用谷歌云 Tesla V100 的训练成本,总价约:
2176GPU * $0.74/GPU·hr * 1hr/3600s * 224s ≈ $100
100 美元…Unbelievable~小伙伴们,有空跑一个?
索尼大法好,224秒在ImageNet上搞定ResNet-50http://t.jinritoutiao.js.cn/RqgpqU/



